HDFS Hadoop Distributed File System 100062123 100062139 101062401

HDFS Hadoop Distributed File System 100062123 柯懷貿 100062139 王建鑫 101062401 彭偉慶

Outline �Introduction �HDFS – How it works �Pros and Cons �Conclusion 柯懷貿 2

Introduction to HDFS Hadoop Distributed File System • • Cloud Computing • Allow files shared via internet • Dung • Cutting established JAVA Write-once-read-many • Nutch Project Processing • Restricting PB-Level Data access • File System for Hadoop framework Distributed • Replication Computing & Environment Fault tolerance • Remote Procedure Call logical • Mapping between • Master/Slave • HDFS • Hadoop Map. Reduce objects & physical • objects HBase • Yahoo! has accomplished 10, 000 -core Hadoop cluster in 2008 柯懷貿 3

Map. Reduce 柯懷貿 4

HBase • No. SQL • Using several servers to store PB-level data 柯懷貿 5
 • Reading efficacy")
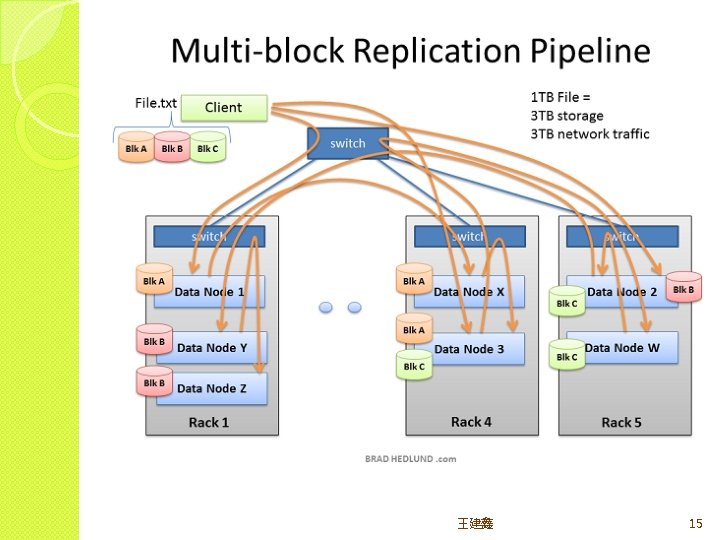
HDFS • Distributed, scalable, and portable • File replication(default : 3) • Reading efficacy 柯懷貿 6
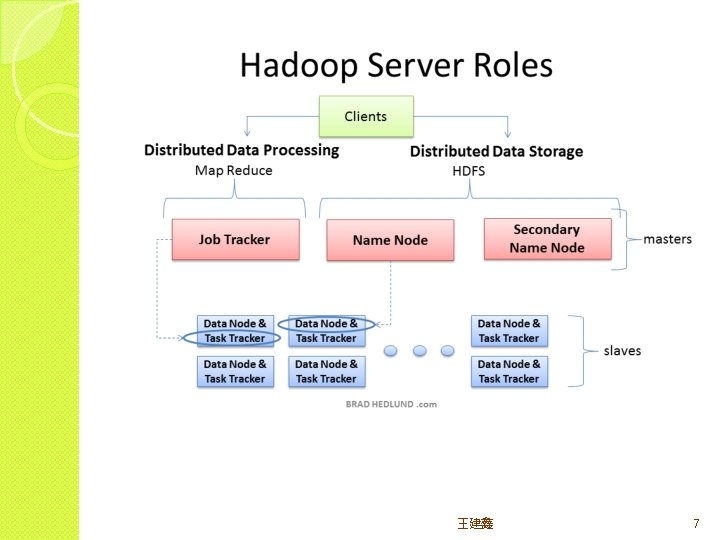
 system – read/write data from/to file �Name node(masters) – oversee")
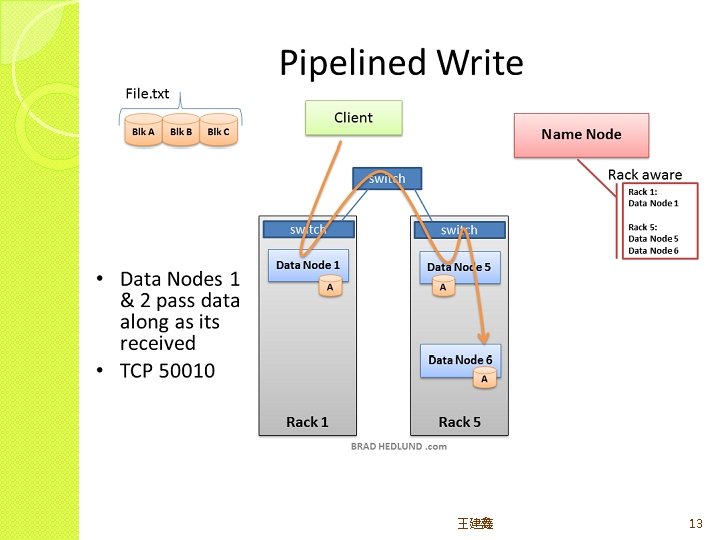
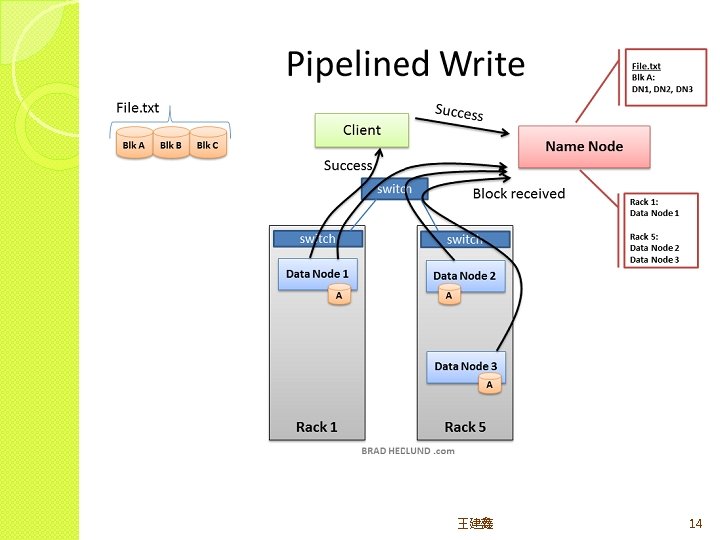
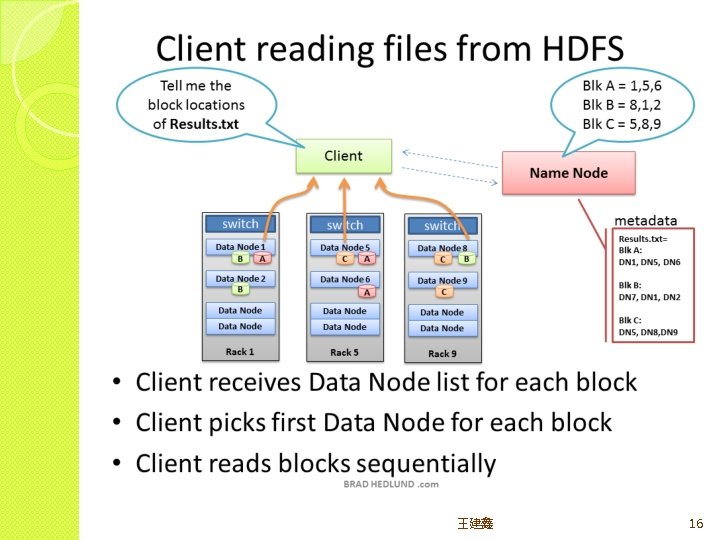
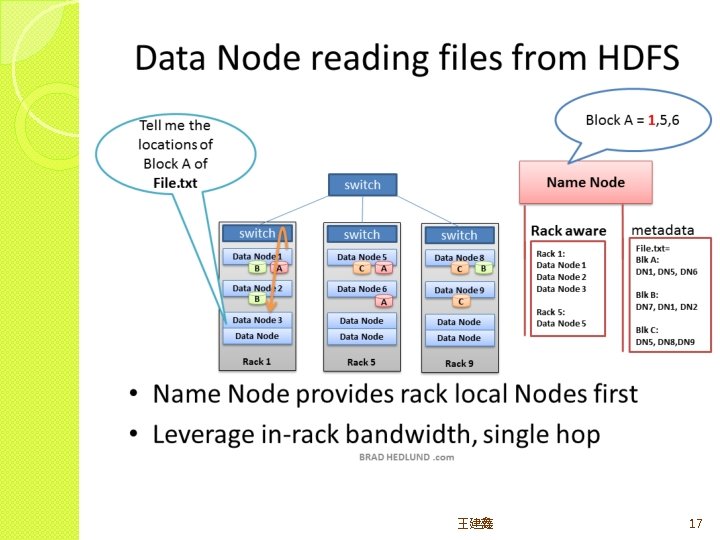
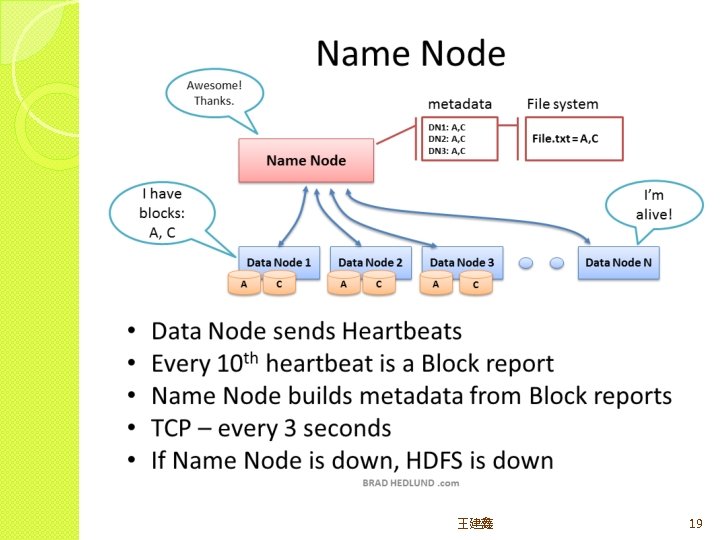
HDFS major roles �Client(user) system – read/write data from/to file �Name node(masters) – oversee and coordinate the data storage function, receive instructions from Client �Data node(slaves) – store data and run computations, receive instructions from Namenode 王建鑫 8
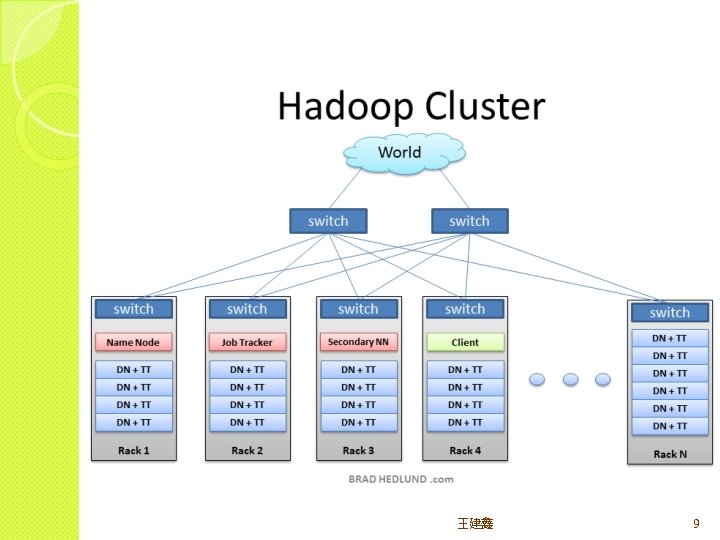
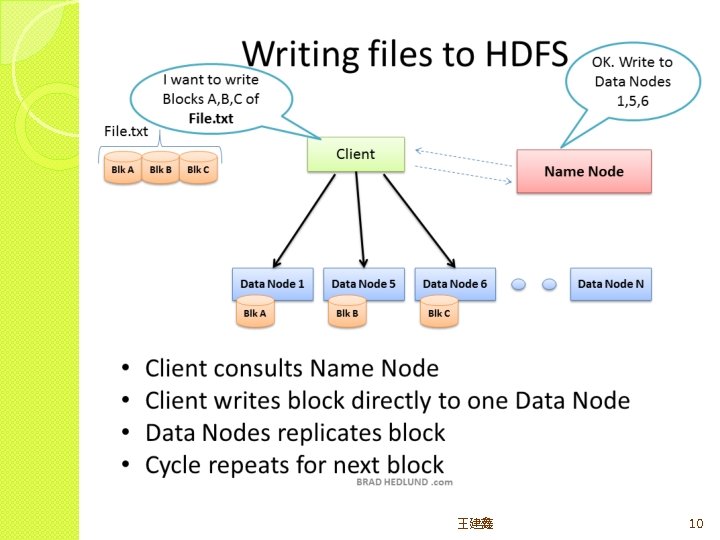

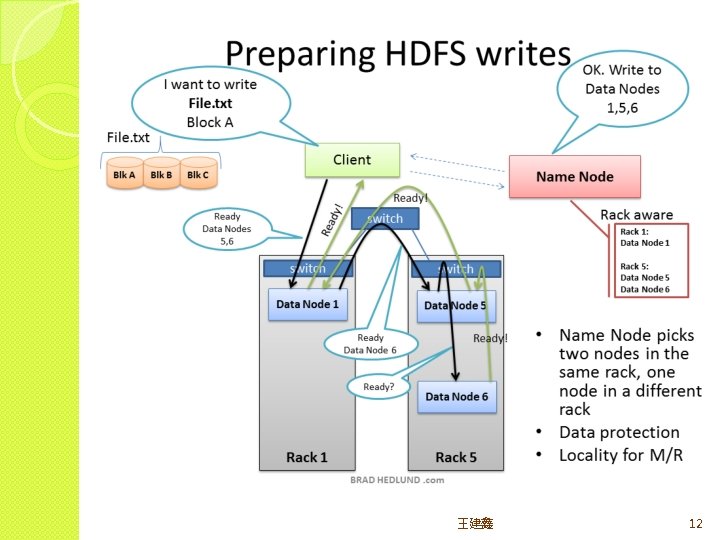
Rack Awareness 王建鑫 11

HDFS fault tolerance �Node failure – data node or nam enode is dead �Communication failure – cannot send and retrieve data �Data corruption – data corrupted while sending over network or corrupted in the hard disks �Write failure – the data node which is ready to be written is dead �Read failure - the data node which is ready to be read is dead 王建鑫 18

Detect the Network failure �Whenever data is sent, an ACK is replied by the receiver �If the ACK is not received(after several retries), the sender assumes that the host is dead, or the network has failed �Also Checksum is sent along with transmitted data→can detect corrupt data when transferring 王建鑫 20
")
Handling the write/read failure �Client write the block in smaller data units(usually 64 KB) called packet �Each data node replies back an ACK for each packet to confirm that they got the packet �If client don’t get the ACKs from some nodes, dead node detected �Client then adjust the pipeline to skip that node(then? ) �Handling node the read failure:just read another 王建鑫 21

Handling the write failure cont’d �Name �List of node contains two tables: blocks – block. A in dn 1, dn 2, dn 8; block. B in dn 3, dn 7, dn 9… �List of Data nodes – dn 1 has block. A, block. D;dn 2 has block. E, block. G… �Name node check list of blocks to see if a block is not properly replicated �If so, ask other data nodes to copy block from data nodes that have the replication. 王建鑫 22

Pros �Very large files ◦ A file size overs xxx. MB, GB, TB, PB. …. . �Streaming data access ◦ Write-once, read-many. ◦ Efficient on reading whole dataset. �Commodity hardware ◦ High reliability and availability. ◦ Doesn’t require expensive, highly reliable hardware. 彭偉慶 23

Cons 彭偉慶 24

Conclusion �HDFS - an Apache Hadoop subproject. �Highly fault-tolerant and is designed to be deployed on low-cost hardware. �High throughput but not low latency. 彭偉慶 25
- Slides: 25