Beyond demonstrations Learning behavior from higherlevel supervision Hal

Beyond demonstrations: Learning behavior from higher-level supervision Hal Daumé III Microsoft Research University of Maryland me@hal 3. name @haldaume 3 he/him/his
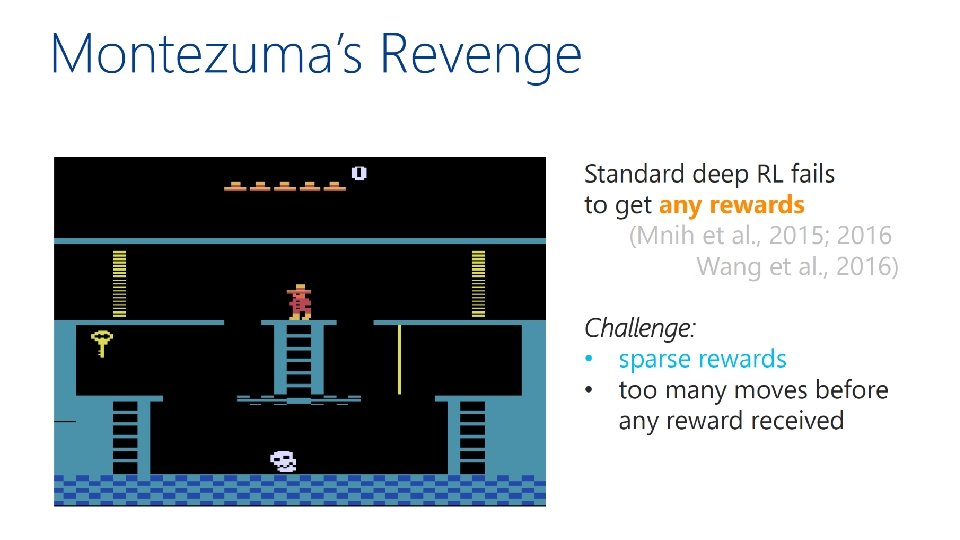



Hybrid imitation / reinforcement learning Teacher provides high-level feedback and agent applies standard RL at the low level à speed-up in learning [evaluate on Montezuma’s revenge, theory bounds number of queries to expert] with: Hoang Le Nan Jiang Alekh Agarwal Yisong Yue Miro Dudík Reinforcement learning with convex constraints Teacher provides high-level constraints/preferences with: and agent applies interleaved RL & online updates Sobhan Miryoosefi à speed-up in learning Kianté Brantley Miro Dudík [evaluate on “Mars rover” domains Robert Schapire “safety” and “diversity” constraints

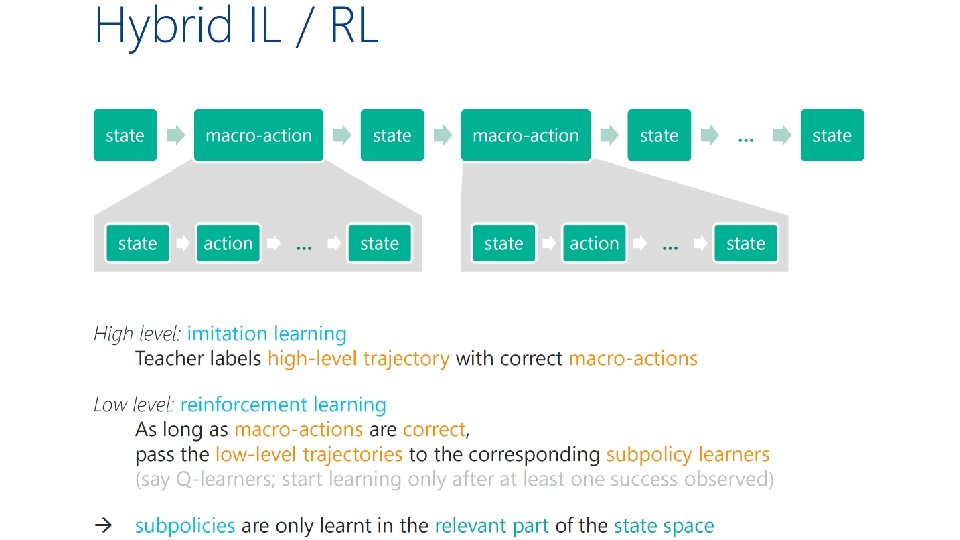
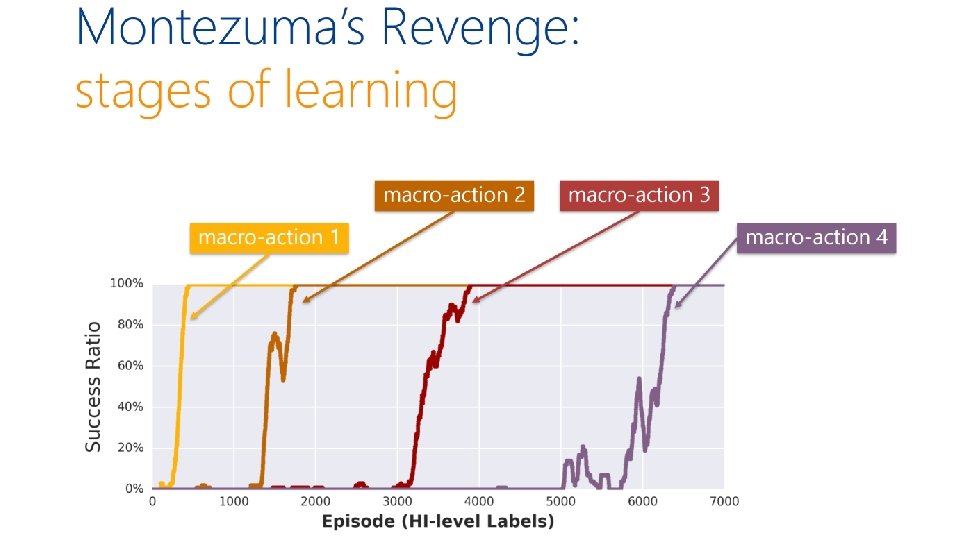
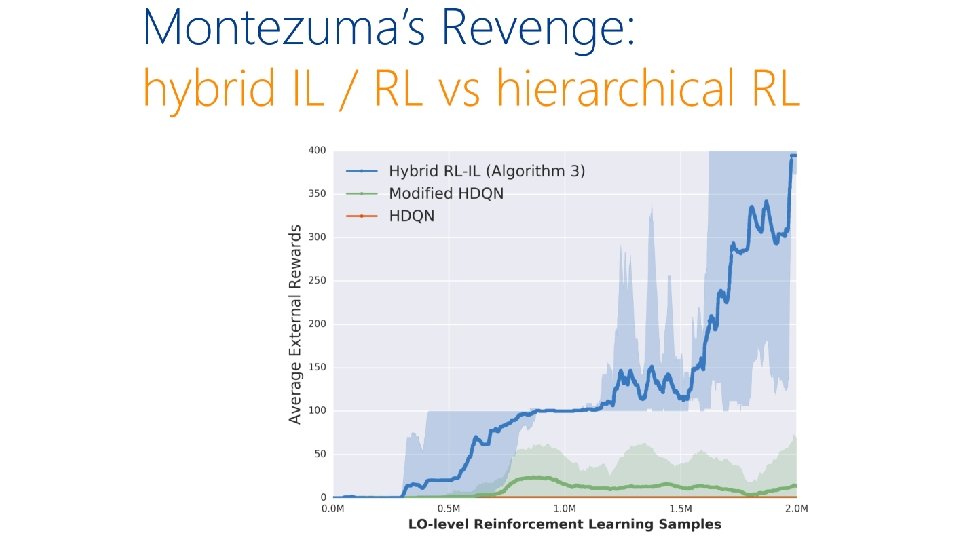

Hybrid imitation / reinforcement learning Teacher provides high-level feedback and agent applies standard RL at the low level à speed-up in learning [evaluate on Montezuma’s revenge, theory bounds number of queries to expert] with: Hoang Le Nan Jiang Alekh Agarwal Yisong Yue Miro Dudík Reinforcement learning with convex constraints Teacher provides high-level constraints/preferences with: and agent applies interleaved RL & online updates Sobhan Miryoosefi à speed-up in learning Kianté Brantley Miro Dudík [evaluate on “Mars rover” domains Robert Schapire “safety” and “diversity” constraints

Reinforcement learning with convex constraints Best mixture policy Expected measurement vector Arbitrary convex set

Best mixture policy Best-response on policy = Run RL against measurement vector Expected measurement vector Online gradient descent on “dual” variables
")
Constraints: 1. High reward 2. Low probability of failure 3. High diversity (optional)
: Given: - Positive response RL oracle with tolerance - Estimation oracle (of")
Theorem (hand-wavy): Given: - Positive response RL oracle with tolerance - Estimation oracle (of measurement) with tolerance - Projection oracle (onto convex set) After T rounds:

Hybrid imitation / reinforcement learning Teacher provides high-level feedback and agent applies standard RL at the low level à speed-up in learning [evaluate on Montezuma’s revenge, theory bounds number of queries to expert] with: Hoang Le Nan Jiang Alekh Agarwal Yisong Yue Miro Dudík Reinforcement learning with convex constraints Teacher provides high-level constraints/preferences with: and agent applies interleaved RL & online updates Sobhan Miryoosefi à speed-up in learning Kianté Brantley Miro Dudík [evaluate on “Mars rover” domains Robert Schapire “safety” and “diversity” constraints
- Slides: 15