Information Extraction Distilling Structured Data from Unstructured Text









 A finite-state")









- Slides: 21
Information Extraction: Distilling Structured Data from Unstructured Text. -Andrew Mc. Callum Presented by Lalit Bist
Overview n n Information extraction to rescue A Tour of Examples Applications Mine the text Directly Information extraction the web and future.
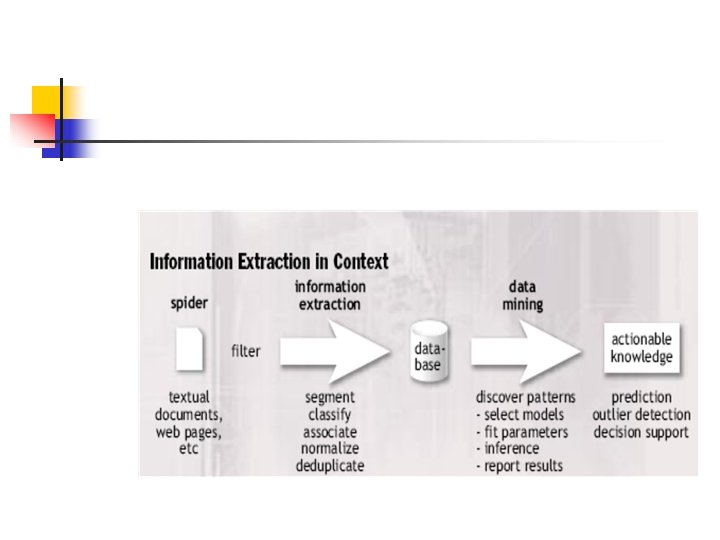
Information Extraction n Is the process of filling database records with unstructured or loosely formatted text. Information extraction populates a database from unstructured or loosely structured text; data mining then discovers patterns in that database. Information extraction involves five major subtasks.
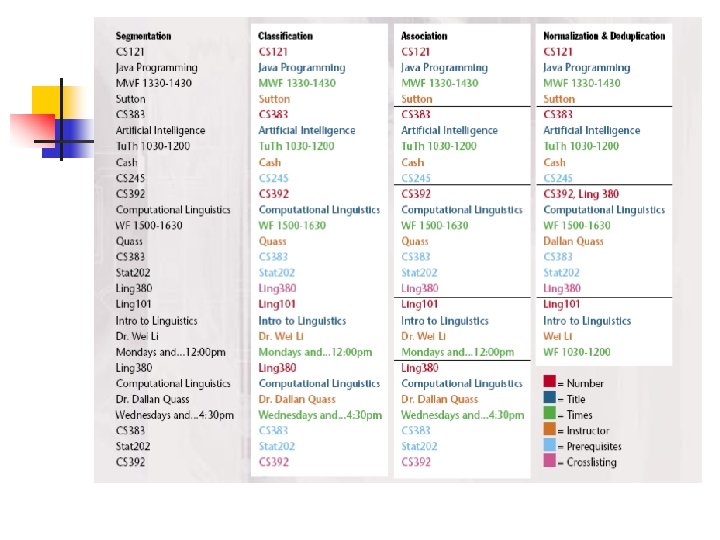
Component of Information Extraction n n Segmentation finds the starting and ending boundaries of the text snippets that will fill a database field Classification determines which database field is the correct destination for each text segment.
Component of Information Extraction n Association It determines which fields belong together in the same record. It is sometimes referred to as relation extraction for the case in which two entities are being associated. Normalization puts information in a standard format in which it can be reliably compared. Reduplication collapses redundant information so that there is no duplicate records in database.
Example Applications n n Filipdog. com -job search website - it claimed having twice as many job opening in its database as monster. com -it automatically extracted its job openings directly from more than 60 K company websites Zoom. Info. com – Extracts information about people one the web creating cross referenced records name, job titles, employment histories and educational background.
Example applications n n Cite. Seer. org extracts citation information from academic research papers, including the paper’s title, publication venue, year, etc. Verity. com: Meci. Claim can extract various field from medical insurance claim forms, enabling semi-auto-mated processing and faster throughput.
How they do it? n n By writing regular expressions Hand-tuned programmed rules. The words, word order, grammar Statistical and machine-learning methods. -these are methods that automatically tune their own rules or parameters to maximize performance on a set of example texts that have been correctly labeled by hand.
How they do it? n n Statistical Model: HMM( hidden Markov model) A finite-state machine whit probabilities on the state transitions and probabilities on the per-state word emissions. Widely used in the 1990 s for extraction from English prose. States of the machine are assigned to different database fields, and the highest-probability state path associated with a sequence of words indicates which sub-sequences of the words belong to those database fields.
How they do it? n n Some of these machine-learning methods use decision trees or if-thenelse rules. These approach is often followed in systems that use machine learning to create formatting-based extractors (called wrappers).
Are these methods perfect? n n It depends on the regularity of the text input and the strength of the extraction method used. Extraction from the somewhat regular text, such as postal address blocks or research paper citations, percentage accuracy in the mid –to high -90 s. Extracting protein name more difficult, accuracies in a recent competition were 80 s. Deduplication, increases the accuracy.
Shop around before you buy. n n Is the product an unchangeable black box? How much can you tune the extractor to your own purposes? If you can tune it yourself, how? By writing rules? How flexible is this rules language? What subtleties will it let you capture? Does it let you express weights or “votes” on certain outcomes? How does it capture dependencies and conflicts among the rules?
Shop around before you buy. n n Can you train it using machine learning? That is, if you can tune it yourself, can you do so by providing examples of data with correct answers (and have the extractor self-tune with machine learning)? What machinelearning methods are employed, and how flexible are the features it uses ? Is it designed mostly for leveraging HTML formatting regularities? Does this paradigm match your needs?
Upcoming Trends and Capabilities n n Estimating uncertainty, managing multiple hypotheses. Easier training, semi-supervised learning, interactive extraction.
Alternative Variation: Mine text Directly n n Instead of building structured database it suggests to use loose mixture of text extracting and data mining. These methods leverage whatever limited structured information is available and use data mining tool that are robust enough to operate directly on the raw text.
Information Extraction , The Web and The Future n n n WWW is largest repository of the knowledge. But it is not in database form with records and fields that can be easily manipulated and understood by Computers. In future machine access the immense knowledge base, and we will be able to perform pattern analysis, knowledge discovery, reasoning and semi-automated decision making. Information extraction will be a key part to make this possible.
n Questions? ?
Refrences n n n Mc. Callum, A. , Corrada-Emanuel, A. , and Wang, X. 2005. Topic and role discovery in social networks. International Joint Conferences on Artificial Intelligence. Lafferty, J. , Mc. Callum, A. , and Pereira, F. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of the ICML: 282– 289 Klein, D. , Smarr, J. , Nguyen, H. , and Manning, C. 2003. Named entity recognition with character-level models. Proceedings of the Seventh Conference on Natural Language Learning.