CLASSIFICATION DISCRIMINATION LECTURE 15 What is Discrimination or







 > L(x,")
rule: Choose P 1 if b’x – k > 0")

>P(P 2|x) where, P(Pi|x) =")








 the cost of misclassifying an")
 • Most classification methods can be described as special implementations")

")





 • • Easy useful method. Been found to be robust in")
 • Assumption: samples with almost the same feature should belong")
![lda example from R • • Iris <- data. frame(rbind(iris 3[, , 1], iris](https://slidetodoc.com/presentation_image_h/2dddce75a300608f72a18d076a9ad04a/image-32.jpg "lda example from R • • Iris <- data. frame(rbind(iris 3[, , 1], iris")

)")

![knn • • • library(class) > train <- rbind(iris 3[1: 25, , 1], iris](https://slidetodoc.com/presentation_image_h/2dddce75a300608f72a18d076a9ad04a/image-36.jpg "knn • • • library(class) > train <- rbind(iris 3[1: 25, , 1], iris")
- Slides: 36
CLASSIFICATION DISCRIMINATION LECTURE 15
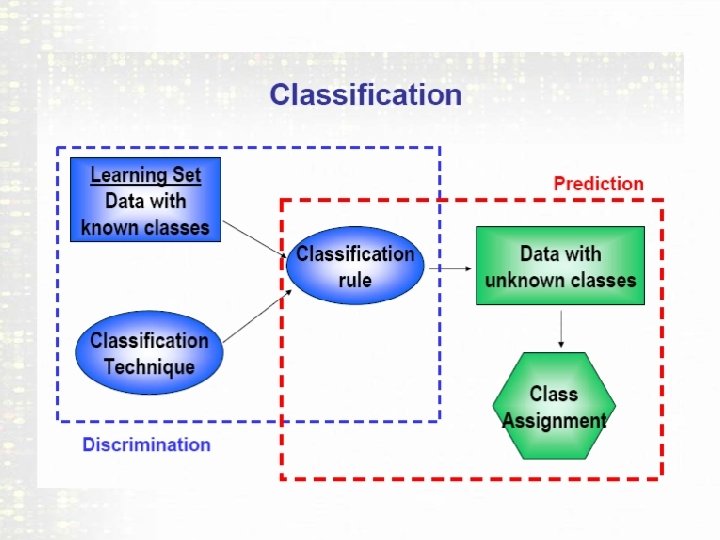
What is Discrimination or Classification? • Consider an example where we have two populations P 1 and P 2 each ~ N(m 1, s 1) and N(m 2, s 2) respectively. • A new observation is observed and it is known to come from either of these populations. • The task of a discriminant function is to determine a “rule” to decide from which of the two populations x is most likely to come from. • How we come up with a rule is what we need to study.
Supervised Learning • In computer Science this is known as SUPERVISED learning. • Essentially we know the class labels ahead of time. • What we need to do is find a RULE using features in the data that DISCRIMINATES effectively between the classes. • So that if we have a new observation with its features we can correctly classify it.
Example 1 • Suppose you are a doctor considering two different anesthetics for a patient. • You have some information about the patient, gender, age, some medical history variables. • So what we need is a data set where we have patient information and whether or not the anesthetic was SAFE for that patient. • So what you want to do is USING the available variables build a MODEL or RULE that says whether anesthetic A or B is better for the patient. • Then use this rule to decide whether or not to give the new patient A or B.
Example 2: Turkey Thief • There was this legal case in Kansas where a turkey farmer accused his neighbor of stealing turkeys from the farm. • When the neighbor was arrested and the police looked in the freezer, there were multiple frozen turkeys there. • The accused claimed these were WILD turkey that he had caught. • The Statistician was called in to give evidence as there are some biological differences between domestic and wild turkey. • So the biologist measured the bones and other body characteristic of the domestic and Wild turkeys and the Statistician built a DISCRIMANT function. • They used the classification function to see if the turkeys in the freezer fell into he WILD or DOMESTIC class. • THEY ALL fell in the DOMESTIC classification!
The Idea • USING knowledge of the classes we build the FUNCTION. • We want to minimize misclassification error. • Question: Should we use ALL the data to build the MODEL, because then we really do not have a good way to find out the misclassification probabilities. • Generally: Training set and Testing sets are used.
Some common Statistical Rules • Suppose we want to classify between two multivariate normal distribution P 1 with parameters m 1 and S 1 and P 2 with parameters m 2 and S 2. • Suppose a new observation vector x is known to come from P 1 or P 2. • There are various Statistical Rules allow us to PREDICT which population x most likely came from.
1. Likelihood Rule Choose P 1 if L(x, m 1, s 1) > L(x, m 2, s 2) else choose P 2. Here, x is the observation vector. This is a mathematical rule and reasonable under the assumption of normality.
2. Linear Discriminant Function (LDA)rule: Choose P 1 if b’x – k > 0 and P 2 otherwise. Here b= S-1(m 1 -m 2) and k=1/2(m 1 -m 2)S-1(m 1+m 2) The function b’x is called the linear discriminant function. This assumes equal covariance matrices S 1=S 2=S. It’s a single linear function of x that summarizes all the information in x.
3. Mahalanobis Distance Rule Choose P 1 if d 1 < d 2 where di = (x-mi)S-1(x-mi) for i=1, 2. The function di is a measure of how far away x is from mi taking the Variance-Covariance into account. This assumes equal covariance matrices S 1=S 2=S. The Likelihood criterion under normality and equal variance is equivalent to this Rule.
4. Posterior probability rule Choose P 1 if P(P 1|x)>P(P 2|x) where, P(Pi|x) = exp[(-1/2)di]/{exp[(-1/2)d 1] + exp[(-1/2)d 2] } • Also assumes equal variance. • Not a true probability as (P 1|x) is not a random event as the observation belongs to either P 1 or P 2. • Gives an idea of how confident we are in our effort to discriminate.
Caveats Generally mi and si are not known and we use sample values. Under equal covariance all 4 rules are equivalent in terms of discrimination between groups. Also in general we have more than 2 populations to discriminate the observations into.
Sample Discriminant Rules • Since we never know the parameters m 1, m 2, S 1, S 2. we use sample estimates generally MLE estimates below and form discrimant rules as in given before. •
Estimating Probability of Misclassification • 1. Re-substitution Estimates: Apply the discriminant function to the data used to develop the rule and see how well it discriminates in general. USES the SAME data to make and validate models.
Holdout Data: Keep a part of the data out from the part used to construct the rule and use the rule on that part and see how well it performs. Problem is: if you don’t have a lot of samples its not the most efficient use of resources for building the model.
Cross Validation: Remove one observation at a time from the set, and construct the rule from the remaining observations and predict the first, do this for the second and third… Define a summary matrix for misclassifying each data point. Also called Jack-knifing. • Obviously a rule classifying correctly a HIGHER number of times is preferred.
The Issue for MA • Often it is known in advance WHERE the samples come from and what conditions they have been exposed to. • In fact we are often interested in gene expression profiles to distinguish between different conditions or classes. • In the past schemes like a voting scheme was used to look at class membership in MAs. • MANY methods available, but general consensus is that a few of the methods have robust performance e. g. Linear discriminant Function (LDA), k-Nearest Neighbors (k-NN).
Cost Function and Prior Probabilities • When we there are only two populations all the four rules discussed earlier have the property that probability of misclassifying 1 to 2 is the same as 2 to 1. • NOT generally a good idea especially in our anesthetic example. Idea is if you are going have to err, err in the side of caution. • Hence we need to take into account the COST of misclassification.
Some Math Details • • • Define U = b’x-k from LDA. U=(m 1 -m 2)’S-1 x -. 5 (m 1 -m 2)’S-1 (m 1+m 2) Under Normality and equal variance, if x comes from P 1, U ~ N(d, d) and if x comes from P 2, U ~ N(-d, d) • Where d =(m 1 -m 2)’S-1 (m 1 -m 2) • And our Rule for LDA is P 1 if U > 0 and p 2 otherwise. • To make it asymmetric you can use a rule U > u where we can pick the probability of misclassifying into one of the populations at most a fixed number say alpha.
A General Rule • Define Cost Function as C(i|j) the cost of misclassifying an observation from Pj to Pi. • Define Prior probability as pi for the ith group. • Average Cost of Misclassification (two groups) • p 1 C(2|1)P(2|1) + p 2 C(1|2)P(1|2) • Bayes Rule: Choose P 1 • if p 2 f(x; q 2)C(1|2) > p 1 f(x; q 1)C(2|1) • Observe if p 1=p 2 and C(2|1)=C(1|2) this reduces to the Likelihood rule. • Under Normality and equal variance it reduces to: • d 1* < d 2* where d 1* =. 5(x-m 1)’S-1 (x-m 1) – log(p 1. C(2|1))
Probabilistic Classification Theory (PCT) • Most classification methods can be described as special implementations of Bayes’ Classifiers. The decision rule for classifying x into one of the classes P 1…, Pk depends upon: – Prior information about the class frequencies p 1…pk. – Information about how the class membership affects the gene expression profiles xi (i=1…n) – Misclassification costs C(j, i) of classifying an observation which belongs to class Pi into Pj. • Our aim is to find a classification rule R that minimizes the expected Classification Costs.
PCT II: Bayes Rule • Recall Cost of Misclassification is given by: • C(j|i) = 0 if i=j • = Ci , if i j (generally Ci is set to 1) • Result: the classification rule that minimizes the expected misclassification cost is given by the posterior probability: • R(x) = arg Max P(C|x) = arg Max P(x|C)pc • This is called the Bayes Rule.
PCT III: Prior Information • Hence the idea is: IF we know the Probability of Class membership pc, and the conditional probability of the data given the classifiers P(x|C), we can find the optimum Classification Rule. • In general it is VERY difficult to KNOW the prior information about class membership. • To find P(x|C) the Likelihood of the data, we often use the Normal distribution (or log-transformed gene expression to be Normal). This is done in the Training set.
Steps in Discriminant Analysis in MA • Selection of features: • Model Fitting • Model Validation:
Selection of Features Selecting a set of genes. We do not want all the genes since it may have a tendency to over-fit the data also causes singularity. How to select genes (gene filtering): – Use ONLY differentially expressed genes using an ANOVA type model: xi = a C(xi) + ei – Look at multiple genes or gene groups. Do PCA on all the genes. Not very efficient – Partial least Squares(PLS), finds orthogonal linear combinations that maximize Cov (Xl, y). – Do PCA and then rank PCAs by ratio of between class to within class varaince – Other methods are Projection pursuit etc. Most common differential expression or PLS
MODEL FITTING • Commonly used: • LDA • K Nearest Neighbor • Other related • DLDA (Diagonal LDA) • RDA (Regularized DA) (there is a R package for this) • PAM (Prediction Analysis for Microarrays) (there is a R package for this) • FDA (Flexible DA)
Validation • See how well the classifiers classify the observations into the different classes. • Mostly commonly used method leave-one-out-cross validation. • Though test data set (holdout sample) and resubmissions are still used.
Linear Discriminant Analysis(LDA) • • Easy useful method. Been found to be robust in MA. Idea: The main assumption is that the class densities can be written as Multivariate Normal. • In R one uses lda in the MASS library. • Hence, – P(x| C=k) = MVN ( m 1…mk, Skk) – Maximize : P(C=k| x) ={ P(x| C=k)pk}/S(P(x|C=j)pj – If feature set is known then it is fairly straight forward, else one has to use some technique (forward, backward or step-wise) for feature selection.
K-nearest Neighbor (k. NN) • Assumption: samples with almost the same feature should belong to the same class. In other words given a set of genes (g 1, …, gm) known to be important in class membership, the k. NN classifier assigns an unclassified sample to the class prevalent among the k samples whose expression values for the m genes are closest in the sample of interest. • Typically each profile for sample j, is compared to the other profiles using Euclidean distances (however, any other distance like Manhattan, Correlation can be useful as well). • The aim of k. NN is to estimate the posterior probability P(C(X)=j|X=x) of a gene profile belonging to a class directly. • For a particular k, it estimates the probability as a relative fraction of samples that belong to class j, among the k samples with most similar profiles. • Essentially a non-linear classifier and may have VERY irregular edges.
lda example from R • • Iris <- data. frame(rbind(iris 3[, , 1], iris 3[, , 2], iris 3[, , 3]), + Sp = rep(c("s", "c", "v"), rep(50, 3))) > train <- sample(1: 150, 75) > table(Iris$Sp[train]) • • • c s v 27 24 24 > ## your answer may differ > ## c s v > ## 22 23 30
Running lda • • • > z <- lda(Sp ~. , Iris, prior = c(1, 1, 1)/3, subset = train) > predict(z, Iris[-train, ])$class [1] s s s s s s s c c c [39] c c c v v v v c v v v v Levels: c s v
Contd… • • > (z 1 <- update(z, . ~. - Petal. W. )) Call: lda(Sp ~ Sepal. L. + Sepal. W. + Petal. L. , data = Iris, prior = c(1, 1, 1)/3, subset = train) • • • Prior probabilities of groups: c s v 0. 3333333
Contd… • • • Group means: Sepal. L. Sepal. W. Petal. L. c 5. 955556 2. 781481 4. 359259 s 5. 008333 3. 450000 1. 429167 v 6. 637500 2. 983333 5. 629167 • • • Coefficients of linear discriminants: LD 1 LD 2 Sepal. L. 0. 9045765 -0. 07677002 Sepal. W. 0. 7347963 2. 58009411 Petal. L. -3. 1529282 0. 37700694 • • • Proportion of trace: LD 1 LD 2 0. 9939 0. 0061
knn • • • library(class) > train <- rbind(iris 3[1: 25, , 1], iris 3[1: 25, , 2], iris 3[1: 25, , 3]) > test <- rbind(iris 3[26: 50, , 1], iris 3[26: 50, , 2], iris 3[26: 50, , 3]) > cl <- factor(c(rep("s", 25), rep("c", 25), rep("v", 25))) > knn(train, test, cl, k = 3, prob=TRUE)