CVPR 2019 Poster Task Grounding referring expressions is



























- Slides: 33
CVPR 2019 Poster
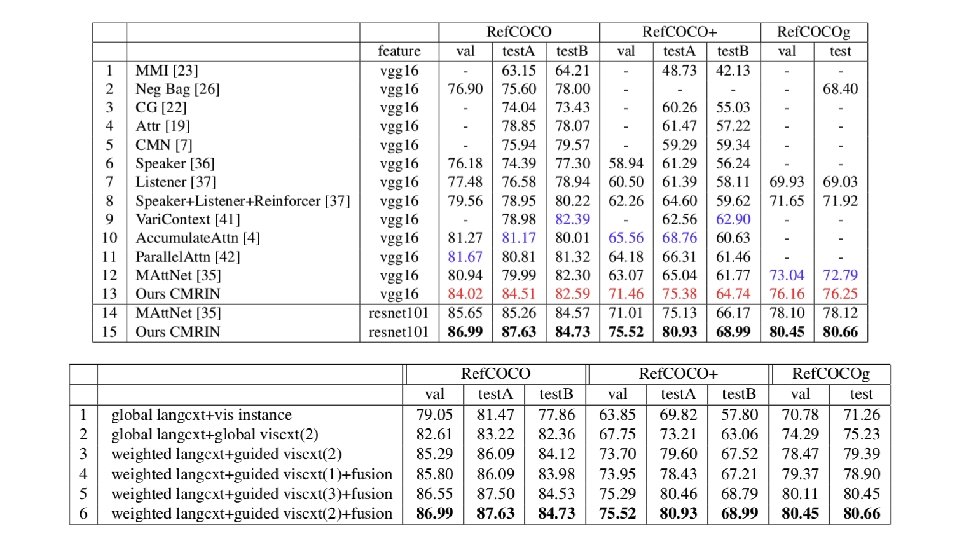
Task Grounding referring expressions is typically formulated as a task that identifies a proposal referring to the expressions from a set of proposals in an image. Summarize visual features of single objects CNN global visual contexts pairwise visual differences object pair context global language contexts LSTM language features of the decomposed phrases
Problem • existing work on global language context modeling and global visual context modeling introduces noisy information and makes it hard to match these two types of contexts • pairwise visual differences computed in existing work can only represent instance-level visual differences among objects of the same category. • existing work on context modeling for object pairs only considers first-order relationships but not multiorder relationships. • multi-order relationships are actually structured information, and the context encoders adopted by existing work on grounding referring expressions are simply incapable of modeling them.
Pipeline
Spatial Relation Graph
Language Context word type word refer to vertex language context
Language-Guided Visual Relation Graph vertex edge
Language-Vision Feature Semantic Context Modeling Loss Function
ICCV 2019
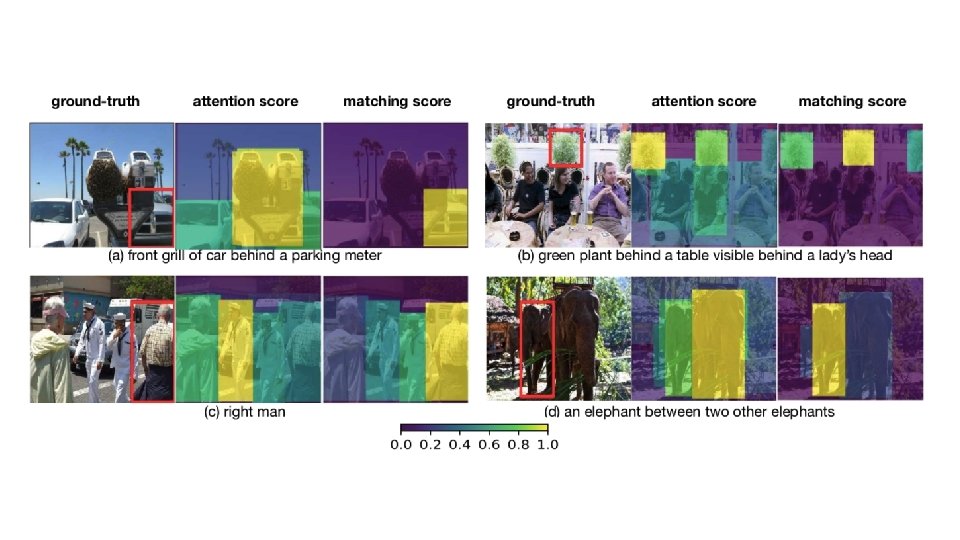
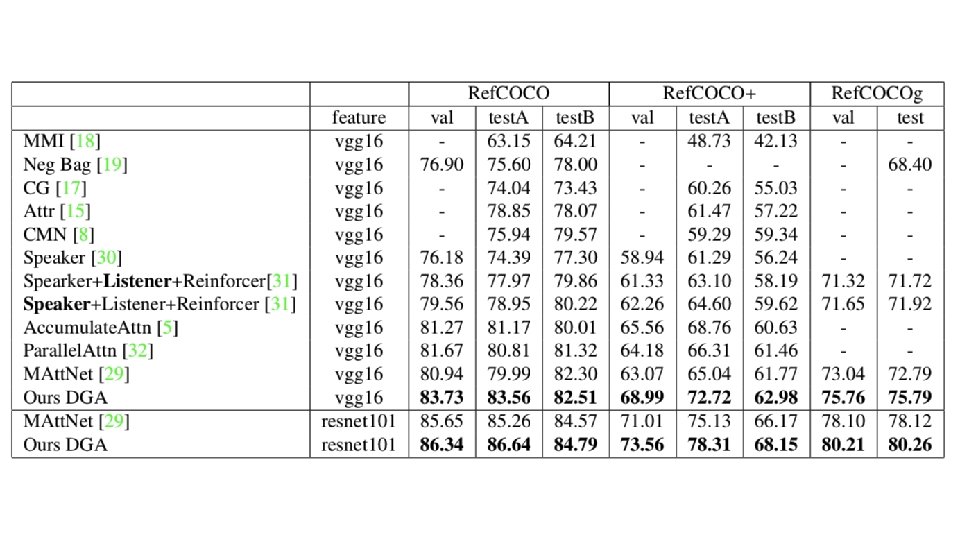
Problem • almost all the existing approaches for referring expression comprehension do not introduce reasoning or only support single-step reasoning • the models trained with those approaches have poor interpretability
Pipeline
Language-Guided Visual Reasoning Process q: which is the concatenation of the last hidden states of both the forward and backward LSTMs
Static Attention
Dynamic Graph Attention
CVPR 2019 Oral
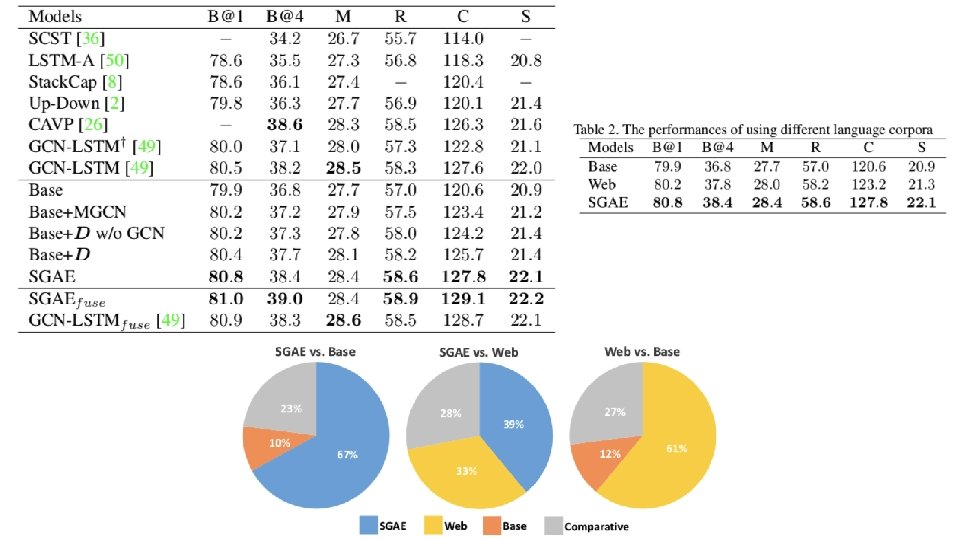
Motivation • when we feed an unseen image scene into the framework, we usually get a simple and trivial caption about the salient objects such as “there is a dog on the floor”, which is no better than just a list of object detection • once we abstract the scene into symbols, the generation will be almost disentangled from the visual perception
Inductive Bias • everyday practice makes us performs better than machines in high-level reasoning • template / rule-based caption models, is well-known ineffective compared to the encoderdecoder ones, due to the large gap between visual perception and language composition • Scene graph --> bridge the gap between two worlds • we can embed the graph structure into vector representations; the vector representations are expected to transfer the inductive bias from the pure language domain to the visionlanguage domain
Encoder-Decoder Revisited
Auto-Encoding Scene Graphs Dictionary
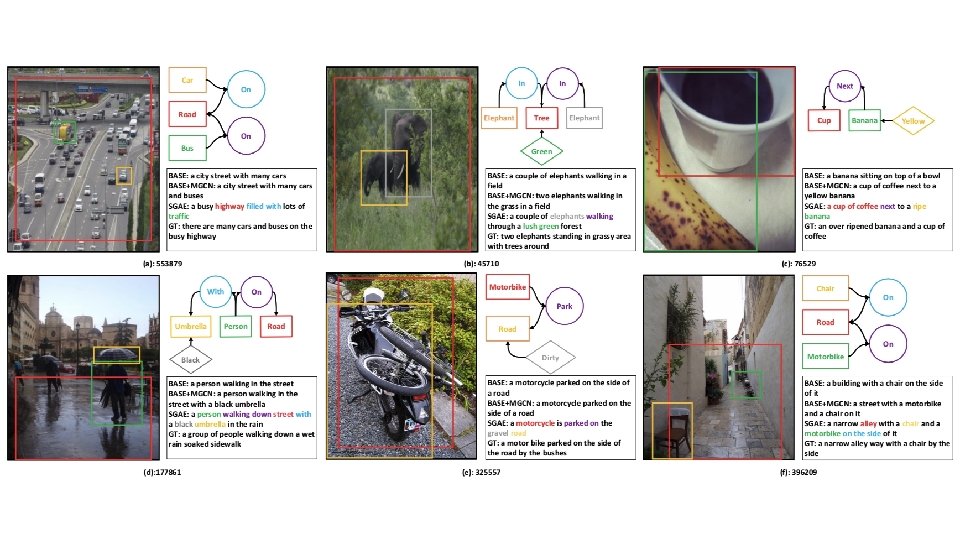
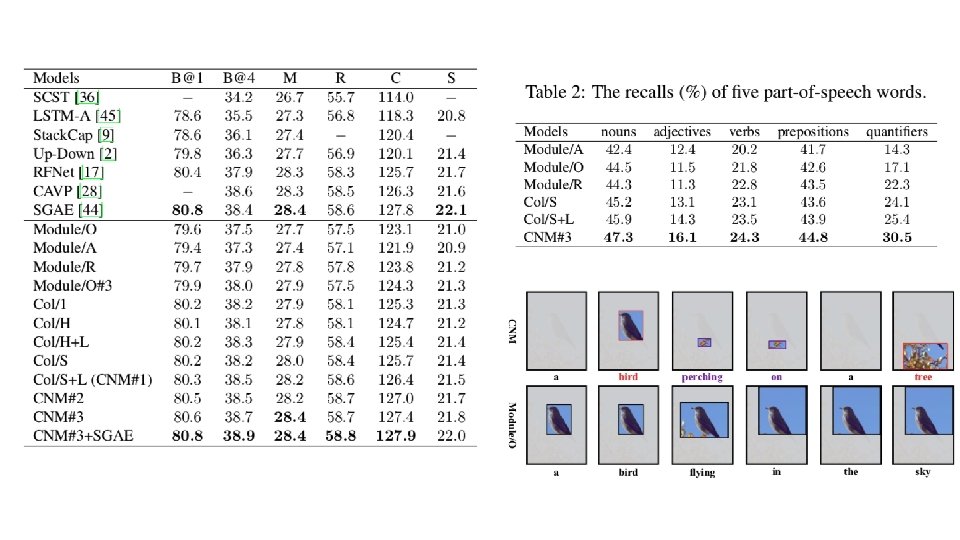
Overall Model: SGAE-based Encoder-Decoder • object detector + relation detector + attribute classifier • multi-modal graph convolution network • pre-train D cross-entropy loss RL-based loss • two decoders:
ICCV 2019
Motivation • unlike a visual concept in Image. Net which has 650 training images on average, a specific sentence in MS-COCO has only one single image, which is extremely scarce in the conventional view of supervised training • given a sentence pattern in Figure 1 b, your descriptions for the three images in Figure 1 a should be much more constrained • studies in cognitive science show that do us humans not speak an entire sentence word by word from scratch; instead, we compose a pattern first, then fill in the pattern with concepts, and we repeat this process until the whole sentence is finished
Tackling the dataset bias
Relation Module Object Module Attribute Module Function Module
Controller Multi-step Reasoning: repeat the soft fusion and language decoding M times. Linguistic Loss: