Fusion of Multiple Corrupted Transmissions and its effect













- Slides: 14
Fusion of Multiple Corrupted Transmissions and its effect on Information Retrieval Walid Magdy Kareem Darwish Mohsen Rashwan
Outlines 1. Motivation 2. Prior work 3. Fusion Definition 4. Approach 5. Experimental Setup 6. Results 7. Conclusion & Future work
Motivation • Many Arabic documents are available only in print form. • The need of transforming these documents into electronic form increased since the end of last century, where searching E-text is much easier. • Arabic OCR accuracy is still much lower than the state-of-the-art for other languages, such as English. • Degraded text, resulting from OCR systems, affects the effectiveness of Information Retrieval. • The need for having higher quality text for Arabic documents became a must for improving IR effectiveness.
Prior Art: • Previous work on OCRed text focused on two main aspects: 1. Work involves improving Information Retrieval effectiveness regardless of improving text quality. 2. Work focuses on improving text quality leading to improvement in IR effectiveness. • Examples: 1. Query garbling based on character error model. 2. OCR correction based on character error model and Language model.
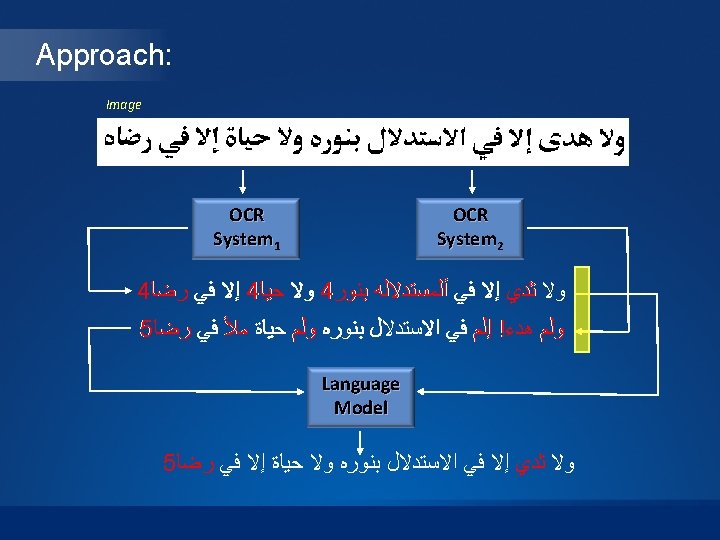
Fusion Definition: Simage Degraded version of text OCR Clean version of text Sx = S 0 + ε x Noisy edit operations • Previous approaches depends on the presence of only one source of degraded text. Sx = S 0 + ε x Correction S 0 ’ = S 0 + ε 0 ’ ε 0’ < ε x • Our approach assumes the presence of more than one version of the degraded text. S 1 = S 0 + ε 1 S 2 = S 0 + ε 2 Sn = S 0 + ε n Fusion S 0 ’ = S 0 + ε 0 ’ ε 0’ < min(ε 1 … εn)
Experimental Setup: • Only one OCR system was available “Sakhr Automatic Reader v 4”. • In order to obtain multiple sources for a given data set: 1. Few pages were selected at random from a book, OCRed, then outcome text was manually corrected. 2. Degraded and Clean text were used to create a character error model based on 1: 1 character mapping. 3. Generated model is then used to garble a clean text using different CER’s. • Used OCRed book for test was Zad Alma’ad, with the following specs: 1. Eight pages scanned at 300 x 300 dpi that contain 4, 236 words, with CER of 13. 9% and WER 36. 8%. 2. Clean version of the book was available in electronic form that consists of 2, 730 separate documents. Associated a set of 25 topics and relevance judgments. • LM is built using a web-mined collection of religious text by Ibn Taymiya, the teacher of the author of Zad Alma’ad • MAP was used as the figure of merit for IR results.
Experimental Setup: Generating Synthetic Garbled Data • For a clean word “ ”ﻗﻨﺒﻠﺔ ﻕ Generate random number ﻗـﻗـﻨـﺒـﻠـﺔ Garbler ﺗـﻨـﺒـﻠـﺔ Character Error Model 0. 921 ﻕ 0. 0 ﻑ 0. 8 ﻥ ﺕ 0. 95 1 ﻕ ﻑ ﺕ ﻥ 0. 8 0. 1 0. 05
Experimental Setup: Generating Synthetic Garbled Data CERnew k= CERorg ﻕ ﻑ 0. 0 ﻑ 0. 6 0. 0 ﻕ k = 0. 5 ﺕ 0. 8 ﻥ 0. 9 1 ﻥﺕ ﻑ 0. 975 0. 95 0. 0 0. 95 1 0. 8 ﻕ k=2 ﻥ ﺕ 1
Experimental Setup: Generated Versions Data set k CER WER OOV Original NA 13. 9% 36. 8% 20. 9% Model-1 1 13. 9% 36. 3% 21. 1% 13. 9% 36. 4% 21. 1% Model-2 0. 5 7. 0% 20. 3% 11. 9% 7. 0% 20. 4% 11. 9% Model-3 0. 67 9. 3% 26. 1% 15. 2% 9. 3% 25. 9% 15. 2% Model-4 1. 25 17. 4% 43. 2% 25. 0% 17. 4% 43. 3% 24. 9% Model-5 2 27. 9% 59. 2% 33. 8% 27. 9% 59. 2% 33. 7% Error rates for generated versions Model-1 Model-2 Model-3 Model-4 Retrieval results for generated versions Model-5
Results: Fusion Results WER after fusion of both versions Common Errors between versions WER for outcome text from fusion process between couples of versions
Results: Retrieval Results in MAP of searching different fused models, hashed bars refers to statistical significant retrieval results better than the original degraded versions
Conclusion & Future Work: • Text fusion proved to be an effective method for selecting the proper word among different candidate words coming from different sources. • Effectiveness of text fusion on WER reduction depends on the percentage of error overlap among different versions. • Information retrieval improvement as a cause of text fusion was found to be promising specially for the few outcome versions that are statistically indistinguishable from the clean version. • As a future work, fusion technique needs to be tested on real degraded data coming from different sources that will introduce a new challenge, which is word alignment among different sources.