More on Parametric and Nonparametric Population Modeling a



 • Get the entire ML distribution, a Discrete. Joint Density:")
 • The multiple models permit multiple predictions. • Can predict")




 so, IIV")




 • Initiate by solving the ML problem")
 MEMORY (MB)")
 = e-Kt/V with")
 points, correlation = +0. 6")

")
")
")
")







- Slides: 31
More on Parametric and Nonparametric Population Modeling: a brief Summary Roger Jelliffe, M. D. USC Lab of Applied Pharmacokinetics See also Clin PK, Bustad A, Terziivanov D, Leary R, Port R, Schumitzky A, and Jelliffe R: Parametric and Nonparametric Population Methods: Their Comparative Performance in Analysing a Clinical Data Set and Two Monte Carlo Simulation Studies. Clin. Pharmacokinet. , 45: 365 -383, 2006.
In. TER-Individual Variability • The variability between subjects in a population. • Usually a single number (SD, CV%) in parametric population models • But there may be specific subpopulation groups • eg, fast, slow metabolizers, etc. • How describe all this with one number? • What will you DO with it?
In. TRA-Individual Variability • • The variability within an individual subject. Assay error pattern, plus Errors in Recording times of samples Errors in Dosage Amounts given Errors in Recording Dosage times Structural Model Mis-specification Unrecognized changes in parameter values during data analysis. • How describe all this with one number? • How describe interoccasional variability only with one number? • What will you DO with these numbers?
Nonparametric Population Models (1) • Get the entire ML distribution, a Discrete. Joint Density: one param set per subject, + its prob. • Shape of distribution not determined by some equation, only by the data itself. • Multiple indiv models, up to one per subject. • Can discover, locate, unsuspected subpopulations. • Get F from intermixed IV+PO dosage.
Nonparametric Population Models (2) • The multiple models permit multiple predictions. • Can predict precision of goal achievement by a dosage regimen. • Behavior is consistent. • Use IIV +/or assay SD, stated ranges.
What is the IDEAL Pop Model? • The correct structural PK/PD Model. • The collection of each subject’s exactly known parameter values for that model. • Therefore, multiple individual models, one for each subject. • Usual statistical summaries can also be obtained, but usually will lose info. • How best approach this ideal? NP!
NPEM can find sub-populations that can be missed by parametric techniques True two-parameter density Smoothed empirical density of 20 samples from true density
NPEM vs. parametric methods, cont’d Best parametric representation using normality assumption Smoothed NPEM results
The Clinical Population - 17 patients, 1000 mg Amikacin IM qd for 6 days • Seventeen patients • 1000 mg Amikacin IM qd for 5 doses • 8 -10 levels per patient, usually 4 -5 on day 1 -2, and 4 -5 on day 5 -6, • Microbiological assay, • SD = 0. 12834 + 0. 045645 x Conc • Ccr range - 40 -80 ml/min/1. 73 M 2
Getting the Intra-individual variability IIV = Gamma x (assay error SD polynomial) so, IIV = Gamma x (0. 12834 + 0. 045645 x Conc) Gamma = 3. 7
Amikacin - Parameterization as Ka, Vs, and Ks IT 2 B NPEM NPAG With Med/CV% Ka 1. 352/4. 55 1. 363/20. 42 1. 333/21. 24 Vs . 2591/13. 86 . 2488/17. 44 . 2537/17. 38 Ks. 003273/14. 83. 003371/15. 53 . 003183/15. 76
Amikacin - Log Likelihood, Ka, Vs, and Ks, with and without gamma IT 2 B NPEM NPAG -809. 996 -755. 111 -748. 295 -389. 548 -374. 790 -374. 326 No Log - Lik With Log - Lik
Estimates from Pop Medians, Ka, Vs, Ks parameterization, no / • IT 2 B NPEM NPAG • r 2 =. 814/. 814. 876/. 879. 877/. 880 • ME =. 979/-. 575 -. 584/-. 751 -0. 367/. 169 • MSE = 55. 47/48. 69 28. 96/29. 01 29. 06/29. 70
Conclusions All parameter values pretty similar Less variation seen with IT 2 B But log likelihood the least NPEM, NPAG more likely param distribs No spuriously high param correlations NPAG most likely param distributions NPEM, NPAG best suited for MM dosage NPEM, NPAG are consistent, precise.
New - Non-parametric adaptive grid algorithm (NPAG) • Initiate by solving the ML problem on a small grid • Refine the grid around the solution by adding perturbations in each coordinate at each support point from optimal solution at previous stage • Solve the ML problem on the refined grid (this is a small but numerically sensitive problem) • Iterate solve-refine-solve cycle until convergence, using decreasing perturbations • Best of both worlds - improved solution quality with far less computational effort!
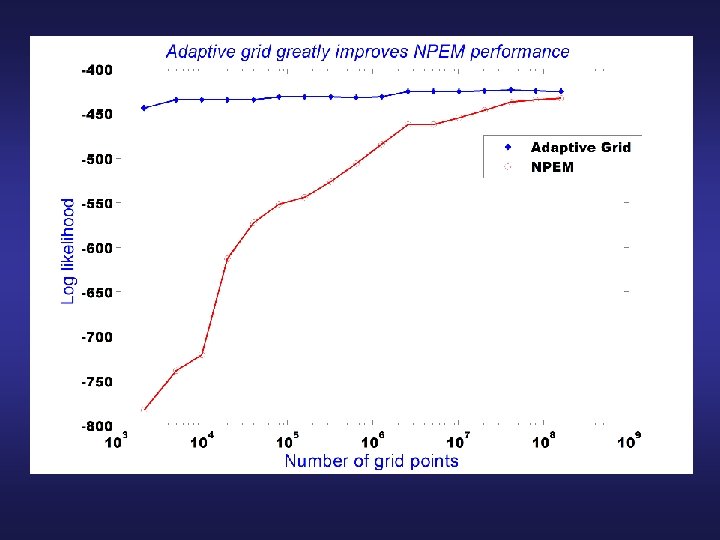
NPAG outperforms NPEM by a large factor NPEM: NPAG: CPU TIME (HRS) MEMORY (MB) 2037 1. 7 10000 6 LOG-LIK -433. 1 -433. 0 NPEM run was made at SDSC on 256 processors of Blue Horizon, an IBM SP parallel supercomputer that was then the most powerful non-classified computer in the world NPAG run was made on a single 833 MHz Dell PC
Leary – A Simulation Study • One compartment model h(V, K) = e-Kt/V with unit intravenous bolus dose at t=0 • Five parameters in N(m, S): m. V=1. 1, m. K=1. 0 s. V=0. 25, s. K =0. 25, r= – 0. 6, 0. 0, and +0. 6 • 1000+ replications to evaluate bias and efficiency • N=25, 50, 100, 200, 400, 800 sample sizes • Two levels (moderately data poor) with 10% observational error
800 Normally distributed (K, V) points, correlation = +0. 6
800 normal points give 70 NPAG support points
NPAG and P-EM are consistent (true value of m. V = 1. 1)
Consistency of estimators of m. K (true value of m. K = 1. 0)
Consistency of estimators of s. K (true value of s. K=0. 25)
Consistency of estimators of V-K correlation coefficient (true value r = -0. 6)
Consequence #1 of using F. O. C. E approximation– loss of consistency • small (1 -2%) bias for m. V, m. K • moderate (20 – 30%) bias for s. V, s. K • severe bias for correlations true value average estimate -0. 6 +0. 2 0. 0 +0. 6 +0. 85
Statistical efficiencies of NPAG and PEM are much higher than IT 2 B
Asymptotic stochastic convergence rate of IT 2 B is 1/N 1/4 vs. 1/N 1/2 for NPAG and P-EM
Approximate likelihoods can destroy statistical efficiency
NONMEM FOCE does better, but still has less than 40% efficiency relative to exact ML methods
Consequences of using F. O. and F. O. C. E approximations versus exact likelihoods • Loss of consistency • Severe loss of statistical efficiency • Severe reduction of asymptotic convergence rate : • need 16 X the number of subjects to reduce the SD of IT 2 B estimator by factor of 2, • vs. 4 X for NPAG and PEM, as theory says
Efficiency and Relative Error • • Estimator Rel Efficiency Direct observation 100. 0% PEM 75. 4% NPAG 61. 4% NONMEM FOCE 29. 0% IT 2 B FOCE 25. 3% NONMEM FO 0. 9% Rel Error 1. 00 1. 33 1. 63 3. 45 3. 95 111. 11