Divya Kamboj Presentation 1 Introduction1 1 3 Introduction
")
Divya Kamboj Presentation #1 Introduction(1 -1. 3)

� Introduction � Distributed Data Processing � What is a Distributed Database System � Data Delivery Alternatives

� Distributed database technology attempts to achieve integration without centralization. � Distributed database system (DDBS) technology is the union of what appear to be two diametrically opposed approaches to data processing: database system and computer network technologies
 that")
� Distributed computing is the number of autonomous processing elements (not necessarily homogeneous) that are interconnected by a computer network and that cooperate in performing their assigned tasks. � The “processing element” referred to in this definition is a computing device that can execute a program on its own.

One of the things that might be distributed is the processing logic. � Another possible distribution is according to function. Various functions of a computer system could be delegated to various pieces of hardware or software. � A third possible mode of distribution is according to data. Data used by a number of applications may be distributed to a number of processing sites. � Finally, control can be distributed. The control of the execution of various tasks might be distributed instead of being performed by one computer system. From the viewpoint of distributed database systems, these modes of distribution are all necessary and important. �

� From a more global perspective, however, it can be stated that the fundamental reason behind distributed processing is to be better able to cope with the large-scale data management problems that we face today, by using a variation of the well-known divideand-conquer rule. � If the necessary software support for distributed processing can be developed, it might be possible to solve these complicated problems simply by dividing them into smaller pieces and assigning them to different software groups,

� Distributed database as a collection of multiple, logically interrelated databases distributed over a computer network. � A DDBS is not a “collection of files” that can be individually stored at each node of a computer network. To form a DDBS, files should not only be logically related, but there should be structured among the files, and access should be via a common interface
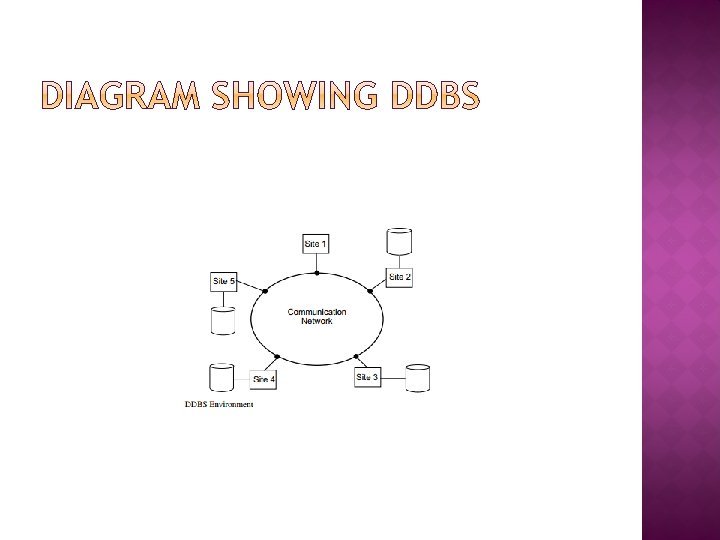

� In Distributed databases, data are “delivered” from the sites where they are stored to where the query is posed. � We characterize the data delivery alternatives along three orthogonal dimensions: delivery modes, frequency and communication methods. � The combinations of alternatives along each of these dimensions (that we discuss next) provide a rich design space.

� The alternative delivery modes are pull-only, push-only and hybrid. � In the pull only mode of data delivery, the transfer of data from servers to clients is initiated by a client pull � Pull is used extensively on the Internet for HTTP page requests from websites. � In the push-only mode of data delivery, the transfer of data from servers to clients is initiated by a server push in the absence of any specific request from clients. � The hybrid mode of data delivery combines the client-pull and server-push mechanisms.

� There are three typical frequency measurements that can be used to classify the regularity of data delivery. � They are periodic, conditional, and ad-hoc or irregular. � In periodic delivery, data are sent from the server to clients at regular intervals � In conditional delivery, data are sent from servers whenever certain conditions installed by clients in their profiles are satisfied. � Ad-hoc delivery is irregular and is performed mostly in a pure pull-based system. Data are pulled from servers to clients in an ad-hoc fashion whenever clients request it

� The third component of the design space of information delivery alternatives is the communication method. � These methods determine the various ways in which servers and clients communicate for delivering information to clients. � The alternatives are unicast and one-to-many. � In unicast, the communication from a server to a client is one-to-one: the server sends data to one client using a particular delivery mode with some frequency. � In one-to-many, the server sends data to a number of clients.

ANY QUESTIONS? ? ?
- Slides: 13