CSE 58 x Networking Practicum Instructor Wuchang Feng





 ● Programmable ● Mature development environment ● Typically used to")
 ● ● Same as GPP, but – Slower – Cheaper")
 ● Custom hardware ● Long time to market ● Expensive")
 ● Flexible re-programmable hardware ● Less dense and slower")

 –")










 – ● Runs control")








 2. Ready-bus")

 framework – Re-usable function")

- Slides: 36
CSE 58 x: Networking Practicum Instructor: Wu-chang Feng TA: Francis Chang
About the course ● Prerequisite: CSE 524 or the equivalent ● Implementation-focused course – ● Intel's IXA network processor platform Contents – Brief lecture material on network processors and the IXP – 5 weeks of designed laboratories – 3 weeks of final projects
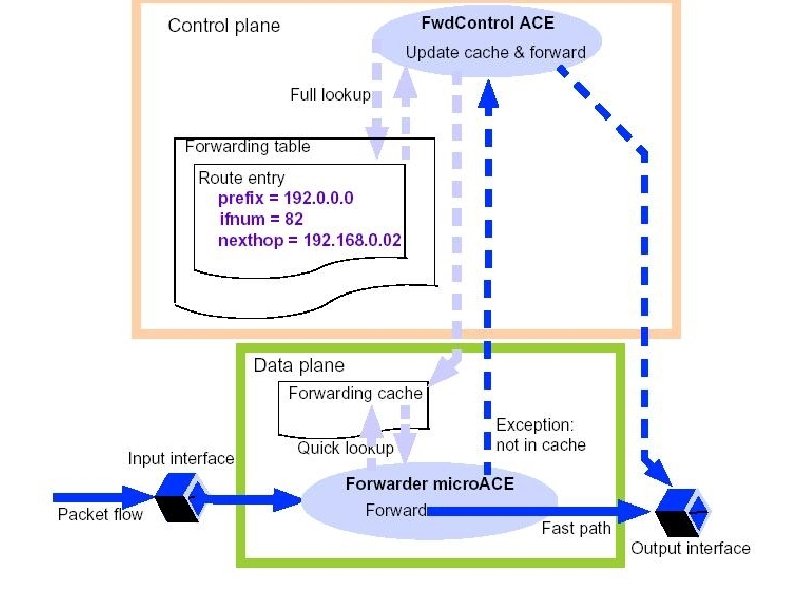
Modern router architectures ● Split into a fast path and a slow path ● Control plane ● – High-complexity functions – Route table management – Network control and configuration – Exception handling Data plane – Low complexity functions – Fast-path forwarding
Router functions ● RFC 1812 plus. . . – Error detection and correction – Traffic measurement and policing – Frame and protocol demultiplexing – Address lookup and packet forwarding – Segmentation, fragmentation, reassembly – Packet classification – Traffic shaping – Timing and scheduling – Queuing – Security
Design choices for network products ● General purpose processors ● Embedded RISC processors ● Network processors ● Field-programmable gate arrays (FPGAs) ● Application-specific integrated circuits (ASICs)
General purpose processors (GPP) ● Programmable ● Mature development environment ● Typically used to implement control plane ● Too slow to run data plane effectively – Sequential execution – CPU/Network 50 x increase over last decade – Memory latencies 2 x decrease over last decade ● Gigabit ethernet: 333 nanosecond per packet budget ● Cache miss: ~150 -200 nanoseconds
Embedded RISC processors (ERP) ● ● Same as GPP, but – Slower – Cheaper – Smaller (require less board space) – Designed specifically for network applications Typically used for control plane functions
Application-specific integrated circuits (ASIC) ● Custom hardware ● Long time to market ● Expensive ● Difficult to develop and simulate ● Not programmable ● Not reusable ● But, the fastest of the bunch ● Suitable for data plane
Field Programmable Gate Arrays (FPGA) ● Flexible re-programmable hardware ● Less dense and slower than ASICs ● Cheaper than ASICs ● Good for providing fast custom functionality ● Suitable for data plane
Network processors ● The speed of ASICs/FPGAs ● The programmability and cost of GPPs/ERPs ● Flexible ● Re-usable components ● Lower cost ● Suitable for data plane
Network processors ● Common features – Small, fast, on-chip instruction stores (no caching) – Custom network-specific instruction set programmed at assembler level ● What instructions are needed for NPs? Open question. ● Minimality, Generality – Multiple processing elements – Multiple thread contexts per element – Multiple memory interfaces to mask latency – Fast on-chip memory (headers) and slow off-chip memory (payloads) – No OS, hardware-based scheduling and thread switching
Why network processors? ● The propaganda ● Take the current vertical network device market ● Commoditize horizontal slices of it ● PC market ● – Initially, an IBM custom vertical – Now, a commodity market with Intel providing the chip-set Network device market – Draw your own conclusions
Network processing approaches Speed ASIC FPGA Network processor GPP Embedded RISC Processor Programming/Development Ease
Network processor architectures ● Packet path – Store and forward ● – Packet payload completely stored in and forwarded from off-chip memory ● Allows for large packet buffers ● Re-ordering problems with multiple processing elements ● Intel IXP, Motorola C 5 Cut-through ● Packet held in an on-chip FIFO and forwarded through directly ● Small packet buffers ● Built-in packet ordering ● AMCC
Network processor architectures ● Processing architecture – – – Parallel ● Each element independently performs entire processing function ● Packet re-ordering problems ● Larger instruction store needed per element Pipelined ● Each element performs one part of larger processing function ● Communicates result to next processing element in pipeline ● Smaller code space ● Packet ordering retained ● Deterministic behavior (no memory thrashing) Hybrid
Network processor architectures ● Processing hierarchy – ASICs – Embedded RISC processors – Specialized co-processors – See figure 13. 7 in book
Network processor architectures ● Memory hierarchy – – Small on-chip memory ● Control/Instruction store ● Registers ● Cache ● RAM Large off-chip memory ● Cache ● Static RAM ● Dynamic RAM
Network processor architectures ● Internal interconnect – Bus – Cross-bar – FIFO – Transfer registers
Network processor architectures ● Concurrency – Hardware support for multiple thread contexts – Operating system support for multiple thread contexts – Pre-emptiveness – Migration support
Increasing network processor performance ● ● Processing hierarchy – Increase clock speed – Increase elements Memory hierarchy – Increase size – Decrease latency – Pipelining – Add hierachies – Add memory bandwidth (parallel stores) – Add functional memory (CAMs)
Focus of this class. . . ● Network processors – Intel IXA
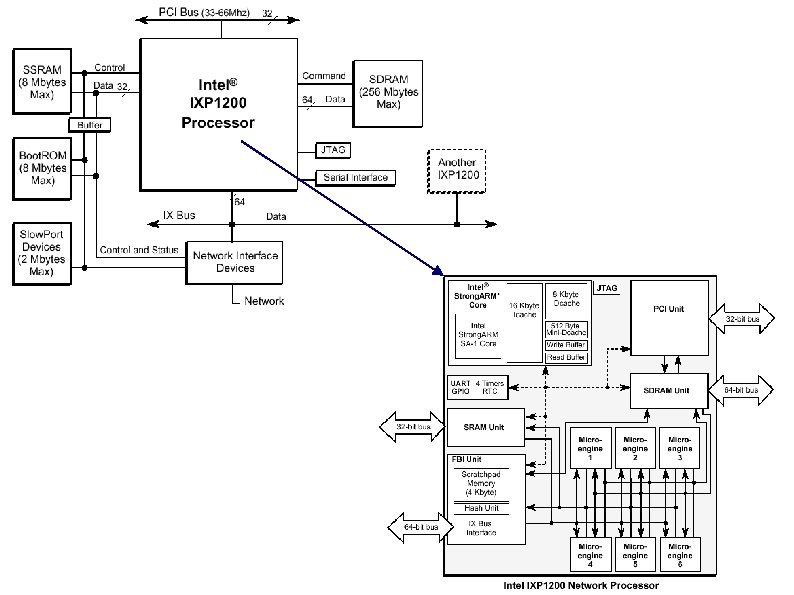
IXP 1200 features ● One embedded RISC processor (Strong. ARM) – ● Runs control plane (Linux) 6 programmable packet processors (m-engines) – Runs data plane (m-engine assembler or m-engine C) ● Central hash unit ● Multiple, bus interconnects – IXBus (4. 4 Gbps) to overcome PCI's 2. 2 Gbps limit ● Small on-board memory ● Serial interface for control ● External interfaces for memory
IXP 12 xx m-engine
IXP 2 xxx m-engine
m-engine functions ● Packet ingress from physical layer interface ● Checksum verification ● Header processing and classification ● Packet buffering in memory ● Table lookup and forwarding ● Header modification ● Checksum computation ● Packet egress to physical layer interface
m-engine characteristics ● ● Programmable microcontroller – Custom RISC instruction set – Private 2048 instruction store per m-engine (loaded by Strong. ARM) – 5 -stage execution pipeline Hardware support for 4 threads and context switching – Each m-engine has 4 hardware contexts (mask memory latency)
m-engine characteristics ● ● ● 128 general purpose registers – Can be partitioned or shared – Absolute or context-relative 128 transfer registers – Staging registers for memory transfers – 4 blocks of 32 registers ● SDRAM or SRAM ● Read or Write Local Control and Status Registers (CSRs) – USTORE instructions, CTX, etc. (p. 315)
m-engine characteristics ● FBI unit – Scratchpad memory – Hash unit – FBI CSRs – IXBus control – IXBus FIFOs ● Transmit and Receive FIFOs to external line cards
32 m-engine opcodes ● ALU instructions – ● Branch/Jump instructions – ● BR, BR=0, BR!=0, BR_BSET, BR=BYTE, BR=CTX, BR_INP_STATE, BR_!SIGNAL, JUMP, RTN, etc. Reference instructions – ● ALU, ALU_SHF, DBL_SHIFT CSR, FAST_WR, LOCAL_CSR_RD, R_FIFO_RD, PCI_DMA, SCRATCH, SDRAM, SRAM, T_FIFO_WR, etc. Local register instructions – FIND_BST, IMMED, LD_FIELD, LOAD_ADDR, LOAD_BSET_RESULT 1, etc.
32 m-engine functions ● Miscellaneous – CTX_ARB – NOP – HASH 1_48, HASH 1_64, etc.
8 9 8 8 9 1. Packet received on physical interface (MAC) 2. Ready-bus sequencer polls MAC for mpacket Updates receive-ready upon a full mpacket 3. m-engine polls for receive-ready 4. m-engine instructs FBI to move mpacket from MAC to RFIFO 5. m-engine moves mpacket directly from RFIFO to SDRAM 6. Repeat 1 -5 until full packet received 7. m-engine or Strong. ARM processing 8. Packet header read from SDRAM or RFIFO into m-engine and classified (via SRAM tables) 9. Packet headers modified 10. mpackets sent to interface 11. Poll for space on MAC Update transmit-ready if room for mpacket 12. mpackets transferred to MAC
Programming the IXP ● Focus of this course on steps 7, 8, and 9 ● 2 programming frameworks – Command-line, IXA Active Computing Engine (ACE) framework – Graphical microengine C development environment
Programming the IXP ● Command-line, IXA Active Computing Engine (ACE) framework – Re-usable function blocks chained together to build an application (Chapters 22 -24) – New functions implemented as new blocks in chain ● Core ACEs (Strong. ARM) – ● Written in C Microblock ACEs (microengines) – Written in assembler
Programming the IXP ● Graphical microengine C development environment – Monolithic microengine C code (can not be used on IXP 1200 hardware) – Demos forthcoming