Deep learning huge contextual bandit models Students Gal

Deep learning huge contextual bandit models Students: Gal Paikin, Nir Bachrach Supervisor: Amir Kantor

Team • Gal Paikin – A student in his final year in Bsc Computer Science • Nir Bachrach – A student in his third year, in BSc Computer Science and Mathematics.

Goals • Learn about the contextual bandit problem. • Implement and test an algorithm to address the cold-start problem in contextual bandits, and particularly the problem of overfitting small data. • Test the following hypothesis: Is there a correlation between the size of the dataset, and the layer size? • Learn about Docker for the testing of the hypothesis and the coldstart problem on the IBM server.

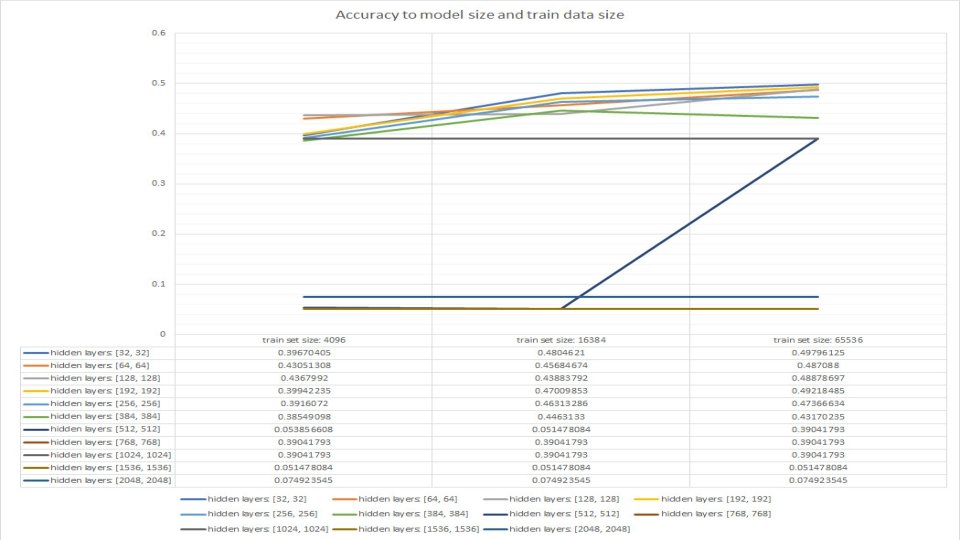
Methodology • We started by conducting a research about the methods which we will test our hypothesis. • We used the standard way of transforming a supervised learning dataset into a bandit problem. • The experiments at first measured model accuracy as the data accumulated. • Later on, we couldn’t find a correlation between the accuracy and the layer size, so we tested the accuracy on the validation set. • By doing so, we get a exactly how accurate the model is on the same data. It would have allowed us to find a correlation easier.

Achievements • We learned a lot about Deep Learning, classifiers, and more specifically about the Contextual Bandits. • We implemented an algorithm for the Contextual Bandit. • We tested said algorithm multiple times, while changing it and making sure it works for the new environment every time. • We learned and used Docker. • We implemented the infrastructure for future testing of similar hypothesizes.

Examples • We tested our Contextual Bandit multiple times. First, we tried testing it in Google Colab, but encountered issues. • Later, we had to modify our algorithm to be tested in IBM’s servers, with our supervisor’s help. • Lastly, we learned how to use Docker, and run our tests with Docker as well.

Conclusions • We found it difficult to find a good dataset for industrial purposes – most of them were for research purposes only. • The runtime for our algorithms is many hours. • We tested many different sizes of input, and different sizes of layers. • It seems our initial hypothesis in not really correct: The correlation between layer size and input size is negligible, although it seems that there is a “correct” size of layers for each input size.

Conclusions • It is possible that for larger datasets and using a larger Word 2 Vec would show better results, and could show a correlation. • It is also possible the hypothesis should be changed: • Suggested hypothesis: Larger input require more layers. • Also, it is possible larger input requires not only more layers, but more layers at different sizes.

Conclusions

Milestones – recap • Week 4 - Literature survey, decide on algorithms, datasets, experiment metrics. • Algorithms: Ensemble & Batch. Eventually not used due to lack of correlation. • The dataset was decided to be a large dataset that contains news categories and short description/headline of those news. • Week 7 – Completed the generic Neural Network and the contextual Bandit algorithm.

Milestones – recap • Week 8 – We tried testing our contextual bandit algorithm using Google Colab, while constantly upgrading our algorithm. • Week 11 – We saw that there is no correlation between the input size and the layer size, so we had to find a different approach. • Week 13 – We tested our algorithm using Docker on the IBM server, trying to find some stronger correlation.

Thank you!
- Slides: 13