Distributed Computing Apache Hadoop Hive Review Hadoop Basic
 박영택 컴퓨터 학부")
Distributed Computing (Apache Hadoop & Hive Review) 박영택 컴퓨터 학부



 ‐Hadoop Distributed File System (HDFS)")
Hadoop : Basic Concepts § File 시스템 (Data Storage) ‐Hadoop Distributed File System (HDFS) § Computation 방식 (Data Analytics) ‐Map. Reduce 프로그램



Hadoop Server roles Clients Data Storage Jobs Data Analytics Jobs HDFS Map Reduce Job Tracker Name Node Data Node & Task. Tracker Task Data Node & Task Tracker Data Node && Data Task Tracker Data Node & Task Tracker . . . Secondary Name Node Masters Data Node & Task Tracker Slaves Data Node & Task Tracker


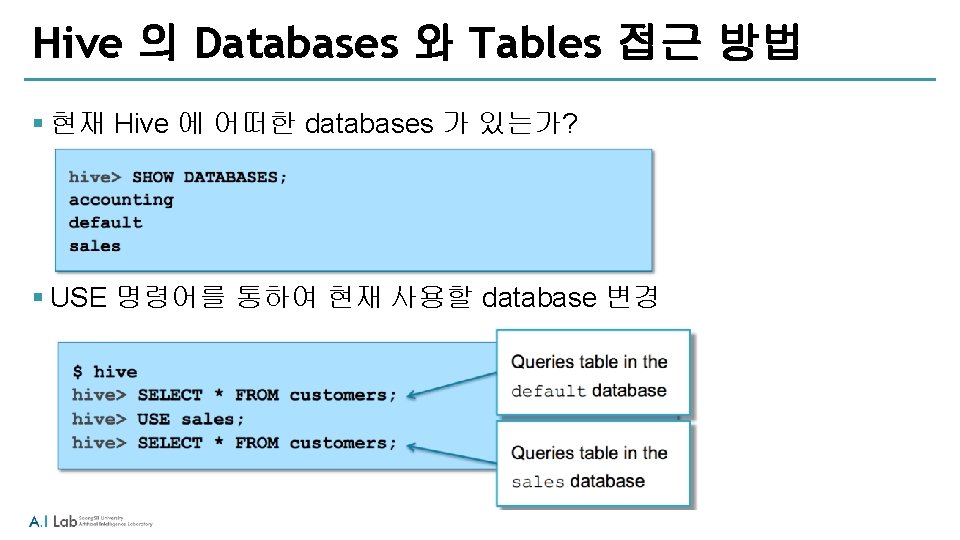
 § HDFS의 경로 /user/fred/bar. txt의 내용을 출력 § HDFS의 baz.")
hadoop fs Examples (2) § HDFS의 경로 /user/fred/bar. txt의 내용을 출력 § HDFS의 baz. txt file을 로컬 디렉토리로 복사
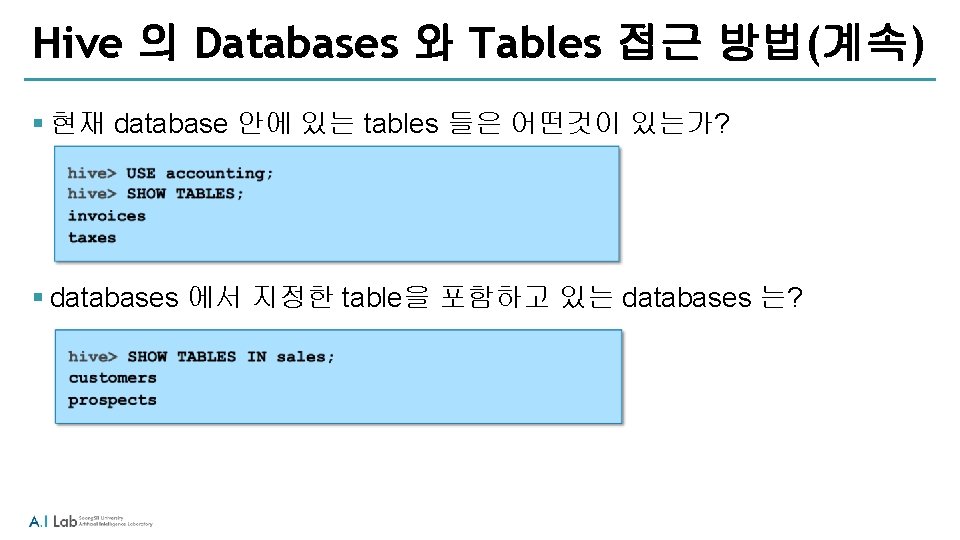
 § HDFS의 home 위치에 weblog 폴더 생성 $ hadoop fs")
hadoop fs Examples (3) § HDFS의 home 위치에 weblog 폴더 생성 $ hadoop fs –mkdir weblog § HDFS의 폴더 삭제 $ hadoop fs –rm -r weblog





리듀서 예제 : Sum Reducer § 각 중간 키 값과 관련있는 모든 값들을 합 (pseudo-code) let reduce(k, vals) = sum = 0 foreach int i in vals: sum += i emit(k, sum) (’bar', [9, 3, -17, 44]) -> (’bar’. 39) (’foo', [123, 100, 77]) -> (’foo', 300)
 let reduce(k,")
리듀서 예제 : Identity Reducer § Identity 리듀서 는 매우 흔하다. (pseudo-code) let reduce(k, vals) = foreach v in vals: emit(k, v) ('bar', [123, 100, 77]) -> ('bar', 123), ('bar', 100), ('bar', 77) ('foo', [9, 3, -17, 44]) -> ('foo', 9), ('foo', 3), ('foo', -17), ('foo', 44)

")
Hive architecture (from the paper)



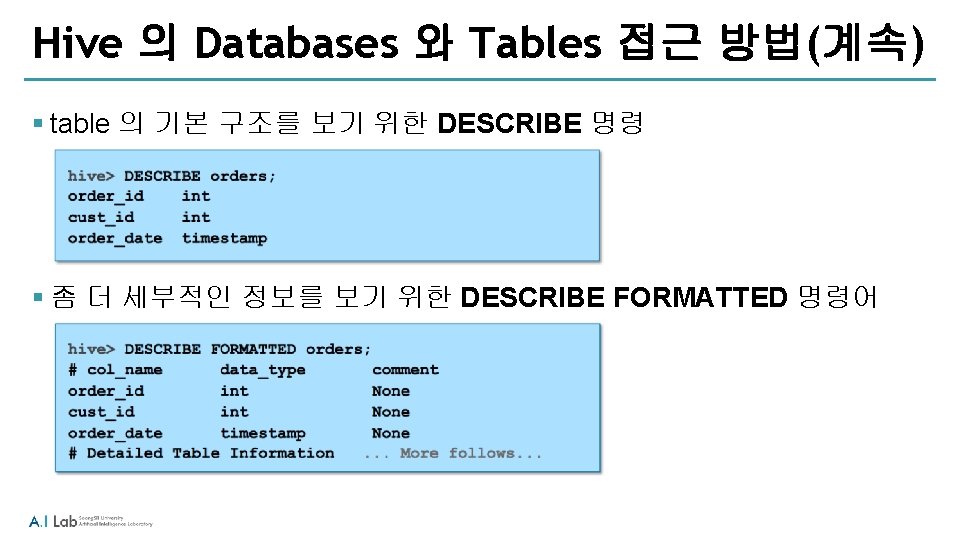

 FROM customers;")
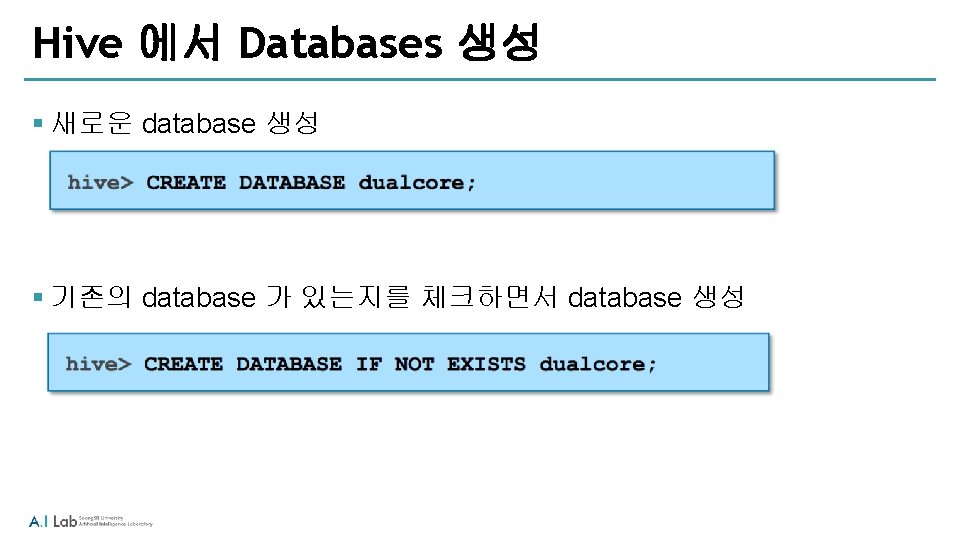
Hive의 테이블 확인 § ‘orders’ 테이블의 레코드 수 확인 hive> SELECT COUNT(*) FROM customers;

Hive의 기본 명령어 § LIMIT은 질의문 결과의 레코드 수를 제한 hive> SELECT customer_fname, customer_lname FROM customers LIMIT 10; § ORDER BY는 질의문 결과를 특정 칼럼을 기준으로 정렬 hive> SELECT customer_id, customer_fname FROM customers ORDER BY customer_id DESC LIMIT 10; § WHERE는 특정 칼럼 값에 조건을 설정 hive> SELECT * FROM orders WHERE order_id=1287; hive> SELECT * FROM customers WHERE customer_state IN (‘CA’, ‘OR’, ‘WA’, ‘NV’, ‘AZ’);

Hive에서의 Joins § Hive 에서 서로 다른 데이터간의 Join 은 빈번하게 발생 § Hive 에서 지원하는 Join 의 종류 ‐Inner joins ‐Outer joins(left, right, and full) ‐Cross joins( Hive 0. 1 이상 버전) ‐Left semi joins § equality (‘=‘) 조건은 join 에서만 허용 ‐Valid : customers. cust_id = orders. cust_id ‐Invalid : customers. cust_id <> orders. cust_id ‐Output의 각 records 는 각 table 의 지정된 key(e. g. customers. cust_id) 로 부터 찾은 데이터 § 최고의 질의응답 성능을 위해서는 가장 큰 테이블을 가장 나중에 질의하기

Hive 조인의 사용 예 § 각 고객별 주문 상황을 출력하기 위해 2개의 테이블 ‘customers’와 ‘orders’을 조인 customers Join hive> SELECT customer_lname, order_id, order_status FROM customers c JOIN orders o orders ON (c. customer_id = o. order_customer_id) LIMIT 10;

My. SQL의 데이터를 HDFS로 가져오기 § MYSQL 테이블을 HDFS 를 거쳐 Hive 테이블로 가져오기 Hive HDFS DATABASE Table Sqoop MYSQL DATABASE Table

My. SQL의 데이터를 HDFS로 가져오기 § 테이블 ‘categories’를 HDFS로 가져오기 ‐$ sqoop import --connect jdbc: mysql: //localhost/retail_db --table categories --fields-terminated-by ‘t’ --username root --password cloudera

Hive 테이블 생성 테이블 명 § 테이블 생성 칼럼 명 칼럼의 데이터 타입 hive> CREATE TABLE categories (category_id INT, category_department_id INT, category_name STRING) ROW FORMAT DELIMITED 불러올 파일의 각 라인을 하나의 레코드로 구분 FIELDS TERMINATED BY ‘ ’ 불러올 레코드를 tab으로 구분하여 칼럼에 저장

Hive 테이블에 데이터 불러오기 및 확인 $ LOAD DATA INPATH ‘categories/part-m-00000’ INTO TABLE categories; $ SELECT * FROM categories LIMIT 10;

My. SQL의 데이터를 직접 Hive로 가져오기 § MYSQL 테이블을 HDFS 를 거치지 않고 직접 Hive 테이블로 가져오기 Hive HDFS DATABASE Table Sqoop MYSQL DATABASE Table

My. SQL의 데이터를 Hive로 가져오기 § ‘retail_db’의 ‘customers’ 테이블을 Hive로 가져오기 hive> sqoop import --connect jdbc: mysql: //localhost/retail_db --username root --password cloudera --table customers --hive-database retail_db --hive-import
 § EXPLODE 함수는 array 의")
EXPLODE 를 사용하여 Array 를 Records 변환 (step #2) § EXPLODE 함수는 array 의 각 element마다 하나의 record 생성 ‐SPLIT 과 같은 함수는 table generating function 임 ‐table generating function 을 EXPLODE 의 파라매터로 사용할때는 alias 필요(e. g. AS x)

 § Hive 에서는 n-grams 를 계산하기 위한 NGRAMS 함수 제공")
HIVE 에서의 n-grams(step #2) § Hive 에서는 n-grams 를 계산하기 위한 NGRAMS 함수 제공 § NGRAMS 함수는 3개의 파라매터 필요 ‐String 타입의 Array of array 형태, 각 element는 word (e. g. [[“is”, “great”]]) ‐n-gram 에서의 n 숫자 (number of words) ‐결과 값의 출력 개수(top-N, based on frequency) § Output은 2개의 속성을 가진 STRUCT 구조의 array 리턴 ‐ngram : n-gram 자체 값(an array of words) ‐estfrequency : n-gram 의 각 값이 몇번 나타났는지에 대한 count 값
 § HIVE 의 SENTENCES 함수는 sentences 를 array")
Sentences 를 Words 로 변경(step #2) § HIVE 의 SENTENCES 함수는 sentences 를 array of words 로 변환 § Input 값은 하나 이상의 sentences 가 될 수 있음 § 2개의 Sentences 를 Input 값으로 받을 경우, 2 -dimensional 로 변환

- Slides: 44