High Performance Clickstream Analytics with Apache HBasePhoenix CDK
")
High Performance Clickstream Analytics with Apache HBase/Phoenix - CDK Global (formerly ADP Dealer Services)

About Me • Arun Thangamani - Software Architect, BI • Past • Technical Lead, Monsanto • R&D – Technology Pipeline • Senior Software Engineer, Caliper • Software Engineer, Yahoo • University of Alabama – MS Computer Science • R&D, Space Research Labs • Arun. Thangamani@gmail. com, Arun. Thangamani@cdk. com • Twitter : @Arun. Thangamani • Joined By • Chris Chang – Senior Manager, BI • Peter Huang – Director, BI • CDK Team • Philippe Lantin, Nima Imani, Amit Phaltankar, Sundara Palanki, Pradip Thoke, Kim Yee, Shridhar Kasat, Clifton May, Bruce Szalwinski, Branden Makana, Anand Joglekar

Topics Overview • About CDK Global Ø Clickstream Analytics Use Case • Architecture Ø HBase Logical and Components Overview Ø HBase and Phoenix Aggregation Ø Timestamp Handling in HBase/Phoenix • Fundamental Results Achieved Ø Demo with Apache Zeppelin • Phoenix – Scans, Joins and Secondary Indexes Ø Current and Future of Clickstream Analytics Use Case • Performance Optimization Variables Ø Comparison Metrics
 • Provide Integrated Technology Solutions to ~30, 000")
CDK Global (formerly ADP Dealer Services) • Provide Integrated Technology Solutions to ~30, 000 dealers across the world • Dealers • Auto, Truck, Motorcycle, Marine, Recreational Vehicles and Heavy equipment • For the purpose of this presentation, we are interested • Dealer Web Sites and Clickstreams from web sites • CDK Overall Deals with Various Types Data including (not limited to) • Inventory, Sales, Services, Organization Data • Customers, Advertisement/Impressions Data • Auctions, Open Domain Data, Partner Programs

Clickstream Analytics – Use Case • Widget Experience

Clickstream Analytics – Widget Use Case Derived User Intent Dealer Website Pages Interactive Widget-1 Widget-2 Widget (N-1) Widget-N User Activity/Flow Path ETL Process User Session Data External Systems & Partner Programs Service Layer CDK Cookie Jar & Intent Rule Engine Search Engines/ Ads/Campaigns 1. 5 B entries for 60 days, 25 M per day, Filter & Aggregate 1 -3 M entries per dealer report page Dealer Widget Analytics & Customization Widget Experience Performances Potential Buyer Dealer

Clickstream Analytics – Widget Experience Fundamentals • Widget Experience • Webpage Widgets ‘react’ to User Intent –> deliver experience • Dealer Analytics • Effectiveness of Widget Experiences and Optimizations • 60 days worth of data • One day load => ~25 M rows => ~1. 5 B rows total • Data intake in random chronographic order • Report => aggregate with relatively ‘light’ to ‘heavy’ filtering • Challenges • Can we keep the report interactive and live? • How do we delete/expire data?

HBase – Quick Overview HBase – Table NOSQL Key Value Store • Column family oriented store PK • Highly scalable with no central index rowkey-1 • Open source re-incarnation of Big. Table • Great for Aggregating large amounts of data • Fully Consistent rowkey-2 Column Family -1 colname-1 value-2 timestamp-2 colname-1 value-1 timestamp-1 colname-2 value-2 timestamp-1 colname-3 value-3 timestamp-4 … … …. colname-1 value-5 timestamp-4 colname-5 value-1 timestamp-1 colname-6 value-2 timestamp-0 … … …. Handle Billions of these with Ease? . How?

HBase Architecture HBase Table – 1 to N regions Region-1 Region-2 a g h n Region-3 Region-4 o s u z Create/Delete /Split Table Operations HBase Master S T A N D B Y META Cache First Call HBase Reads Connect to Zookeeper Find. Meta Cache Meta Data Find Region/Region-Server Check Memstore Check Block Cache Find HFiles with Bloom Filter Use Block Index to find Block Scan Block to find row Place Block in Block Cache HBase Writes Connect to Zookeeper Find. Meta Cache Meta Data Find Region/Region-Server Add Data to Memstore & WAL Memstore Flush New HFile(s) created Zoo Keeper Region-3 Region Server 1 Major/Minor Compactions HFiles merged Recovery Lost HFiles from HDFS Replay WAL to Memstore Second Call . META Region Server 2 Client Third Call for Write Read Zoo Keeper Block Cache Region Server 3 Memstore Zoo Keeper Region-1 Region-4 Region Server 5 Region-2 HFile(s) HDFS WAL HDFS

HBase - Finding data within Region Files Region Blocks and Bloom Filter aa Block Range aa – ab Data Block & Size aa – ab Block Indexes to HFile 1 Region HFile 2 HFile 3 ay – az az Bloom Filter Primary Keys in HFile 1 AACL AARF Bloom Filter Sample Row Key Bloom Hash 1 X X X � X Hash 2 Hash 3 AAXY 1. 2. X X X For Range scans, block indexes are used For specific row retrieves use Bloom Filter first X � X✴ � X Check if exists AAXY Hash 3 marker is empty; So, it doesn’t exist in HFile 1 Bloom Filter 1. 2. 3. 4. 5. 6. 7. X Instead of checking all HFiles in depth, look at Row Bloom Filter of each File Assume - Bloom Filter has 3 way hash (usually N=>deterministic) For any key, mark the relevant bucket on 3 hash’s If all relevant hash buckets are not filled up, the key doesn’t exist If all relevant hash buckets are filled up, the key might exist – high possibility No false negatives, but false positives possible More Hash’s and more hash buckets => more certainty

Widget Semi Aggregated Table – Core Table widget-pages-stats dealer-user details dealer id page label timestamp device user Type segments widget details id primary filter type version aggregate-stats context stats-1 clicks stats-2 views stats-3 hover stats-4 …. stats-5 …. … … final group- by primary key * Total size of table – 1. 5 Billion Dealer will have ~ [100, 000 to 4, 000] rows secondary Filter

HBase – Aggregation aa – ab … yb – yc Block Index Region-1 Region-26 bu – bz yl – ym REGION SERVER -1 ca – cb widget-pages-stats primary key … SAMPLE TARGET DATA & AGGREGATION values dealer page time device widget stats-1 Stats-4 id label stamp Type id type version context Region-2 cw – cy … HBase works on Ordered key Storage Ordered key storage creates large/hot Regions for aggregation zb – zc REGION SERVER -2 … … em – en 2 ways to address the problem in Phoenix a. Phoenix Guide Posts b. Phoenix Salted Buckets Region-27 HFile -1 HFile -2 HFile -3 Concatenated Composite Primary Key 1. 2. ym – yn Region-5 zc – zd Region-30 ex – ew zx – zz REGION SERVER -5 A G G R E G A T I O N S F O R C L I E N T

Phoenix Aggregation Region-1 a Region-29 Region-2 Region-30 y …. . c z b 1. 2. Client Phoenix Table Using Guide-Posts for parallel scan and aggregation Client Phoenix Salted Table for parallel scan and aggregation HBase works on Ordered key Storage Ordered key storage creates large/hot Regions for aggregation 2 ways to address the problem in Phoenix a. Phoenix Guide Posts b. Phoenix Salted Buckets a b a b c c …. . z z Region-1 z Region-29 Region-30

Phoenix – Salted Buckets Aggregation Initially Regions = Salted Buckets a – b … a – b TARGET DATA Region-1 Region-26 x – z REGION SERVER -1 a – b SAMPLE TARGET DATA & SAMPLE AGGREGATION TARGET DATA & AGGREGATION Block Index widget-pages-stats primary key values dealer page time device widget stats-1 Stats-4 id label stamp Type id type version context … Region-27 Region-1 x – z a – b TARGET DATA HFile -1 HFile -2 HFile -3 … a – b Aggregation data retrieval – we have minimized the disk seeks and block transfers to a few per region server F O R REGION SERVER -2 … … Concatenated Composite Primary Key x – z a – b TARGET DATA Region-5 Region-30 x – z x - z REGION SERVER -5 A G G R E G A T I O N S C L I E N T

Phoenix – Overview Phoenix - SQL Abstraction PK Col-1 Col-2 Col-3 rowkey-1 value-2 value-3 client connection timestamp-1 • Born at Salesforce by James Tylor & Mujtaba Chohan • Phoenix works on top of HBase • Puts back the SQL on top of HBase • Phoenix makes HBase more usable with less code HBase - NO SQL Key Value Store PK rowkey-1 Column Family -1 col name - 1 value-1 timestamp -1 col name - 2 value-2 timestamp -1 col name - 3 value-3 timestamp -1 … … ….

Architecture – Phoenix Client JDBC calls Create/Delete /Split Table Operations HBase Master Zoo Keeper Phoenix Phoenix Region Server 1 Region Server 2 Region Server 3 Region Server 4 Region Server 5 Phoenix Layer Dynamic Coprocessors Dynamic Observers Coprocessors – execute aggregation Observers – Various Types – observe to sync data HDFS

Timestamp Handling in HBase

Timestamp and Expiration Handling row-key cf 1: c 1 r 1 t 1 cf 1: c 2 HFile: cf 1 (r 1: cf 1: c 1: t 1: value) r 2 t 3, t 2, t 1 r 3 t 1 r 4 cf 1: c 1 (r 2: cf 1: c 2: t 3: value) (r 2: cf 1: c 2: t 2: value) (r 2: cf 1: c 2: t 1: value) t 3 (r 3: cf 1: c 2: t 1: value) (r 4: cf 1: c 1: t 3: value) d 1 t 1 d 2 t 2 d 3 t 3 Day 4 d 4 t 4 HFile: cf 1 (r 1: cf 1: c 1: t 1: value) (r 1: cf 1: c 1: t 4: value) (r 2: cf 1: c 2: t 3: value) (r 6: cf 1: c 2: t 4: value) (r 2: cf 1: c 2: t 2: value) (r 3: cf 1: c 2: t 1: value) (r 3: cf 1: c 2: t 3: value) (r 1: cf 1: c 1: t 4: value) Major Compaction (r 2: cf 1: c 2: t 1: value) Table A Time To Live = 3 days HFile: cf 1 Expired data is Auto Filtered On Retrieve (r 2: cf 1: c 2: t 3: value) (r 2: cf 1: c 2: t 2: value) (r 3: cf 1: c 2: t 3: value) (r 6: cf 1: c 2: t 4: value)

Phoenix/HBase Implementation • Choose Salt bucket tables • Compensate for ‘hot regions’ • Parallel filtering in regions • Utilize parallel aggregation => regions aggregate before final merge in client • Utilized the timestamp feature of HBase • Set Time to Live at Table level, entries are time-stamped • Expired data will be auto filtered during reads • Expired data deleted along with old HFiles during major compaction • Total 5 Nodes – Appendix-B for full specifications

Demo – Fundamental Use Case
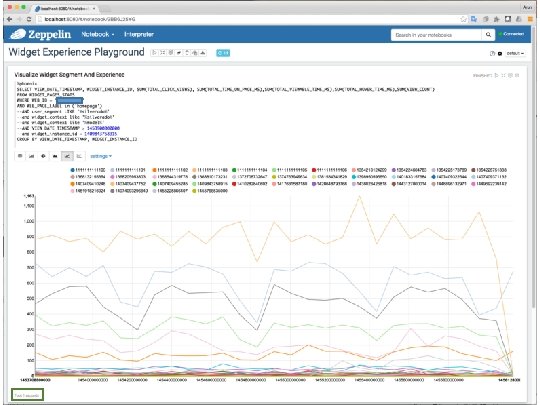
 Widget Experience Report Performance Random Dealer Id aggregation for 30 days of data")
Time(MS) Widget Experience Report Performance Random Dealer Id aggregation for 30 days of data – Warm Cache 30 days is our default report Filtering on dealer specific attributes Group-by on 4 different Widget Attributes (relatively high return data) Total Region Severs – 5 < 1 s response time for 2 M rows group-by with 4 attributes Filtering is cheaper and group-by relatively expensive More rows filtered => the faster response Please Note : for simple group-by aggregate queries, phoenix probably might respond in <1 s for about 4 -5 M rows

Scans, Joins and Secondary Indexes widget-pages-stats user details dealer id page label Time stamp widget details aggregate-stats device user id type version context stats-1 stats-2 stats-3 stats-4 stats-5 Type segments clicks views hover …. …. widget-details id type version context start date end target widget date campaign name details Simple Hash Join Or Sort Merge Join widget-pages-stats-secondary-widget-index widget details Phoenix – “Covered Global Secondary Index” A Secondary Table is maintained in Parallel with Original Table user details id type version context dealer id page label Secondary index Time stamp aggregate-stats device user stats-1 stats-2 Type segments clicks views Covered Columns …

Scans, Joins and Secondary Indexes Skip Scan & Join widget-pages-stats dealer-id page-label abcd Home. Page abcd Vehicle. Search. Page abcd Vehicle. Details widget-pages-stats widget-details Range dealer id scan manufacturer-dealer-1 & manufacturer-dealer-2 Join. . manufacturer-dealer-n id type version context start date end target widget date campaign name details … widget-pages-stats-covered-index widget id 10000100001001 100001002 …. 200001001 200001002 Range Scan & Join on Covered Index Skip Scan in Phoenix Utilizes HBase SEEK_NEXT_USING_HINT Skips to the next correct intra region key column Will also use guide posts (if available)

Performance Optimizations

Performance Improvement Variables Block Size, Block Encoding and Block Compression Sample HFile Data Block: cf 1 Block Range aa – ab Data Block & Size Block Indexes r 1: cf 1: c 1: t 60: value r 1: cf 1: c 1: t 59: value ………. r 1: cf 1: c 1: t 01: value HFile ay – az HFile Logical View r 1: cf 1: c 2: t 60: value r 1: cf 1: c 2: t 59: value ………. r 1: cf 1: c 2: t 01: value ……… r 1: cf 1: c 15: t 59: value ………. r 1: cf 1: c 15: t 01: value Special Encoding to eliminate dups (PREFIX-TREE, FAST-DIFF) Compression post Encoding (LZ 4, GZ, SNAPPY)

Performance Optimization Variables Phoenix • Number of Salt Buckets • Width of Guide Posts • Selecting Primary keys • • proper filter keys, proper group-by keys light weight primary key • Query Plan • • • Usage of skip scans Parallel scan using guide posts Utilizations of Secondary indexes • Phoenix Query • Memory Utilization settings HBase • Compression • • Data Block compression GZ, LZ 4, SNAPPY • Encoding • • Data Block Encoding FAST DIFF and PREFIX TREE • HBase Block Size • • Data block is minimum data read into region server Data block is cached in Block Cache

Performance Optimizations – Encoding, Compression, Buckets/Regions Number of Salt Buckets - Aggregation Performance Number of Salt Buckets - Write Time for 1. 5 B rows 1600 1428 1400 1072 1000 Time (MINS) time (MS) 500 1218 1200 897 800 600 477 415 400 382 time (mins), 342 45 buckets 60 buckets 300 200 400 100 200 0 0 20 buckets 30 buckets 45 buckets 60 buckets 20 buckets 30 buckets * These numbers could change based on data size from each node HFile Block Size Aggregation Performance Data Block Encoding Aggregation Performance 1072 800 10% 957 600 400 1000 TIME (MS) 1000 1200 800 400 200 0 0 1 MB BLOCK 8% 991 600 200 64 KB BLOCK 1600 1072 1400 1200 TIME (MS) 1200 Compression - Aggregation Performance [VALUE] 1000 23% [VALUE] 800 600 400 [SERIES NAME] [VALUE] 200 0 FAST-DIFF PREFIX-TREE GZ LZ 4 SNAPPY

Appendix – A Evolution of Clickstream ETL Pipeline DIM SOURCES Worst Case Scenario Per Day 25 M rows total Time to Phoenix – 1 hrs Insert into Phoenix – 5 mins Apache-1 DIM-2 DIM-3 DIM-4 FACT_ WIDGET _EVENTS DIM-5 DIM-6 DIM-7 DIM-8 Apache-2 Apache-3 Kafka Spark Based Reduce H D F S Apache-N Map Reduce HBase/ Phoenix Present Past Apache-1 DIM-2 DIM-3 DIM-4 FACT_ WIDGET _EVENTS DIM-5 DIM-6 DIM-7 DIM-8 Apache-2 Apache-3 File Mounts Spring Batch DB Dedup Standalone Java App Document Caching Store Apache-N DIM SOURCES Worst Case Scenario Per Day 25 M rows total Time to Cache – 6 hrs Insert into Cache – 90 mins

Appendix-B Cluster Hardware Name Node, Resource Manager, HBase Master Primary & Secondary Ambari, Hue, Knox Ranger, Nagios, Ganglia, Oozie, History Server, Falcon, Hive 2 Edge Nodes 10 GB - Ethernet Switch Data Node 1 Region Server 1 256 GB RAM 24 GB RAM for RS 25 * 1 TB Disks 10000 RPM 24 Cores 2. 7 GHz Data Node 2 Region Server 2 256 GB RAM 24 GB RAM for RS 25 * 1 TB Disks 10000 RPM 24 Cores 2. 7 GHz Data Node 3 Region Server 3 256 GB RAM 24 GB RAM for RS 25 * 1 TB Disks 10000 RPM 24 Cores 2. 7 GHz Data Node 4 Region Server 4 256 GB RAM 24 GB RAM for RS 25 * 1 TB Disks 10000 RPM 24 Cores 2. 7 GHz Data Node 5 Region Server 5 256 GB RAM 24 GB RAM for RS 25 * 1 TB Disks 10000 RPM 24 Cores 2. 7 GHz

Questions?
- Slides: 31