Lecture 5 Sept 06 2012 Regular expressions examples



 v. Induction 1: If E 1 and E 2 are")
 v. Induction 3: If E is a RE, then E*")

 = {01}. v. L(01+0) = {01, 0}. v. L(0(1+0)) =")








, we remove states one")


- Slides: 20
Lecture 5 Sept 06, 2012 • Regular expressions – examples • Converting DFA to regular expression. (same works for NFA to r. e. conversion. ) • Converting R. E. to NFA
RE’s: Introduction v. Regular expressions are an algebraic way to describe languages. v. They describe exactly the regular languages. v. If E is a regular expression, then L(E) is the language it defines. v. We’ll describe RE’s and their languages recursively.
RE’s: Definition v. Basis 1: If a is any symbol, then a is a RE, and L(a) = {a}. v. Note: {a} is the language containing one string, and that string is of length 1. v. Basis 2: ε is a RE, and L(ε) = {ε}. v. Basis 3: f is a RE, and L(f) = { }.
RE’s: Definition – (2) v. Induction 1: If E 1 and E 2 are regular expressions, then E 1+E 2 is a regular expression, and L(E 1+E 2) = L(E 1) L(E 2). v. Induction 2: If E 1 and E 2 are regular expressions, then E 1 E 2 is a regular expression, and L(E 1 E 2) = L(E 1)L(E 2). Concatenation : the set of strings wx such that w Is in L(E 1) and x is in L(E 2).
RE’s: Definition – (3) v. Induction 3: If E is a RE, then E* is a RE, and L(E*) = (L(E))*. Closure, or “Kleene closure” = set of strings w 1 w 2…wn, for some n > 0, where each wi is in L(E). Note: when n=0, the string is ε.
Precedence of Operators v. Parentheses may be used wherever needed to influence the grouping of operators. v. Order of precedence is * (highest), then concatenation, then + (lowest).
Examples: RE’s v. L(01) = {01}. v. L(01+0) = {01, 0}. v. L(0(1+0)) = {01, 00}. v. Note order of precedence of operators. v. L(0*) = {ε, 0, 000, … }. v. L((0+10)*(ε+1)) = all strings of 0’s and 1’s without two consecutive 1’s.
Theorem: A language is regular if and only if it is accepted by a regular expression. Proof: Show to convert from regular expression to NFA and vice-versa. Let L be accepted by a regular expression. We prove that it is regular, i. e. , there is a NFA for L. Cases to consider: (1) empty-set (2) single symbol {a} (3) {e} (4) (a) R 1 + R 2 (b) R 1. R 2 (c) R 1* (1), (2) and (3) are easy base cases. For (4), inductively construct NFA’s for R 1 and R 2, and from it construct an NFA for R.
Induction step is shown in the next theorem.
Theorem: The set of Regular languages is closed under the three operations concatenation, union and Kleene star. Proof: (by construction) Union: Given DFA’s M 1 and M 2 for L 1 and L 2, we design a NFA for L 1 U L 2. s 1 e s 2 M 1 M 2
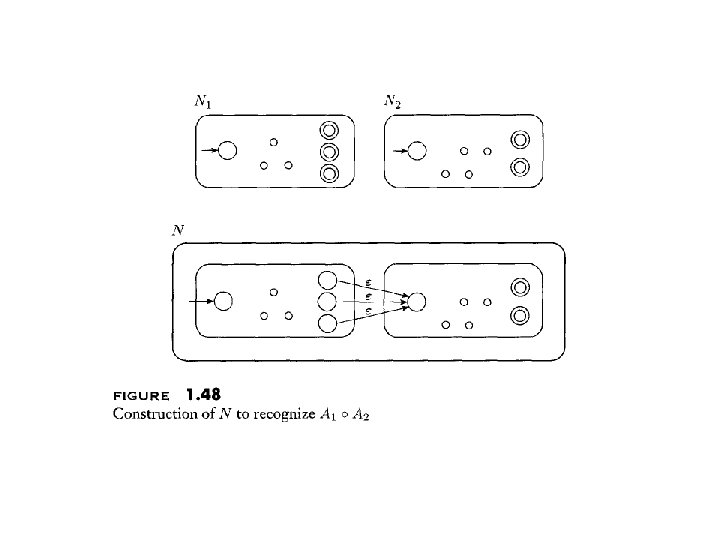
Concatenation:
Concatenation – Formal Proof
Closure under Kleene star – informal proof DFA for a language L is shown on the left. The NFA for L* can be constructed as shown on the right.
Converse is shown as follows: Given a DFA (or NFA), we remove states one by one until we have one state left. At this point, we can write down the regular expression. The idea is to use generalized NFA, one in which the transitions are labeled not by a single symbol, but by a regular expression. Example of GNFA:
Conversion from DFA to regular expression Key step: how to remove a state of a GNFA
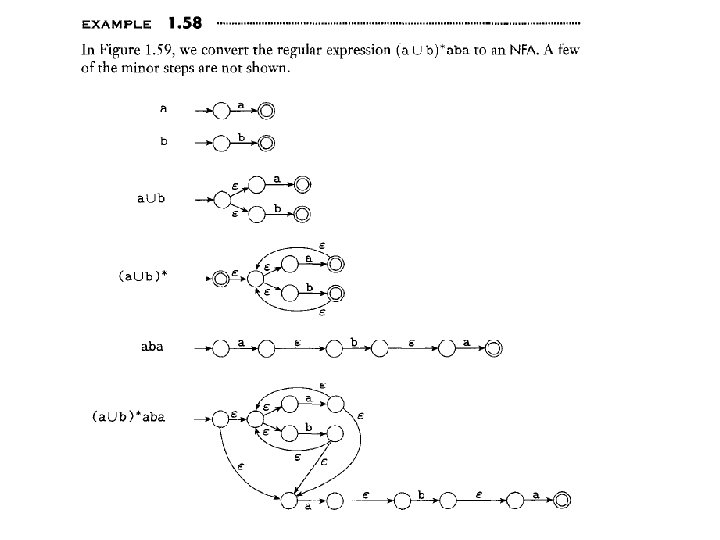
So far, we have seen how to design DFA, NFA or regular expressions for various languages. We also learned how to convert: • e-NFA • NFA -> DFA • DFA regular expression • Regular expression NFA