MPI MPI MPI include mpi h int mainint






 { return")
; if (n > 0) { //")


![Класи перемінних • • • double Array 1[100]; int main() { int Array 2[100];](https://slidetodoc.com/presentation_image_h/83ea2605145e1babe60128f55ebfc2ce/image-23.jpg "Класи перемінних • • • double Array 1[100]; int main() { int Array 2[100];")
 { int")












- Slides: 41
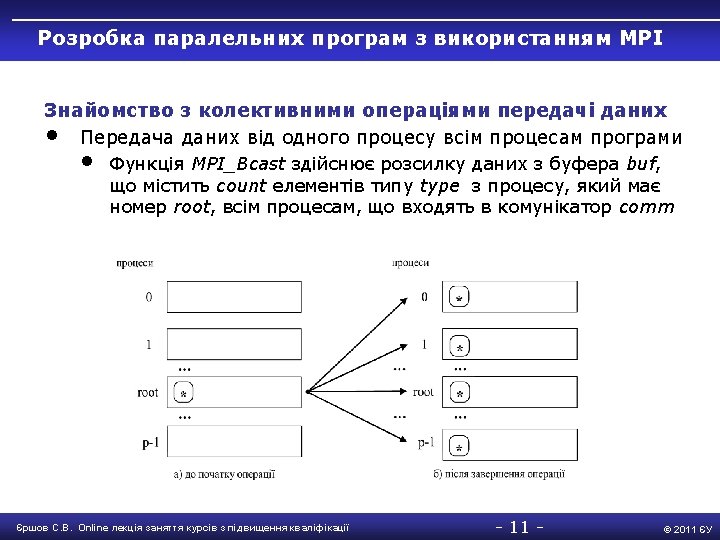
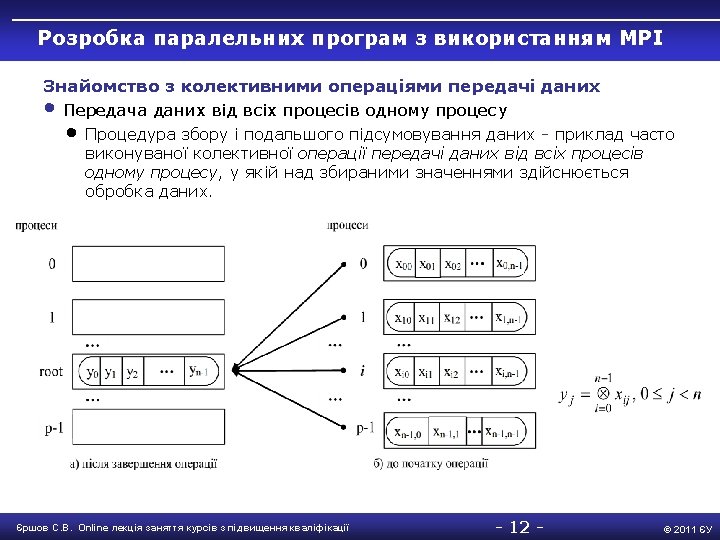
Розробка паралельних програм з використанням MPI Основи MPI • Паралельна програма з використанням MPI #include " mpi. h " int main(int argc, char* argv[]) { int Proc. Num, Proc. Rank, Recv. Rank; MPI_Status; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &Proc. Num); MPI_Comm_rank(MPI_COMM_WORLD, &Proc. Rank); if ( Proc. Rank == 0 ) { // Дії для процесу 0 printf ("n Hello from process %3 d", Proc. Rank); for ( int i=1; i < Proc. Num; i++ ) { MPI_Recv(&Recv. Rank, 1, MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &Status); printf("n Hello from process %3 d", Recv. Rank); } } else // Дії для всіх процесів, окрім процесу 0 MPI_Send(&Proc. Rank, 1, MPI_INT, 0, 0, MPI_COMM_WORLD); // Завершення роботи MPI_Finalize(); return 0; } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації -7 - © 2011 ЄУ
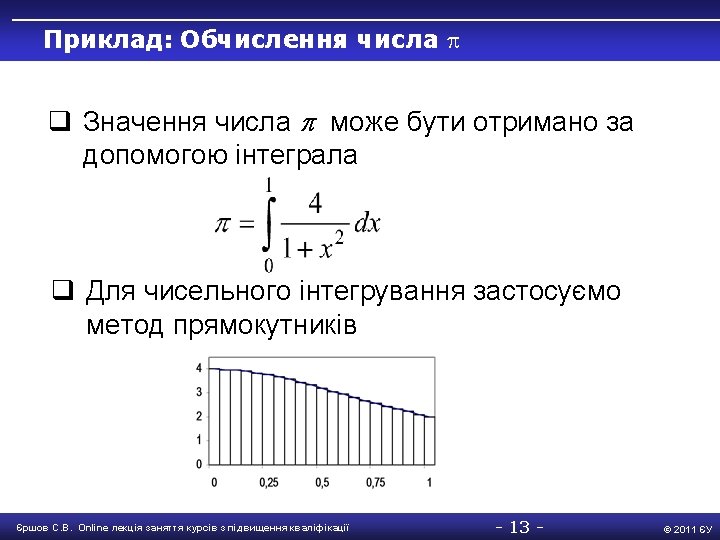
Приклад: Обчислення числа #include "mpi. h" #include <math. h> double f(double a) { return (4. 0 / (1. 0 + a*a)); } int main(int argc, char *argv) { int Proc. Rank, Proc. Num, done = 0, n = 0, i; double PI 25 DT = 3. 141592653589793238462643; double mypi, h, sum, x, t 1, t 2; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &Proc. Num); MPI_Comm_rank(MPI_COMM_WORLD, &Proc. Rank); while (!done ) { // основний цикл обчислень if ( Proc. Rank == 0) { printf("Enter the number of intervals: "); scanf("%d", &n); t 1 = MPI_Wtime(); } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 15 - © 2011 ЄУ
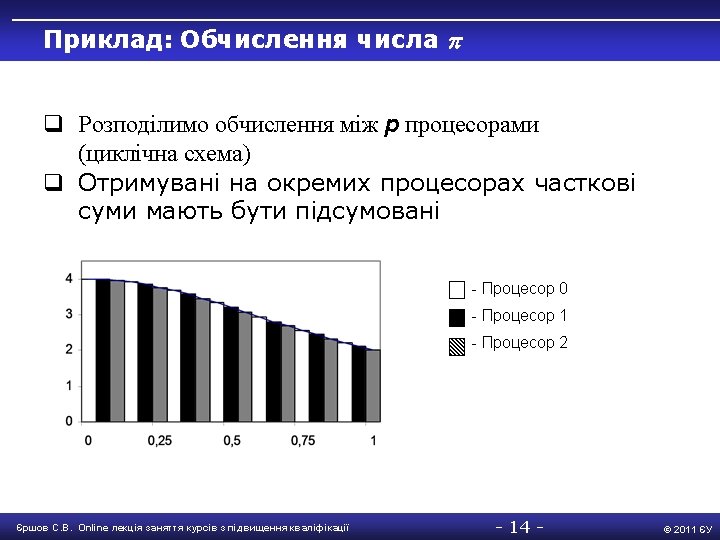
Приклад: Обчислення числа MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); if (n > 0) { // обчислення локальних сум h = 1. 0 / (double) n; sum = 0. 0; for (i = Proc. Rank + 1; i <= n; i += Proc. Num) { x = h * ((double)i 0. 5); sum += f(x); } mypi = h * sum; // складання локальних сум (редукція) MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD ); if ( Proc. Rank == 0 ) { // виведення результатів t 2 = MPI_Wtime(); printf("pi is approximately %. 16 f, Error is %. 16 fn", pi, fabs(pi PI 25 DT)); printf("wall clock time = %fn", t 2 t 1); } } else done = 1; } MPI_Finalize(); } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 16 - © 2011 ЄУ
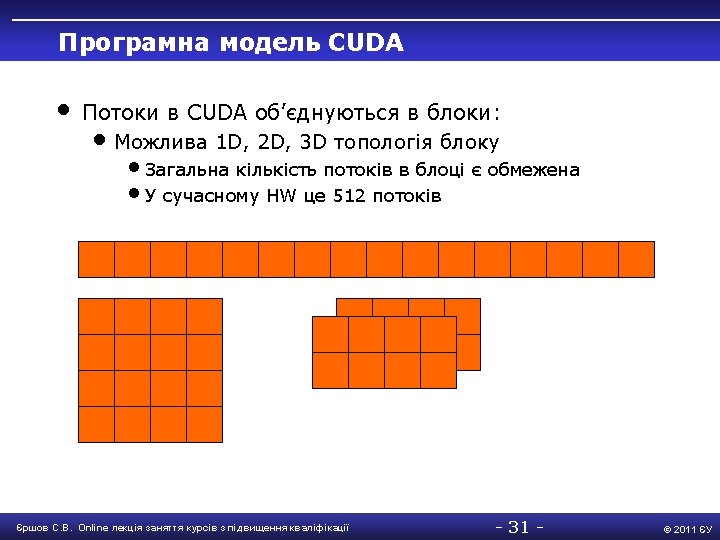
Класи перемінних • • • double Array 1[100]; int main() { int Array 2[100]; #pragma omp parallel { int iam = omp_get_thread_num(); work(Array 2, iam); printf(“%dn”, Array 2[0]); } } extern double Array 1[100]; void work(int *Array, int iam) { double Temp. Array[100]; static int count; Temp. Array, iam. . . } Array 1, Array 2, count Temp. Array, iam Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 23 - © 2011 ЄУ
Обчислення числа з використанням Open. MP #include <stdio. h> int main () { int n =100000, i; double pi, h, sum, x; h = 1. 0 / (double) n; sum = 0. 0; #pragma omp parallel for reduction(+: sum) private(x) for (i = 1; i <= n; i ++) { x = h * ((double)i - 0. 5); sum += (4. 0 / (1. 0 + x*x)); } pi = h * sum; printf("pi is approximately %. 16 f”, pi); return 0; } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 24 - © 2011 ЄУ
Використання директиви task typedef struct node; struct node { int data; node * next; }; void increment_list_items(node * head) { #pragma omp parallel { #pragma omp single { node * p = head; while (p) { #pragma omp task process(p); p = p->next; } } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 25 - © 2011 ЄУ
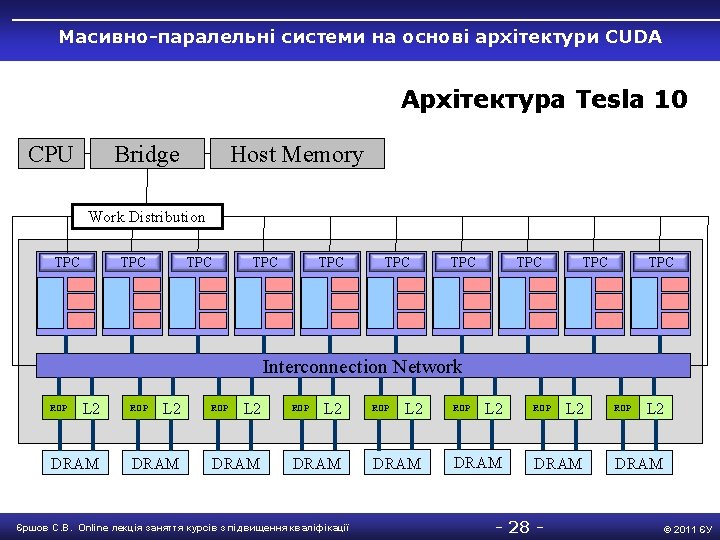
Масивно-паралельні системи на основі архітектури CUDA Мультипроцесор Tesla 10 Streaming Multiprocessor Instruction $ Instruction Fetch Texture Processing Cluster Shared Memory SM TEX SM SM Constant $ SP SP SFU Register File Double Precision Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 27 - © 2011 ЄУ
Множення матриць в CUDA #define BLOCK_SIZE 16 __global__ void mat. Mult (float* a, float* b, int n, float* c) { int bx = block. Idx. x; int by = block. Idx. y; int tx = thread. Idx. x; int ty = thread. Idx. y; float sum = 0. 0 f; int ia = n * BLOCK_SIZE * by + n * ty; int ib = BLOCK_SIZE * bx + tx; int ic = n * BLOCK_SIZE * by + BLOCK_SIZE * bx; for ( int k = 0; k < n; k++ ) sum += a [ia + k] * b [ib + k*n]; c [ic + n * ty + tx] = sum; } Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 38 - © 2011 ЄУ
Множення матриць в CUDA int float dim 3 num. Bytes = N * sizeof ( float ); * adev, * bdev, * cdev ; threads ( BLOCK_SIZE, BLOCK_SIZE ); blocks ( N / threads. x, N / threads. y); cuda. Malloc ( (void**)&adev, num. Bytes ); // allocate DRAM ( (void**)&bdev, num. Bytes ); // allocate DRAM ( (void**)&cdev, num. Bytes ); // allocate DRAM // copy from CPU to DRAM cuda. Memcpy ( adev, a, num. Bytes, cuda. Memcpy. Host. To. Device ); cuda. Memcpy ( bdev, b, num. Bytes, cuda. Memcpy. Host. To. Device ); mat. Mult<<<blocks, threads>>> ( adev, bdev, N, cdev ); cuda. Thread. Synchronize(); cuda. Memcpy ( c, cdev, num. Bytes, cuda. Memcpy. Device. To. Host ); // free GPU memory cuda. Free ( adev ); cuda. Free ( bdev ); cuda. Free ( cdev ); Єршов С. В. Online лекція заняття курсів з підвищення кваліфікації - 39 - © 2011 ЄУ