Alkalmazott statisztikai alapok A mintavtel Minek ez egyltaln


: azon adott jellemzővel leírható csoport létező összes eleme, amire")


")


 mintavétel: előzetes")




 : • Akkor használható ha a teljes")
: • A sokaságnak diszjunkt részhalmazokra (klaszterekre) bonthatónak")




 / (teljes mintanagyság – kizárt")



 Ghauri & Gronhaug")
- Slides: 25
Alkalmazott statisztikai alapok: A mintavétel
Minek ez egyáltalán? Akkor alkalmazunk mintavételes vizsgálatot, ha a teljes sokaság vizsgálata: - túl költséges (pénzben vagy időben), - lehetetlen (pl. a sokaság elemei túl gyorsan cserélődnek vagy a sokaság praktikus szempontból végtelen nagyságú), - az adatfelvétel tönkreteszi a vizsgált elemeket (pl. kóstolás) vagy jelentősen megváltoztatja azokat (pl. mélyinterjú).
Alapfogalmak • Sokaság, populáció (population): azon adott jellemzővel leírható csoport létező összes eleme, amire vonatkozóan következtetést akarunk levonni vagy amit meg akarunk ismerni (mérni). • Minta (sample): a populáció olyan része (részsokasága, részhalmaza), amelyről feltételezzük, hogy a vizsgálati szempontokból visszaadja a teljes sokaság viselkedését, jellemzőit (reprezentálja azt). • Mintavétel (sampling): az a folyamat, amely során a sokaság valamely része kiválasztásra kerül a sokaság megismerése céljából (vagyis további elemzésre a sokaság helyett).
Reprezentativitás • A minta valamely szempontból reprezentatív, ha szerkezete e szempontból megegyezik a sokaságéval. Csak akkor fontos, ha a teljes sokaságra akarunk következtetni. • A további elemzés kritikus faktora: ha a minta nem reprezentálja a sokaságot, akkor nem is lehet annak vizsgálatából a sokasága általánosítani a következtetéseinket! • Általában vett reprezentativitás a valóságban nincs. Mindig csak adott jellemzőkre, dimenziókra lehet a minta reprezentatív. A kutatási kérdés dönti el, hogy mire nézve legyen a minta reprezentatív (ami a kérdés szempontjából befolyásol(hat)ja a sokaság viselkedését). Előzetesen nem mindig állapítható meg, ilyenkor általában szakirodalmi tapasztalatokra hagyatkozva döntünk róla.
„Az én mintám nem reprezentatív. Mi van ilyenkor? ” Az alábbiak közül valamelyik: • Új mintát kell venni, vagy új elemek felvételével korrigálni. • Új kutatási kérdést kell feltenni, amire nézve vagy reprezentatív a minta, vagy ami nem igényli a reprezentativitást (vagyis nem a teljes sokaságra vonatkozik). • Ha az eltérés csak minimális (na de ezt ki dönti el? ), akkor elég lehet súlyozással korrigálni.
Miből kell a mintát kiválogatni? Mintavételi keret: • Olyan elemek (adategységek, pl. lakcímek, nevek) listája amelyekből a tényleges mintát vesszük. • Ha nem illeszkedik tökéletesen a mintavételi keret és a célsokaság (pl. lakosság vs. telefonkönyv) akkor eleve lehetetlen a sokaságra nézve reprezentatív mintát venni.
A mintavétel folyamata 1. 2. 3. 4. 5. 6. Sokaság meghatározása Mintavételi keret meghatározása Mintavételi eljárás kiválasztása Mintanagyság meghatározása Mintavételi egységek (mintaelemek) kiválasztása Adatok összegyűjtése a mintában szereplő egységektől
Mintavételi eljárások • Véletlen mintavétel: a sokaság minden elemének azonos esélye van arra, hogy bekerüljön a mintába. A valóságban azonban csak ezt közelítő eljárásokat is ide sorolják: a sokaság minden elemének ismert esélye van a mintába kerülésnek. Statisztikailag jól kezelhető. • Nem véletlen mintavétel: a bekerülés valószínűsége nem azonos a sokaság minden elemére. Általában – különösen nagy mintáknál – statisztikailag rosszabb, mint a véletlen mintavétel (a minta nagyságának növekedés ugyanis nem vezet javuló reprezentativitáshoz).
Nem véletlen mintavételi eljárások • Kényelmi vagy hozzáférhetőségi mintavétel • Szakértői (elbírálásos) mintavétel: előzetes tudásunk alapján válogatjuk össze a mintát úgy, hogy az minél reprezentatívabb legyen. Kis minták esetén akár jobb is lehet, mint a véletlen minta. • Kvótás mintavétel: a részsokaságokat bizonyos ismérvek szerint a teljes sokaságra jellemző arányban szerepeltetjük a mintában. Azokra nézve tehát biztosítjuk a reprezentativitást. A többi ismérv szerint azonban az súlyosan sérül (itt ugyanis kényelmi mintavétel történik).
Nem véletlen mintavételi eljárások • Hólabda mintavétel: az első válaszadók javasolják vagy szervezik be a későbbi válaszadókat. Hatásosan növeli a válaszadási hajlandóságot, de rendkívül torzított mintát eredményez. • Koncentrált kiválasztás: reprezentánsok (olyan elemek, amelyekből kevés van, de nagy a befolyásuk a teljes sokaság viselkedésére) kiválasztása. Kvalitatív módszereknél gyakori.
Kvázi-véletlen mintavételi eljárások • A valóságban véletlen mintavétel gyakorlatilag lehetetlen, csak kvázi-véletlen eljárások vannak (hiszen már a véletlen szám generálása is lehetetlen), de az egyszerűség kedvéért ezeket összefoglalóan mégis véletlen mintavételnek hívják.
Véletlen mintavételi eljárások Egyszerű véletlen mintavétel: • Ha adott egy teljes mintavételi keret, akkor ennek minden egységének azonos esélyt adunk a mintába kerülésre (pl. véletlenszám-generátorral). • Lehet visszatevéses vagy visszatevés nélküli. • Ha minden elemnek van egy előre adott konstans bekerülési esélye, az a Bernoulli-féle mintavétel. • Egyszerű, de az egyes mintavételek nagyon eltérő mintákat is eredményezhetnek (a becslés standard hibája nagy). • Arányosítható is az elemek mérete alapján, ha ez fontos (pl. cégek esetén azok árbevételével vagy létszámával).
Véletlen mintavételi eljárások Szisztematikus mintavétel: • Egy véletlenszerűen meghatározott első elemtől kezdve azonos képlet alapján kapja meg a következő elemeket (pl. minden 5 -dik járókelő, vagy minden balra második ajtó stb. ). • Csak akkor használható, ha az elemek a sokaságban sorba rendezettek. • Egyszerű. Keretet sem feltétlenül igényel! • Védtelen azonban az elemek sorszámától függő hatások torzításától. Ha ilyen van, akkor nem véletlen a mintavétel. • Egyik fajtája a véletlen út módszere: ha előre rögzítik az adatfelvevő mozgási szabályait (pl. egy emeletet fel és egy ajtót jobbra) , az adott terep előzetes ismerete nélkül, akkor véletlen-közeli mintát eredményez. Az első elemet véletlenszerűen kell kiválasztani.
Véletlen mintavételi eljárások Rétegzett mintavétel (stratified sampling) : • Akkor használható ha a teljes sokaság viszonylag homogén diszjunkt részhalmazokra (rétegekre) osztható, amelyek egymástól lényegesen különböznek, és ha adott egy teljes keret. • Minden rétegből véletlenszerűen veszünk mintát. • Ez csökkenti a minták mintavételenkénti eltéréseit az egyszerű véletlen mintához képest (hiszen mindig minden rétegből kerül bele elem). Vagyis pontosabb lehet az egyszerű véletlen mintavételnél, ha a belső szórás kicsi, a külső pedig nagy. • Leegyszerűsíti az adatfelvételt is.
Véletlen mintavételi eljárások Csoportos mintavétel (cluster sampling): • A sokaságnak diszjunkt részhalmazokra (klaszterekre) bonthatónak kell lennie, melyek belül minél heterogénebbek legyenek. Az elemek egy klaszteren belül nem hasonlóak egymáshoz, de a klaszterek egymáshoz igen. • Itt a klasztereket választjuk ki véletlenül, és azokon belül vagy teljes adatfelvételt végzünk (egylépcsős), vagy véletlen mintát veszünk (kétlépcsős). Tehát nem kerül minden klaszterből elem a mintánkba. • Előnye, hogy koncentráltabb, ezért olcsóbb az adatfelvétel. • Nem működik jó, ha a klaszterek közti külső szórás nagy.
A mintavétel során elkövethető hibák két csoportja • Mintavételi hiba: a minta és a célsokaság struktúrája közti különbség. A véletlen mintavételi módszereknél becsülhető, a nem véletlen módszereknél nem. • Nem mintavételi hiba: nem a mintavételből, hanem más okból fakad. Pl. válaszmegtagadás, rossz kérdések, téves válaszok.
A kiválasztási torzítás • Abból ered, ha a minta kialakítója vagy az adatfelvevő nem véletlenszerűen dönti el, hogy mely elemet – választ be a mintába, vagy – zár ki a mintából. • Önkiválasztási torzítás: ennek az a változata, ha maga a sokasági elem (pl. válaszadó) dönt úgy (nem véletlenszerűen), hogy bekerül vagy kimarad.
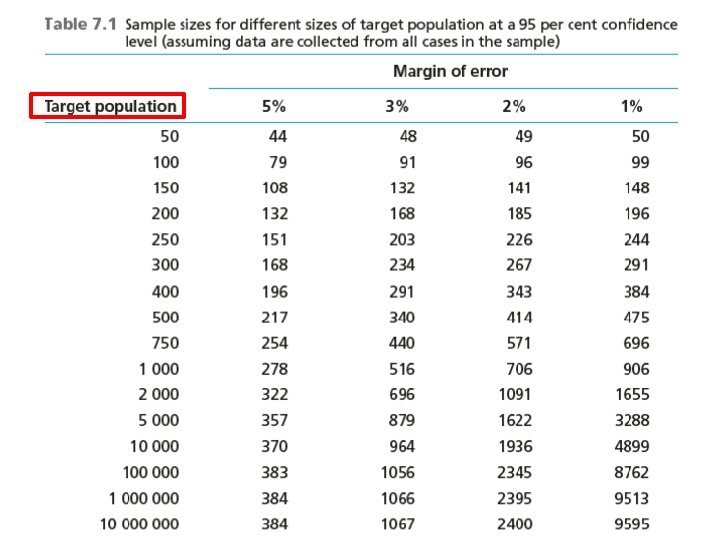
A mintanagyság meghatározása • A mechanikus meghatározás csak valószínűségi mintáknál alkalmazható. • Függ a kívánt pontosságtól és megbízhatóságtól, valamint a költségektől és az egyéb lehetőségektől. A pontosság (pontbecslésnél) a becslési intervallum mérete. • Az átlag standard hibája: SE = SD / (n)½ • Adott H intervallum mellett, ismerve a kívánt megbízhatósági szintet (így normál eloszlás feltételezése estetén az ahhoz tartozó z értéket is) és szórást: H = z * SE = z * [SD / (n)½]
A mintanagyság meghatározása • Ha a teljes sokaságot végesnek feltételezzük, akkor korrigálni kell a standard hiba képletét: SE = [SD / (n)½] * [(N – n)/(N – 1)]
A válaszadási arány Teljes válaszadási arány = (beérkezett válaszok) / (teljes mintanagyság – kizárt elemek) Aktív válaszadási arány = (beérkezett válaszok) / (teljes mintanagyság – kizárt vagy nem elérhető elemek)
A mintanagyság meghatározása Befolyásolja még a mintanagyságot, hogy: • A kívánt megbízhatósági szint, hibahatár. • Akarunk-e alsokaságokat vizsgálni, mert akkor ezeknek is megfelelő számosságúnak kell lenni. • Mekkora válaszadási arányra számítunk. • Számítunk-e torzító tényezőkre (pl. válaszmegtagadás). • A teljes sokaság (vagy a mintavételi keret) nagysága.
A mintanagyság meghatározása a gyakorlatban • Mi az elfogadható adott tudományterületen • Elég nagy legyen minden vizsgált részminta ahhoz, hogy a kívánt elemzési módszer megbízhatóan megvalósítható és értelmezhető legyen.
Utólagos javítások • Általánosíthatóság demonstrálása: újabb mintavételi technikával • Adatfelvétel a nem válaszolók megkeresésével • A nem válaszolók elemzése az okok szerint • Hullám-elemzés (wave analysis): a korán és későn válaszolók összehasnlítása
Felhasznált és egyben ajánlott irodalom • • Saunders et al. (2016) Ghauri & Gronhaug (2011) Hunyadi, Mundruczó & Vita (1997) Sajtos & Mitev (2008)