Hey You Get Off My Cloud Exploring information























- Slides: 25
Hey You, Get Off My Cloud: Exploring information Leakage in third party compute clouds T. Ristenpart, Eran Tromer, Hovav Shacham and Steven Savage ACM CCS 09 Presented by Shameek Bhattacharjee Fall 2011, Oct 27 th
Introduction • • • Is it possible to identify where a target VM is likely to reside ? How can you extract information from a target instance ? Is there a way to place your attacker instance co resident with a target victim. Recipe of Information Leakage • Stage 1: Map the internal cloud infrastructure. • Stage 2: Identify where a target VM is likely to reside. • Stage 3: Instantiate new VMs until one is placed co – resident with the target. (place) • Stage 4: Mount cross VM side channel attack from a target VM on a same physical machine. (extract)
Current cloud infrastructure • At the time of writing the paper: - 3 availability zones. - 5 types of instance. • Each instance is given connectivity through External IPv 4 address , domain name, internal private address and domain name. Within cloud both domain name resolves to internal IP, outside the external name is mapped to external IP.
Network Probing • Identify public servers and co residence. • Tools: – nmap : Perform TCP connection probes 3 way handshaking between source and target. – hping : TCP SYN trace routes , sends TCP SYN with increasing TTL. – wget: To retrieve web pages, 1024 bytes max is retrieved from each web server. – External probes: Originates outside EC 2 with a destination instance inside EC 2. – Internal probe: Originates inside EC 2 with a destination instance inside EC 2. – DNS resolution queries: To determine the external name of an instance and internal IP of an instance.
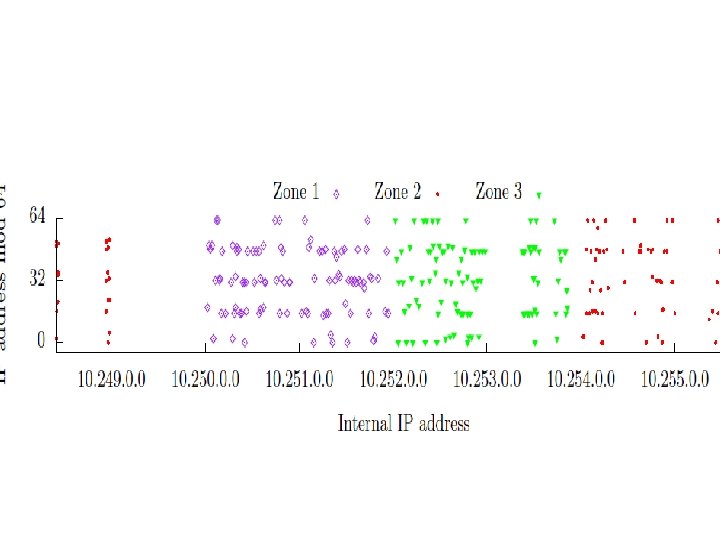
Mapping the address space of EC 2 cloud: Cloud cartography • • To know where the potential target is located. Instance creation parameters needed to achieve co residence. Hypothesis : Different availability zones likely to have different internal IP address range and is true for instance types. Algorithm: helps - Label /24 prefixes with an estimate of availability zone and instance types of included Internal IP. - Features of EC 2 addressing regime. Output : Map of internal EC 2 address space that allows estimation of zone and type of a target ec 2 server.
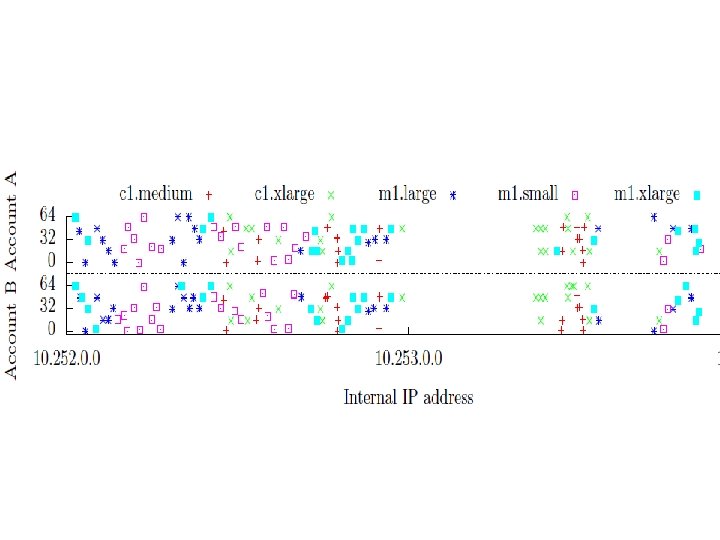
Findings from cloud cartography • • Keep on doing WHOIS queries for responsive hosts through different tools and ports and using DNS resolution queries. 4 distinct IP prefixes seen. TCP connect probe used to get responsive IPs. DNS lookup from within EC 2 and translate each public IP to an internal EC 2 address. Experiment : • Launch 20 instances each for 15 zone/instance type pair. Observations: • The internal IP address space is partitioned between 3 zones. • Samples from each zone are assigned IP addresses from disjoint portions of observed address space. • Availability zones use separate physical structures. • Instance types within a zones show regularity.
Another experiment on instance types and accounts Instance types and accounts : There are 100 instances launched from each account A & B with a gap of 39 hrs. • All IPs from a /16 are from the same availability zone. • A /24 inherits any included sampled instance type. If there are multiple instances with distinct types, then we label the /24 with each distinct type (i. e. , it is ambiguous). • A /24 containing a Dom 0 IP address only contains Dom 0 IP addresses. We associate to this /24 the type of the Dom 0’s associated instance. • All /24’s between two consecutive Dom 0 /24’s inherit the former’s associated type. • No IP address was ever observed to have being assigned more than one instance type. • Basically DOM 0 are assigned a prefix that immediately precedes the instance IPs they are associated with. E. g. 10. 250. 8. 0/24 contain Dom 0 associated with instances in prefix 10. 254. 9. 0/24 and 10. 254. 10. 0/24. • • Local IPs statically associate to availability zones changing it makes admin tasks difficult. Can use VLAN AND BRIDGING to make it fuzzy. But you can triangulate victim by ping timing trace routes.
Determining co residence • COMPARE each instance’s DOM 0 IP. Instances are likely co-resident if : - Check 1 : matching Dom 0 IP address, - Check 2: small packet round-trip times, or - Check: numerically close internal IP addresses – makes use of the manner in which it appears that internal IP is assigned in EC 2. verifying the Dom 0 of your own instance is : Dom 0 is the first hop of your instance – for any route out. For any instance not under control , Do TCP SYN trace route to it and inspecting the last hop. Then match. • • Same Dom 0 will be shared by instances with a contiguous sequence of internal IPs.
Experiment • • • 3 accounts – one victim, control, probe. Victim + Probe under control 2 instance from control account, and in each of 3 zones 20 instances in victim account 20 in probe account. These 20, 20 form an ordered pair ( A, B) Flow : • Determine Dom 0 IP of each instance. • If the pair passed check 1 for A will probe B and each of 2 controls for RTT check and sent a 5 bit message over covert channel. • 3 independent trials Output • 31 pairs with equal DOM 0 s. • 62 ordered pairs. And the hard drive covert channel sent 5 bit messages successfully for 60 of these pairs. • The median RTT was significantly smaller than those to controls.
Example of covert channel • • If two instances has the ability send via covert channel they are co-resident. To send 1 bit, sender instance reads from random locations of a shared disk volume. To send 0, sender does nothing. The receiver times the reading from a fixed location. Longer read time means a 1 is being set. Else 0.
results • Coverage means – number of victims for which probe was co resident over total number of victims
Placement Strategies • • Brute Force Placement: launch many instances over a long period of time, success is likely for relatively large target data set. More refined Intelligent Placement: target recently launched instances. An attacker can infer when a victim instance is launched. How ? Step 1. A single account was never seen to have two instances simultaneously running on the same physical machine, so running n instances in parallel under a single account results in placement on n separate machines. Sequential Locality: exists when two instances run sequentially (the first terminated before launching the second) are often assigned to the same machine. Parallel Placement Locality: when two instances run at roughly same time from distinct accounts are often assigned same machine. There is a bias in placement on machines with fewer instances already assigned.
• • The attacker enumerates a set of potential target victims. The adversary then infers which of these targets belong to a particular availability zone and are of a particular instance type using the map from cloud address map. Then, over some (relatively long) period of time the adversary repeatedly runs probe instances in the target zone and of the target type. Each probe instance checks if it is co-resident with any of the targets. If not the instance is terminated.
How can attacker launch instances soon after the target VM is launched. • • A feature is run servers only when needed. Servers are run on instances terminated when not needed and then resumed. So an attacker can monitor server state by network probing, wait until instance disappears and when it reappears do a instance flooding running n instances in parallel. This effectively take advantage of parallel placement locality.
CROSS VM Leakage • • Time shared caches allow measure, when other user experience computational load. Robust Co residence detection Detection of rate of web traffic. Timing keystrokes of an honest user. There is a history of works related to stealing of cryptographic secrets via cache based channels. Not just data cache but any resource multiplexed between the attacker and victim forms a useful side channel, CPU branch predictors, CPU pipelines, DRAM memory bus. Used memory bus contention. Used hard disk based contention. Covert channels provide evidence that vulnerable side channels exist.
Measuring cache usage Measure the utilization of CPU cache. Estimate current load; high load indicates activity in co resident instance Done through a Prime+Trigger+Probe technique already published in [ 1 ]
Modified Probe Trigger Algorithm •
• Test co residence without network based techniques. Possible provided some knowledge of load variation on target instance is known. Adversary might cause active load variation. Due to some publicly accessible service running on target. • By observe load sample variance which makes vulnerable to other types of attacks.
What is the problem with knowing load variance • What is the problem with knowing load sample variance ? • It provide a method for estimating the number of visitors to a co-resident web server which pages are being frequented. • In many cases this information might not be public and leaking it could be damaging if, for example, the co-resident web server is operated by a corporate competitor. • Initial experimentation with estimation, via side channel measurements, of HTTP traffic rates to a co-resident web server. • It can lead to other attacks like keystroke timing attacks where load measurements may be used instead of network taps used in traditional key stroke timing. • An exp with 1000 cache load measurements with varying traffic ( https requests per minute)
Experiment on load variation leakage 1000 load measures Target web server Attacker instance 4 different traffic reques Jmeter emulates 20 users Take average of four trials
Results on measured load on target
References • • E. Tromer, D. A. Osvik, and A. Shamir, `` Efficient cache attacks on AES and countermeasures”, Journal of Cryptology, July 2009. D. A. Osvik, A. Shamir, E. Tromer, ``Cache attacks and counter measures: the case of AES”, RSA cryptographers track 2006.