Matakuliah Aplikasi Multimedia untuk Penerjemahan II Teknologi Bahasa

Matakuliah : Aplikasi Multimedia untuk Penerjemahan II Teknologi Bahasa ( Text to Speech & Voice Recognation ) Slide : Arry Akhmad Arman Institut Teknologi Bandung Iwan Sonjaya, MT

How small can you go? Still convenient?

Apa “Teknologi Bahasa”?

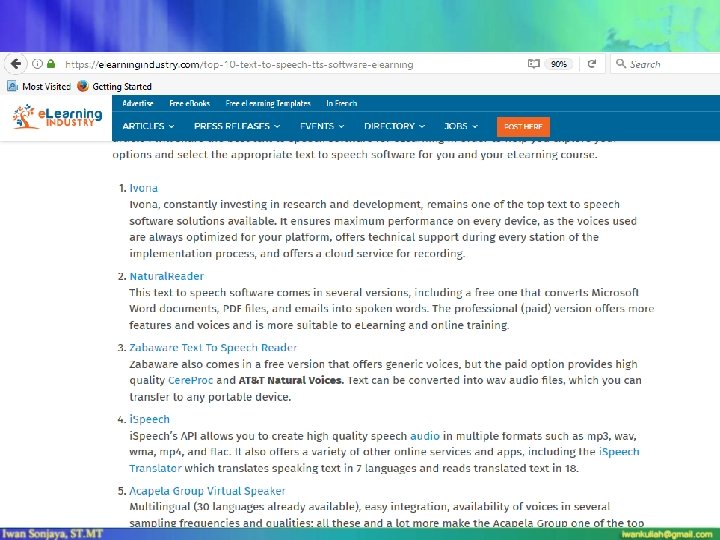
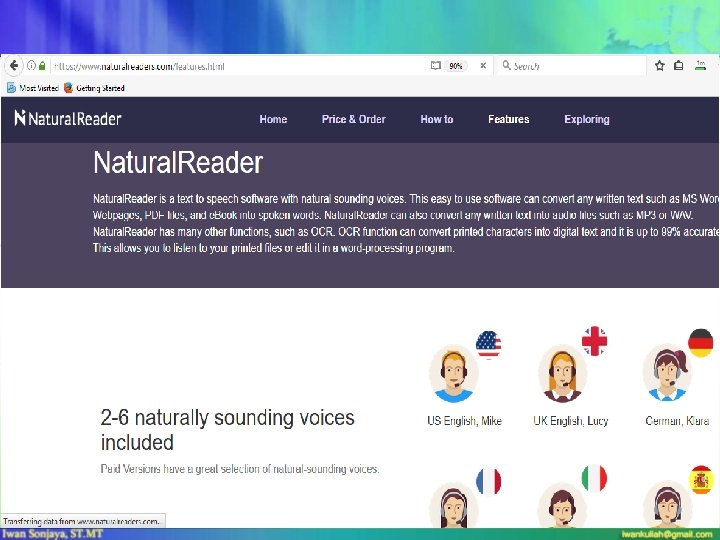
Komponen Teknologi Bahasa Text to Speech Recognition NLP: Language Translator

Apa “Text to Speech”? Text to Speech Ucapan

Indonesian Text to Speech System Diphone Database Intonation Model Text to Phoneme Converter Phonemes Phoneme to Speech Converter Speech

Konversi Teks ke Ucapan Bapak membeli 5 kerang seharga Rp 200, - ch eme-to-Speec Phone eme ext-to-Phone Te Text Normalization Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation Speech Parameter Generation Speech Waveform Production

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - ch eme-to-Speec Phone eme ext-to-Phone Te Text Normalization Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation Speech Parameter Generation Speech Waveform Production saya membeli lima kerang seharga dua ratus rupiah

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - ch eme-to-Speec Phone eme ext-to-Phone Te Text Normalization Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation Speech Parameter Generation Speech Waveform Production saya membeli lima kerang seharga dua ratus rupiah *|s|* => |s| *|a| =>|a| *|n|~g => |n| *|n|g => |ñ| n|g|* => |blank| ~n|g|* => |g|

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - eme ext-to-Phone Te IT => /a//i//t//i/ ch eme-to-Speec Phone teknik => /t//E//k/ /n//i//k/ Text Normalization Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation Speech Parameter Generation Speech Waveform Production saya membeli lima kerang seharga dua ratus rupiah *|s|* => |s| *|a| =>|a| *|n|~g => |n| *|n|g => |ñ| n|g|* => |blank| ~n|g|* => |g|

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - eme ext-to-Phone Te ch eme-to-Speec Phone teknik => /t//E//k/ /n//i//k/ Text Normalization Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation saya membeli lima kerang seharga dua ratus rupiah *|s|* => |s| *|a| =>|a| *|n|~g => |n| *|n|g => |ñ| n|g|* => |blank| ~n|g|* => |g| |_||s||a||y||a| … |_||k||e||r||a||ñ| |_|… Speech Parameter Generation Speech Waveform Production

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - eme ext-to-Phone Te teknik => /t//E//k/ /n//i//k/ Text Normalization ch eme-to-Speec Phone |_| , 100 ms |s| , 60 ms, 97 Hz |a| , 85 ms, 100 Hz …. |r| , 55 ms, 110 Hz |a| , 90 ms, 114 Hz | ñ|, 87 ms , 117 Hz … Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation saya membeli lima kerang seharga dua ratus rupiah *|s|* => |s| *|a| =>|a| *|n|~g => |n| *|n|g => |ñ| n|g|* => |blank| ~n|g|* => |g| |_||s||a||y||a| … |_||k||e||r||a|| ñ | |_|… Speech Parameter Generation Speech Waveform Production

Konversi Teks ke Ucapan Saya membeli 5 kerang seharga Rp 200, - eme ext-to-Phone Te teknik => /t//E//k/ /n//i//k/ Text Normalization ch eme-to-Speec Phone |_| , 100 ms |s| , 60 ms, 97 Hz |a| , 85 ms, 100 Hz …. |r| , 55 ms, 110 Hz |a| , 90 ms, 114 Hz | ñ|, 87 ms , 117 Hz … Exception Dictionary Lookup Letter-to-Phoneme Conversion Prosody Generation saya membeli lima kerang seharga dua ratus rupiah *|s|* => |s| *|a| =>|a| *|n|~g => |n| *|n|g => |ñ| n|g|* => |blank| ~n|g|* => |g| |_||s||a||y||a| … |_||k||e||r||a|| ñ | |_|… Speech Parameter Generation Speech Waveform Production
 • Concatenation")
Teknik Pembangkitan Ucapan • Formant Synthesizer (penentuan parameter frekuensi untuk setiap fonem) • Concatenation (rekaman kata yang disambung) – Word concatenation (terbatas) – Diphone Concatenation (teknik yang saat ini digunakan untuk TTS Bahasa Indonesia) – Unit Selection (today’s most uptodate TTS) • Articulatory Model (penentuan parameter fisik alat-alat ucap manusia untuk setiap fonem)
![[Teknik Pembangkitan Ucapan] Formant Synthesizer](http://slidetodoc.com/presentation_image_h2/f8f95df4a01c84c1cdf1a04968626b1c/image-15.jpg "[Teknik Pembangkitan Ucapan] Formant Synthesizer")
[Teknik Pembangkitan Ucapan] Formant Synthesizer
![[Teknik Pembangkitan Ucapan] Formant Synthesizer F 1 F 2 F 3 /a/ /i/ /a/](http://slidetodoc.com/presentation_image_h2/f8f95df4a01c84c1cdf1a04968626b1c/image-16.jpg "[Teknik Pembangkitan Ucapan] Formant Synthesizer F 1 F 2 F 3 /a/ /i/ /a/")
[Teknik Pembangkitan Ucapan] Formant Synthesizer F 1 F 2 F 3 /a/ /i/ /a/ 180 272 390 171 293 377 180 272 390 Formant Synthesizer module
![[Teknik Pembangkitan Ucapan] Diphone Concatenation _|s = wav 11 s|a = wav 23 a|y](http://slidetodoc.com/presentation_image_h2/f8f95df4a01c84c1cdf1a04968626b1c/image-17.jpg "[Teknik Pembangkitan Ucapan] Diphone Concatenation _|s = wav 11 s|a = wav 23 a|y")
[Teknik Pembangkitan Ucapan] Diphone Concatenation _|s = wav 11 s|a = wav 23 a|y = wav 54 y|a =wav 167 a|_ =wav 365 /s//a/y/a/ Diphone Sequencer _/s s/a a/y y/a a/_ Diphone Concatenation Engine

SPEECH RECOGNITION

• Speech recognition is a process by which a computer takes a speech signal (recorded using a microphone) and converts it into words in real-time. It is achieved by following certain steps and the software responsible for it is known as a ‘Speech Recognition System’ • SR systems are usually implemented in the form of dictation software and intelligent assistants in personal computers, smartphones, web browsers and many other devices.

Apa “Speech Recognition”? Ucapan Speech Recognition Text

Speech Recognition System

CHALLENGES IN THE DESIGN OF A SR SYSTEM SR systems have to deal with a large number of challenges like : • The speaker’s voice is often accompanied by surrounding noise which makes their accurate recognition difficult. • A speaker may speak a number of different words and all of these words have to be accurately recognized. • Accent of speaking varies from person to person and this is a very big challenge • A speaker may speak something very quickly and all of the words spoken have to be individually recognized accurately.

TYPES OF SR SYSTEMS • Speaker Dependent SR systems : Work by learning the unique characteristics of a single person’s voice and depend on the speaker for training. • Speaker Independent SR systems : Designed to recognize anyone’s voice, so no training is involved.

BASIC PRINCIPLES OF SPEECH RECOGNITION • The smallest unit of spoken language is known as a Phoneme. • The English language contains approximately 44 phonemes representing all the vowels and consonants that we use for speech. • We can take the example of a typical word such as moon which can be broken down into three phonemes: m, ue, n.

• To interpret speech we must have a way of identifying the components of spoken words and phonemes act as identifying markers within speech. • An algorithm has to be used to interpret the speech further. The Hidden Markov Model is a commonly used mathematical model used to do this. • To create a speech recognition engine, a large database of models is created to match each phoneme. • When a comparison is performed, the most likely match is determined between the spoken phoneme and the stored one, and further computations are performed.

Popular Voice/Speech Recognition Software ● ● ● It seems that in researching this topic, Dragon Naturally. Speaking is the most popular software used. They even have an app for your iphone! It has a 99% accuracy level, which is the best out there. This software is that it is expensive (about $200), and it uses a lot of computer memory.

Benefits of Voice/Speech Recognition Software ● ● ● Voice recognition software helps children with physical and mental disabilities stay on par with their peers, and puts them on a more equal level. They are able to get the same information as other students, even if they have trouble reading, and they are able to communicate their ideas, even if they have trouble writing/typing. It saves them time as well, as many students with these disabilities would take much longer to read and write without this software, and not get as accurate results.

Weaknesses of Voice Recognition Software ● ● Although voice recognition technology has come a long way, it still has some flaws. For example, even though you can talk fairly conversationally and still have high accuracy, there always issues with having 100% accuracy, especially if you have a thick accent. It is also necessary that you do speech to text in a quiet room, where background noise doesn't interfere with the recognition of what you are saying. Also, a significant amount of hardware space is taken up by these programs, since they need to have an extensive vocabulary. Depending on your computer, this can be harmful to it. This software can also have difficulty with homonyms, so when you say “there, ” they could interpret it as “they're” or “their” as well.

The Future of Voice/Speech Recognition Software ● ● Scientists are currently working on a universal voice recognition translator of sorts, where people of any language can speak, and what they say can be translated into any language, in both speech and text formats. Though far in the future, it may also be possible for computers to not only recognize what you are saying, but understand what you are saying and communicate back with you as well. (crazy!)


Terimakasih…. . Untuk mahasiswa/i yang tidak ngantuk dan tetap konsentrasi Mengikuti Perkuliahan. Sampai berjumpa minggu depan ……. . (Dalam perkuliahan dosen yang sama)
- Slides: 33