Reorganizing and Rebuilding Indexes http Caf naver comsqlmvp

Reorganizing and Rebuilding Indexes http: //Café. naver. com/sqlmvp http: //judydba. tistory. com/ chusouk@gmail. com 010 -7398 -1136 추숙(주디아줌마)

목차 1. 조각화 1. 1 인덱스 조각화란? 1. 2 인덱스 조각화의 발생 원인 1. 3 인덱스 조각화의 유형 1. 4 인덱스 조각화로 인한 영향 1. 5 인덱스 조각화 확인 방법 1. 5 인덱스 조각화 해결 방법 2. Index Rebuild Tip 2. 1 Index Rebuild Fill. Factor 비율 2. 2 Reorganizing and Rebuilding 선택 2. 3 Clustered Index Rebuild시 DROP EXISTSING 선택 2. 4 복구 모델 선택 3. Index Rebuild 전략 3. 1 Rebuilding 전략 요소 3. 2 Rebuilding Case 3. 3 Rebuilding Offline Case 4. QA



1. 2 인덱스 조각화의 발생 원인 가. Insert and Update operations causing Page Split 나. Delete operations 다. Initial allocation of pages from mixed extents 라. Large row size 5 / 주디아줌마

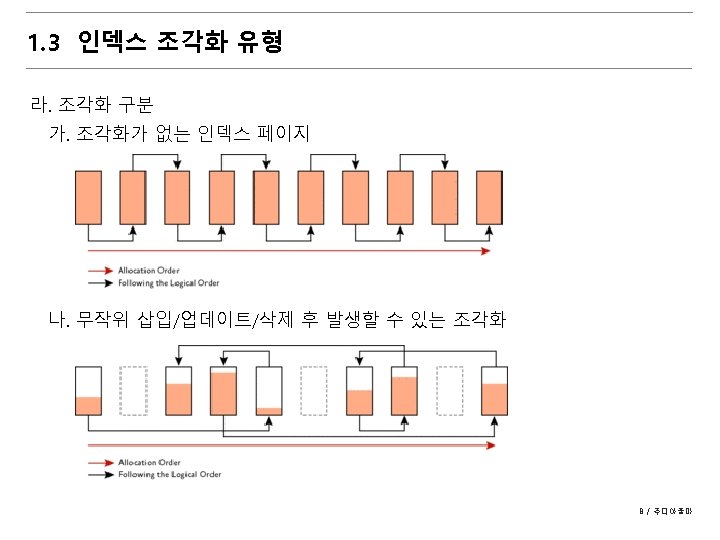
1. 3 인덱스 조각화 유형 가. Internal Fragmentation - Random deletes resulting in empty space on data pages - Page-splits due to inserts or updates - Shrinking the row such as when updating a large value to a smaller value - Using a fill factor of less than 100 - Using large row sizes 6 / 주디아줌마

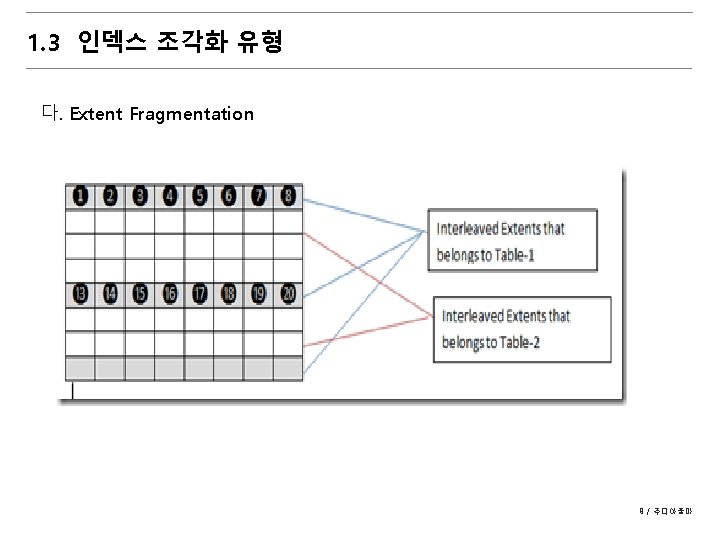
1. 3 인덱스 조각화 유형 나. Logical Fragmentation - Page-splits due to inserts or updates - Heavy deletes that can cause pages be removed from the page chain, resulting in dis-contiguous page chain 7 / 주디아줌마

1. 4 조각화로 인한 영향은? Logical fragmentation and Extent fragmentation will cause the read performance to slow down 10 / 주디아줌마

1. 5 인덱스 조각화 확인 방법 DECLARE @id int, @indid int SET @id = OBJECT_ID('dbo. Tbl. X') SELECT @indid = index_id FROM sys. indexes WHERE object_id = @id AND name = 'nc_tblx_rand. Seq' dbcc showcontig('Tbl. X', @indid) go SELECT table_schema , OBJECT_NAME(F. OBJECT_ID) obj , i. name ind , f. INDEX_TYPE_DESC AS Index. Type, f. avg_fragmentation_in_percent, f. Avg_page_space_used_in_percent, f. page_count FROM SYS. DM_DB_INDEX_PHYSICAL_STATS (DB_ID(), NULL, NULL) F JOIN SYS. INDEXES I ON(F. OBJECT_ID=I. OBJECT_ID)AND i. index_id=f. index_id JOIN INFORMATION_SCHEMA. TABLES S ON (s. table_name=OBJECT_NAME(F. OBJECT_ID)) AND f. database_id=DB_ID() AND OBJECTPROPERTY(I. OBJECT_ID, 'ISSYSTEMTABLE')=0 11 / 주디아줌마 WHERE F. OBJECT_ID = OBJECT_ID('Tbl. X')
 인덱스가 삭제된 다음")
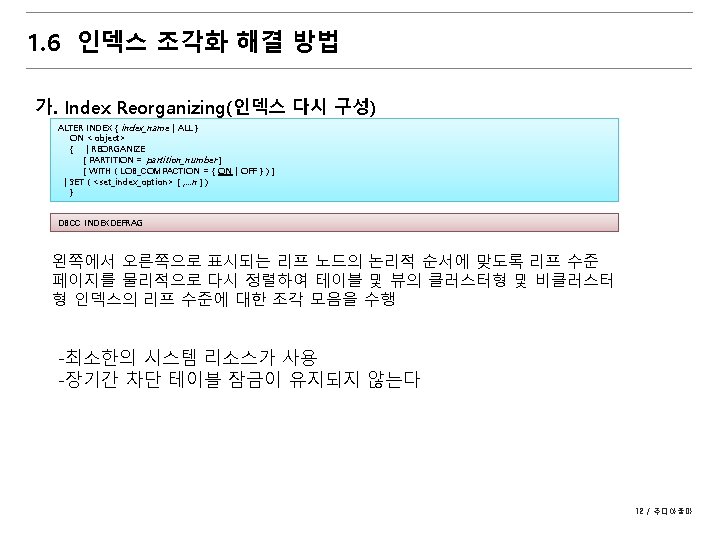
1. 6 인덱스 조각화 해결 방법 나. Index Rebuilding(인덱스 다시 작성) 인덱스가 삭제된 다음 다시 생성 ALTER INDEX { index_name | ALL } ON <object> { REBUILD [ [PARTITION = ALL] [ WITH ( <rebuild_index_option> [ , . . . n ] ) ] | [ PARTITION = partition_number [ WITH ( <single_partition_rebuild_index_option> [ , . . . n ] ) ] ] | SET ( <set_index_option> [ , . . . n ] ) } DROP INDEX 인덱스명 ON 테이블명 CREATE INDEX 인덱스명 ON 테이블명 ~ DROP_EXISTING CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ , . . . n ] ) [ INCLUDE ( column_name [ , . . . n ] ) ] [ WHERE <filter_predicate> ] [ WITH ( <relational_index_option> [ , . . . n ] ) ] [ ON { partition_scheme_name ( column_name ) | filegroup_name | default } ] [ FILESTREAM_ON { filestream_filegroup_name | partition_scheme_name | "NULL" } ] [ ; ] | DROP_EXISTING = { ON | OFF } DBCC DBREINDEX ( table_name [ , index_name [ , fillfactor ] ] ) [ WITH NO_INFOMSGS ] 13 / 주디아줌마

1. 6 인덱스 조각화 해결 방법 다. Reogranizing and rebuilding의 특징 # Characteristic Alter Index REORGANIZE Alter Index REBUILD 1 Online or Offline Online Offline (unless using the Online keyword) 2 Address Internal Fragmentation Yes (can only raise page density) Yes 3 Address Logical Fragmentation Yes 4 Transaction Atomicity Small Discrete Transactions Single Atomic Transaction 5 Rebuild Statistics Automatically No Yes 6 Parallel Execution in multi-processor machines No Yes 7 Untangle Indexes that have become interleaved within a data file No Yes 8 Transaction log space used Less More 9 Additional free space required in the data file No Yes 14 / 주디아줌마

2. Index Rebuild Tip

2. 1 Index Rebuild Fill. Factor 비율 가. Low Update Tables (100 -1 read to write ratio): 100% fill factor 나. High Update Tables (where writes exceed reads): 50%-70% fill factor 다. Everything In-Between: 80%-90% fill factor. 16 / 주디아줌마

2. 2 Reorganizing and Rebuilding 선택 가. Fragmentation >=30 AND PAGES>1000 일때 rebuild 나. Fragmentation between 15 to 29 AND PAGES>1000 일때 reorganize&updatestatistics 다. 가와 나의 조건에 들어가지 있는 다면, update the statistics 17 / 주디아줌마



3. Index Rebuild 전략


3. 2 Rebuilding Case Online Index Build Offline Index Build Create clustered index idx_t on t(c 1, c 2) WITH (ONLINE = ON) Create clustered index idx_t on t(c 1, c 2) Serial Index Build Parallel Index Build Create index idx_t on t(c 1, c 2) WITH (MAXDOP = 2) Storing in User’s database Storing in tempdb Create clustered Index idx_t on t( c 1) Create clustered Index idx_t on t(c 1) WITH (SORT_IN_TEMPDB = ON) Partitioned index build Non Partitioned build 22 / 주디아줌마

3. 3 Rebuilding Offline Case # Case Add Case 1 Serial 2 Parallel 4 Parallel Partitionning (use sort_in_tmpdb) Desc DISK : 2. 2*Index Size Memory : At least 40 Pages(3200 KB) Use Stats Plan (Historygram) Serial Build보다 더 많은 메모리 소모 #DOP만큼 sort table 생성 Non Stats Plan (No historygram) Indexed view(“No Stats Plan”) Parallel data source read Aligned partitioned Non-Aligned partitioned • Aligned (when base object and in-build index use the same partition schema) • Not- Aligned (when heap and index use different partition schemas (including the case when base object is not partitioned at all and in-build index use partitions)) 23 / 주디아줌마
 http: //judydba. tistory. com/135")
참고 1. 인덱스를 리빌드 및 통계 업데이트를 한꺼번에^^ (주디아줌마 블로그) http: //judydba. tistory. com/135 2. http: //www. alicerock. com/1051 3. http: //blogs. msdn. com/b/pamitt/archive/2010/12/23/notes-sql-server-indexfragmentation-types-and-solutions. aspx 4. http: //blogs. msdn. com/b/sqlqueryprocessing/archive/tags/indexing/ 24 / 주디아줌마

Thank you~~
- Slides: 25