MPI Open MP MPI MPI MPI include file



















 CALL")


 Fortran 77: MPI_INIT(FLAG, IERROR) LOGICAL")
 int MPI_Comm_rank(MPI_Comm comm, int *rank)")

 Fortran 77: MPI_ABORT(COMM, ERRORCODE, IERROR)")
 Fortran 77: MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERR)")
 Fortran 77: MPI_GET_VERSION(VERSION,")




")


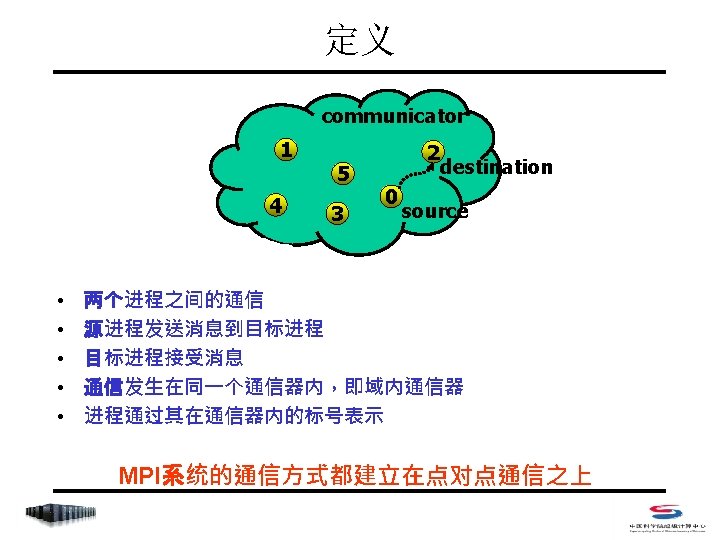



 – Fortran中是包含MPI_STATUS_SIZE元素的整型数组 typedef struct { 消息源地址 STATUS(MPI_SOURCE)")
 Fortran 77: MPI_GET_COUNT(STATUS,")


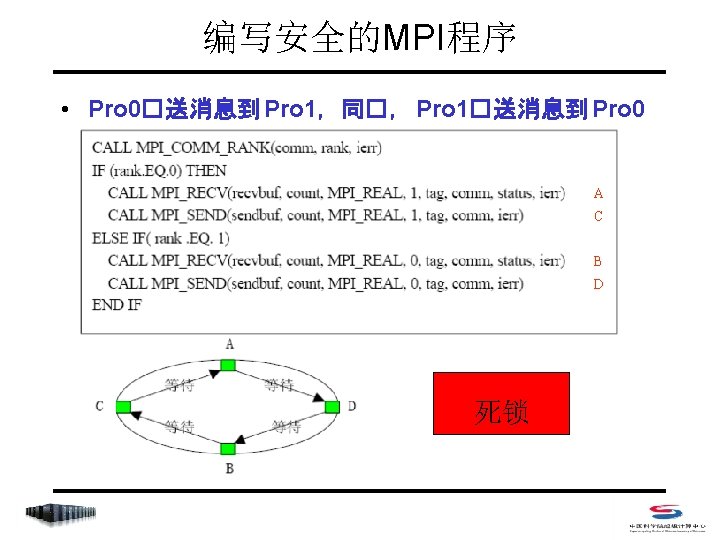



 IF(rank. EQ. 0) THEN CALL")

 BUF INTEGER SIZE, TOTALSIZE, count CALL MPI_TYPE_SIZE(MPI_REAL, SIZE,")




 THEN CALL MPI_ISEND(sendbuf, count, MPI_REAL, 1, tag, comm,")








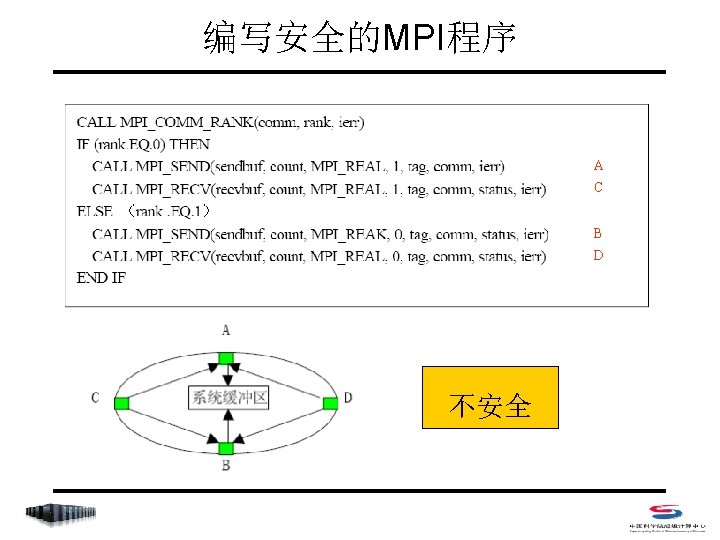
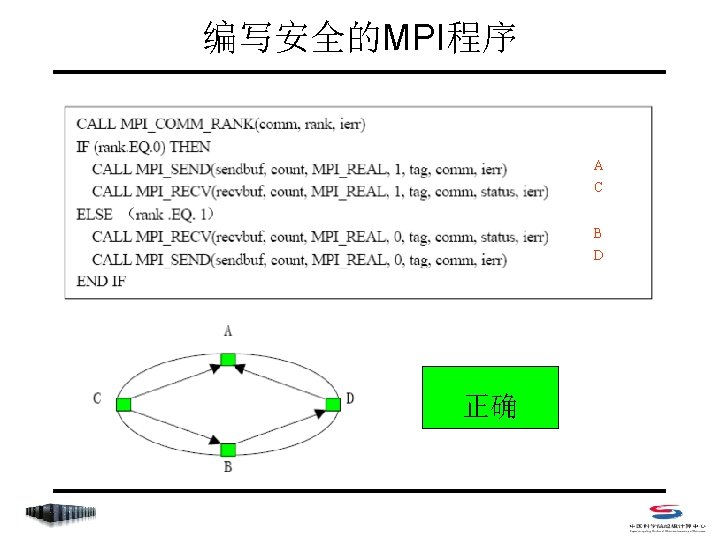
 IF (rank. EQ. 0) THEN CALL")







 IF(RANK. EQ. 0) THEN CALL WORK")

![Sample - C #include<mpi. h> int main (int argc, char *argv[]) { int rank;](https://slidetodoc.com/presentation_image_h/79e610850785135c8e803f843e49da3f/image-99.jpg "Sample - C #include<mpi. h> int main (int argc, char *argv[]) { int rank;")
 ROOT")

 A B B C A D C D")

, RBUF(10000), SIZE, ROOT, RTYPE, RANK, RECS(100), DISP(100) CALL")
")
")
")
")

 B A A B C C D D")

![Sample - C #include <mpi. h> int main (int argc, char *argv[]) { int](https://slidetodoc.com/presentation_image_h/79e610850785135c8e803f843e49da3f/image-112.jpg "Sample - C #include <mpi. h> int main (int argc, char *argv[]) { int")
 AB CD E F GH I J KL MN O P • 各进程依次为根进程分发")
 Do I=0, NPROCS-1 CALL MPI_SCATTER(SENDBUF(I), SENDCOUNT, SENDTYPE, + RECVBUF+I*RECVCOUNT*extent(RECVTYPE), RECVCOUNT, RECVTYPE, I, COMM,")

 • 每个进程如同根进程一样,执行一次MPI_Scatterv发送 Do I=0, NPROCS-1 CALL MPI_SCATTERV(SENDBUF(I), SENDCOUNTS, SDISPLS, SENDTYPE, + RECVBUF+RDISPLS(I)*extent(RECVTYPE), RECVCOUNTS(I),")
 • 各进程提供数据(sendbuf, count, datatype) • 归约结果存放在root进程的缓存区recvbuf")





")
")
")





- Slides: 131
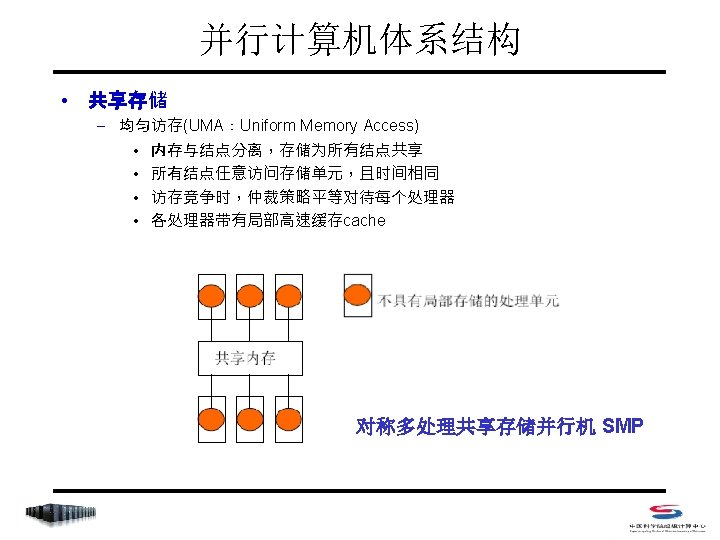
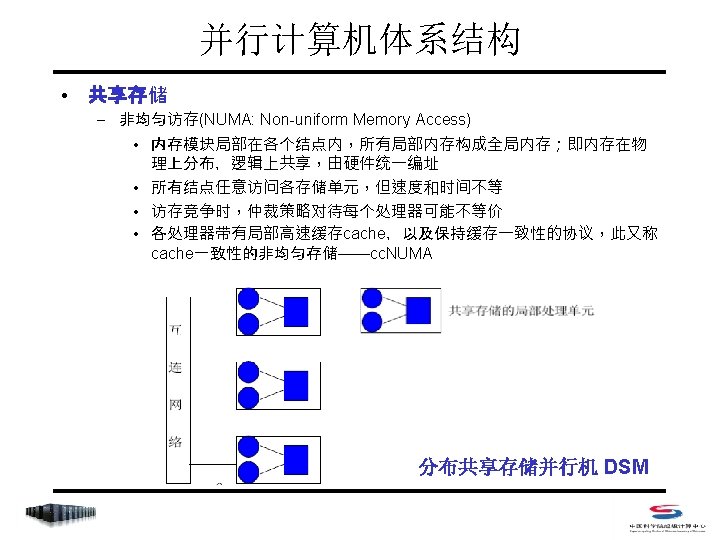
并行编程——MPI & Open. MP MPI
MPI程序基本结构 MPI include file 变量定义 MPI 环境初始化 执行程序 进程间通信 退出 MPI 环境 #include <mpi. h> void main (int argc, char *argv[]) { int np, rank, ierr; ierr = MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank) ; MPI_Comm_size(MPI_COMM_WORLD, &np); /* Do Some Works */ ierr = MPI_Finalize(); }
MPI程序基本结构 PROGRAM bones. f INCLUDE ‘mpif. h’ INTEGER ierror, rank, np CALL MPI_INIT(ierror) CALL MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierror) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, np, ierror) C … Do some work … CALL MPI_FINALIZE(ierror) END
MPI几个基本函数 • Index – MPI_Initialized – MPI_Comm_size – MPI_Comm_rank – MPI_Finalize – MPI_Abort – MPI_Get_processor_name – MPI_Get_version – MPI_Wtime
MPI几个基本函数 • 检测 MPI 系统是否已经初始化 C: int MPI_Initialized(int *flag) Fortran 77: MPI_INIT(FLAG, IERROR) LOGICAL FLAG INTEGER IERROR • 唯一可在 MPI_Init 前使用的函数 • 已经调用MPI_Init,返回flag=true,否则flag=false
MPI几个基本函数 • 得到通信器的进程数和进程在通信器中的标号 C: int MPI_Comm_size(MPI_Comm comm, int *size) int MPI_Comm_rank(MPI_Comm comm, int *rank) Fortran 77: MPI_COMM_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR MPI_COMM_RANK(COMM, RANK, IERROR) INTEGER COMM, RANK, IERROR
MPI几个基本函数 • 异常终止MPI程序 C: int MPI_Abort(MPI_Comm comm, int errorcode) Fortran 77: MPI_ABORT(COMM, ERRORCODE, IERROR) INTEGER COMM, ERRORCODE, IERROR • 在出现了致命错误而希望异常终止MPI程序时执行 • MPI系统会设法终止comm通信器中所有进程 • 输入整型参数errorcode,将被作为进程的退出码返回给系统
MPI几个基本函数 • 获取处理器的名称 C: int MPI_Get_processor_name(char *name, int *resultlen) Fortran 77: MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERR) CHARACTER *(*) NAME INTEGER RESULTLEN, IERROR • 在返回的name中存储进程所在处理器的名称 • resultlen存放返回名字所占字节 • 应提供参数name不小于MPI_MAX_PRCESSOR_NAME个字 节的存储空间
MPI几个基本函数 • 获取 MPI 版本号 C: int MPI_Get_version(int *version, int *subversion) Fortran 77: MPI_GET_VERSION(VERSION, SUBVERSION, IERR) INTEGER VERSION, SUBVERSION, IERROR • 若 mpi 版本号为 2. 0,则返回的version=2,subversion=0
Sample : Hello World - C C+MPI #include “mpi. h” #include <stdio. h> #include <math. h> void main(int argc, char *argv[ ]) { int myid, numprocs, namelen; char processor_name[MPI_MAX_PROCESSOR_NAME]; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myid); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); MPI_Get_processor_name(processor_name, &namelen); printf("Hello World! Process %d of %d on %sn", myid, numprocs, processor_name); MPI_Finalize(); }
Sample : Hello World
Sample : Hello World - Fortran+MPI program main include 'mpif. h' character * (MPI_MAX_PROCESSOR_NAME) processor_name integer myid, numprocs, namelen, rc, ierr call MPI_INIT( ierr ) call MPI_COMM_RANK( MPI_COMM_WORLD, myid, ierr ) call MPI_COMM_SIZE( MPI_COMM_WORLD, numprocs, ierr ) call MPI_GET_PROCESSOR_NAME(processor_name, namelen, ierr) write(*, *) 'Hello World! Process ', myid, ' of ', numprocs, ' on ', processor_name call MPI_FINALIZE(rc) end
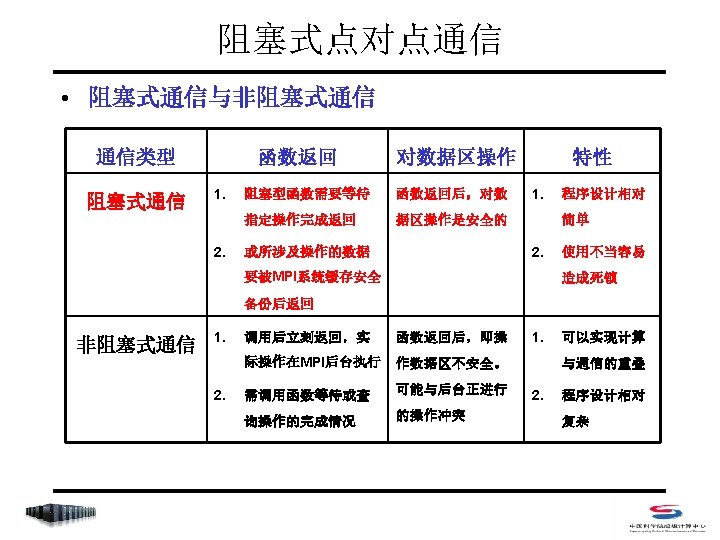
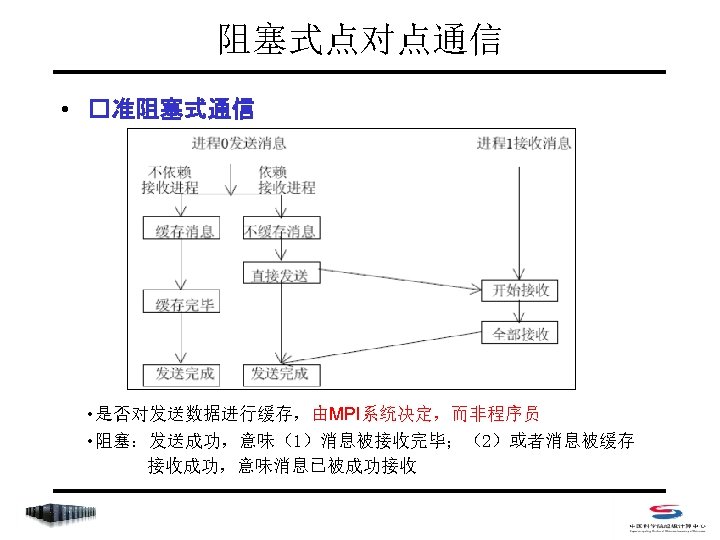
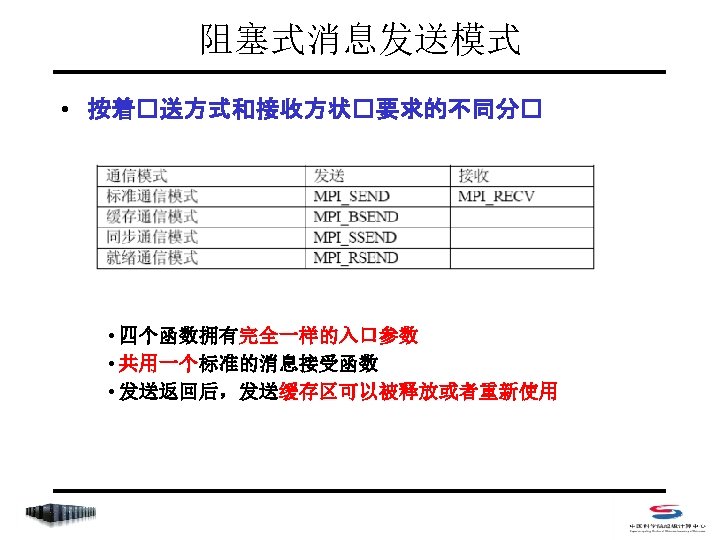
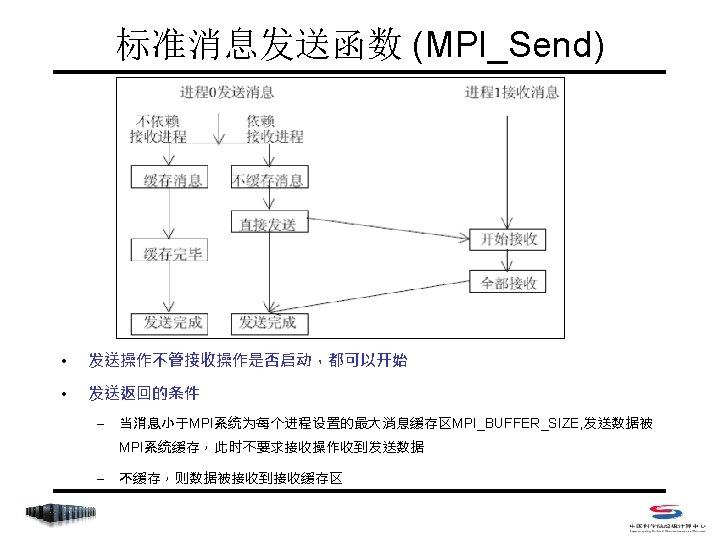
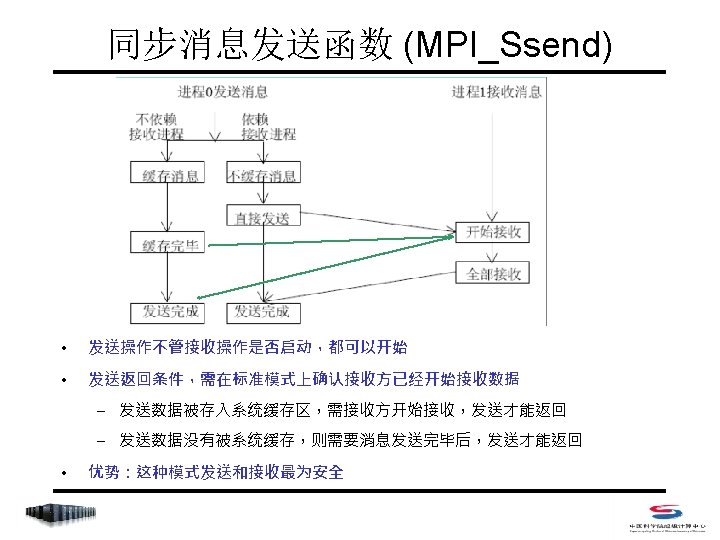
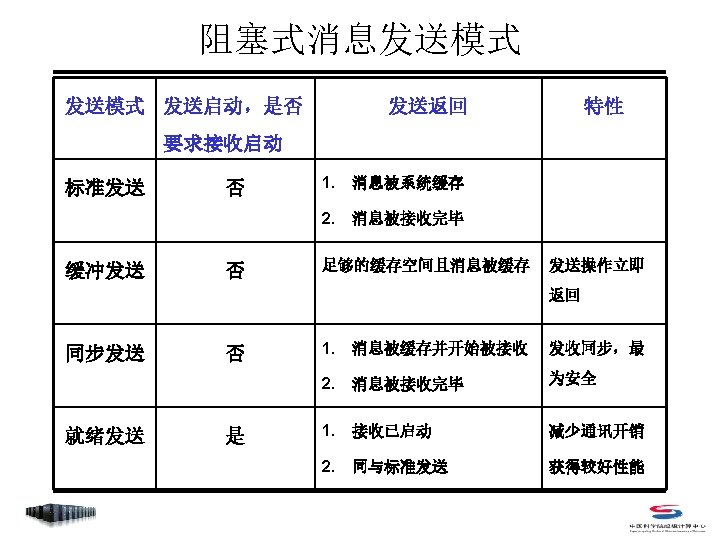
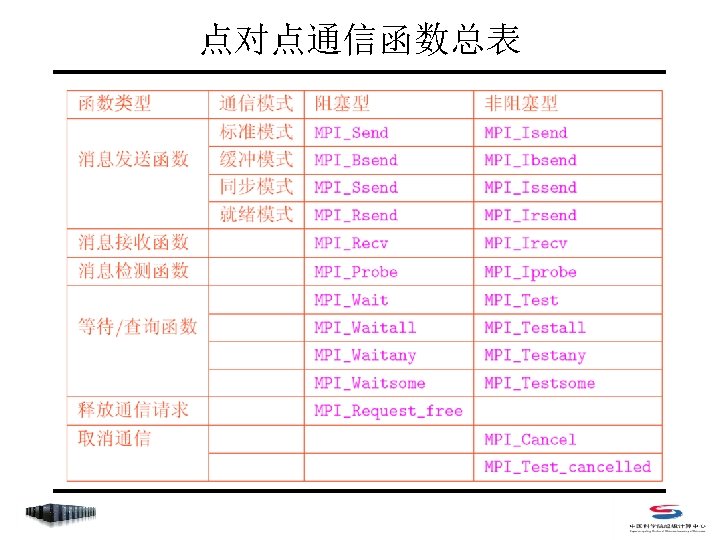
阻塞式点对点通信 • Index – MPI_Send – MPI_Recv – MPI_Get_count – MPI_Sendrecv_replace
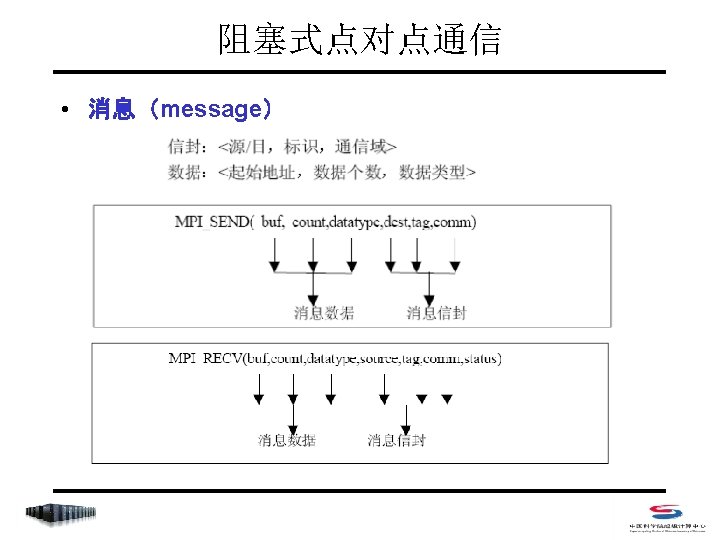
阻塞式点对点通信 • 阻塞式消息发送 C: int MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) Fortran 77: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR • count 不是字节数,而是指定数据类型的个数 • datatype可是原始数据类型,或为用户自定义类型 • dest 取值范围是 0~np-1,或MPI_PROC_NULL (np是comm中的进程总数) • tag 取值范围是 0~MPI_TAG_UB,用来区分消息
阻塞式点对点通信 • 阻塞式消息接收 C: int MPI_Recv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) Fortran 77: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR INTEGER STATUS(MPI_STATUS_SIZE) • count是接受缓存区的大小,表示接受上界,具体接受长度可用 MPI_Get_count 获得 • source 取值范围是 0~np-1,或MPI_PROC_NULL和 MPI_ANY_SOURCE • tag 取值范围是 0~MPI_TAG_UB,或MPI_ANY_TAG
阻塞式点对点通信 • status – C中是一个数据结构为MPI_status的参数,用户可以直接访问 的三个域(共 5个域) – Fortran中是包含MPI_STATUS_SIZE元素的整型数组 typedef struct { 消息源地址 STATUS(MPI_SOURCE) int MPI_TAG; 消息标号 STATUS(MPI_TAG) int MPI_ERROR; . . . 接收操作的错误码 STATUS(MPI_ERROR) . . . int MPI_SOURCE; } MPI_Status; • C中使用前需要用户为其申请存储空间 (MPI_Status status; ) • C中引用时为 status. MPI_SOURCE …
阻塞式点对点通信 • 查询接收到的消息长度 C: int MPI_Get_count(MPI_Status status, MPI_Datatype datatype, int *count) Fortran 77: MPI_GET_COUNT(STATUS, DATATYPE, COUNT, IERR) INTEGER DATATYPE, COUNT, IERR, STATUS(MPI_STATUS_SIZE) • 该函数在count中返回数据类型的个数,即消息的长度 • count属于MPI_Status结构的一个域,但不能被用户直接访问
其他阻塞式点对点通信函数 • 捆绑发送和接收 Fortran 77: MPI_SENDRECV(SENDBUFF, SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVBUFF, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS, IERR) <type> SENDBUFF(*), RECVBUFF(*) INTEGER SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, IERR INTEGER STATUS(MPI_STATUS_SIZE) 语义上等同于一个发送和一个接收操作结合,但此函数可以有效避免在单独 发送和接收操作过程中,由于调用次序不当而造成的死锁。MPI系统会优化通 信次序,从而最大限度避免错误发生。
其他阻塞式点对点通信函数 • 捆绑发送和接收,收发使用同一缓存区 C: int MPI_Sendrecv_replace(void *buff, int count, MPI_Datatype datatype, int dest, int sendtag, int source, int recvtag, MPI_Comm comm, MPI_Status *status) Fortran 77: MPI_SENDRECV_REPLACE(BUFF, COUNT, DATATYPE, DEST, SENDTAG, SOURCE, RECVTAG, COMM, STATUS, IERR) <type> BUFF(*) INTEGER COUNT, DATATYPE, DEST, SENDTAG, SOURCE, RECVTAG, COMM, IERR INTEGER STATUS(MPI_STATUS_SIZE) • 等价于当前进程先执行一个发送函数再执行一个接收函数;MPI系统保证其 消息发出后再接收信息 • MPI_Sendrecv送收使用不同的缓存区;该函数使用同一缓存区
Sample - Fortran • MPI_SENDRECV代替MPI_SEND和MPI_RECV CALL MPI_COMM_RANK(comm, rank, ierr) IF(rank. EQ. 0) THEN CALL MPI_SENDRECV(sendbuf, count, MPI_REAL, 1, tag, + recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) IF(rank. EQ. 1) THEN CALL MPI_SENDRECV(sendbuf, count, MPI_REAL, 0, tag, + recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr)
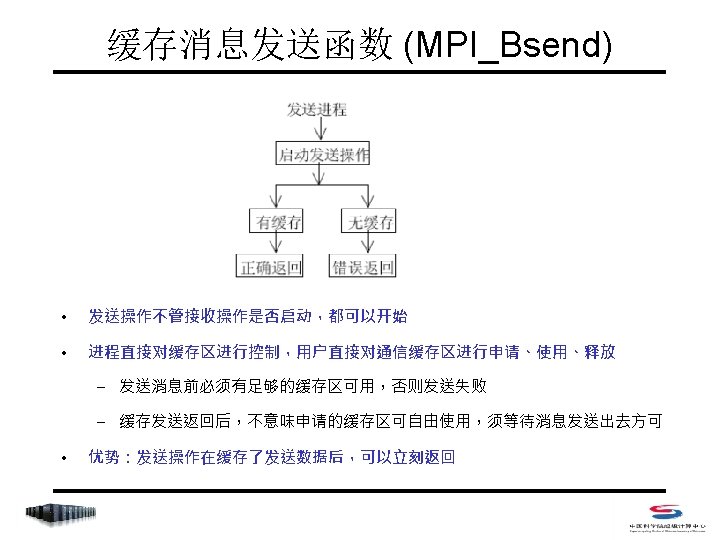
Sample - Fortran REAL * (*) BUF INTEGER SIZE, TOTALSIZE, count CALL MPI_TYPE_SIZE(MPI_REAL, SIZE, ierr) TOTALSIZE=count*SIZE + 2*MPI_BSEND_OVERHEAD ! 必须如此 (各进程都有自己的缓存) CALL MPI_BUFFER_ATTACH(BUF, TOTALSIZE, ierr) IF(rank. EQ. 0) THEN CALL MPI_BSEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) IF(rank. EQ. 1) THEN CALL MPI_BSEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr)
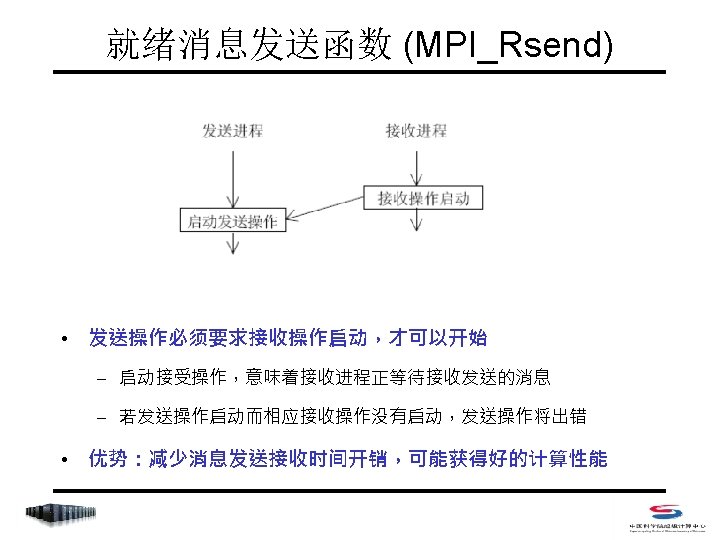
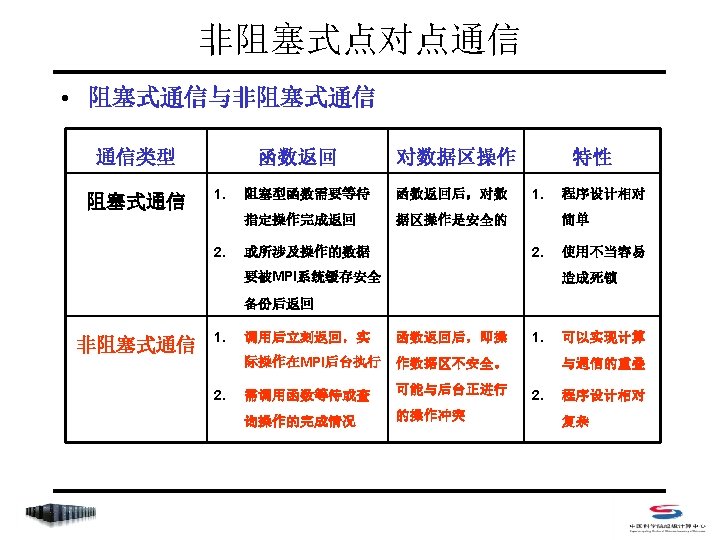
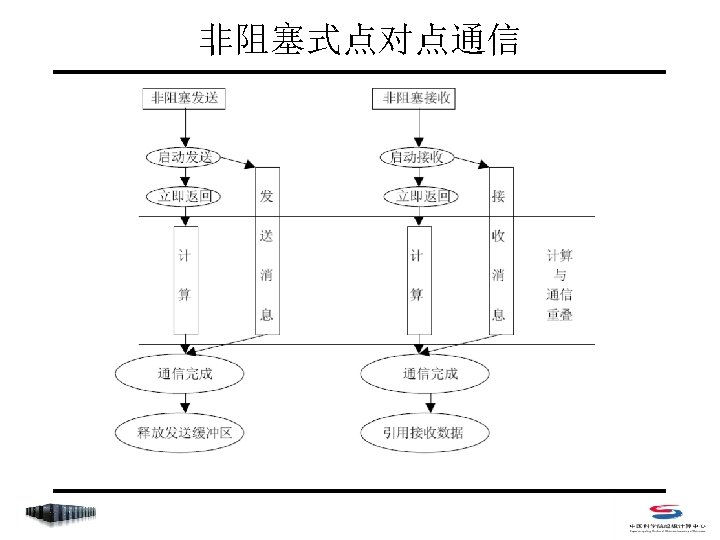
非阻塞式点对点通信 • Index – MPI_Isend/MPI_Irecv – MPI_Wait/MPI_Waitany/MPI_Waitall/MPI_Waitsome – MPI_Test/MPI_Testany/MPI_Testall/MPI_Testsome – MPI_Probe/MPI_Iprobe – MPI_Request_free – MPI_Cancel – MPI_Test_cancelled
Sample - Fortran IF(rank. EQ. 0) THEN CALL MPI_ISEND(sendbuf, count, MPI_REAL, 1, tag, comm, request, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) CALL MPI_WAIT(request, status, ierr) IF(rank. EQ. 1) THEN CALL MPI_ISEND(sendbuf, count, MPI_REAL, 0, tag, comm, request, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) CALL MPI_WAIT(request, status, ierr)
Sample - Fortran …… CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank. EQ. 0) THEN CALL MPI_SEND(i, 1, MPI_INTEGER, 2, 0, comm, ierr) ELSE IF (rank. EQ. 1) THEN CALL MPI_SEND(x, 1, MPI_REAL, 2, 0, comm, ierr) ELSE IF (rank. EQ. 2 ) THEN DO i=1, 2 CALL MPI_PROBE(MPI_ANY_SOURCE, 0, comm, status, ierr) IF (status(MPI_SOURCE) = 0) THEN CALL MPI_RECV(i, 1, MPI_INTEGER, 0, 0, status, ierr) ELSE CALL MPI_RECV(x, 1, MPI_REAL, 1, 0, status, ierr) END IF END DO END IF……
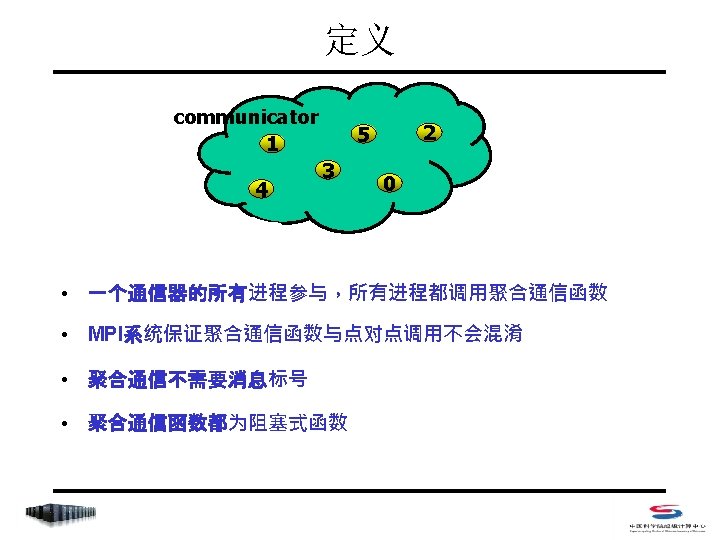
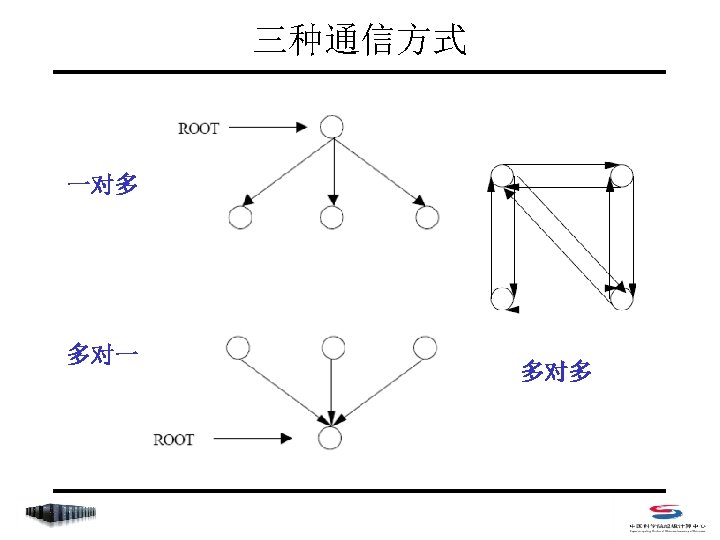
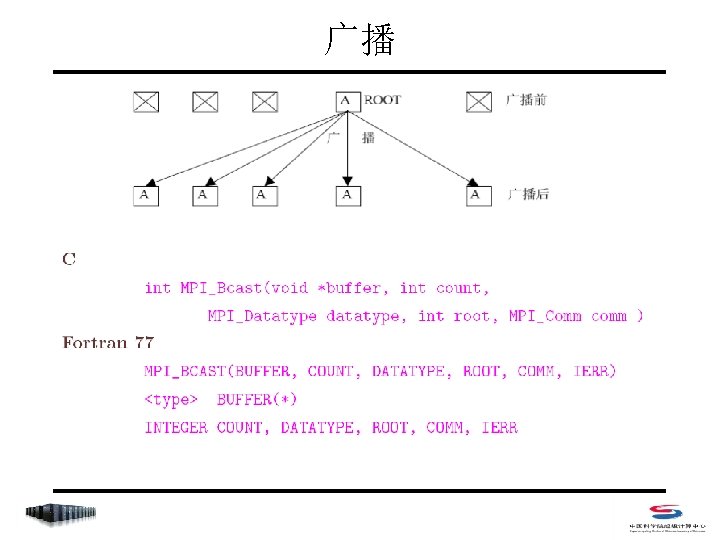
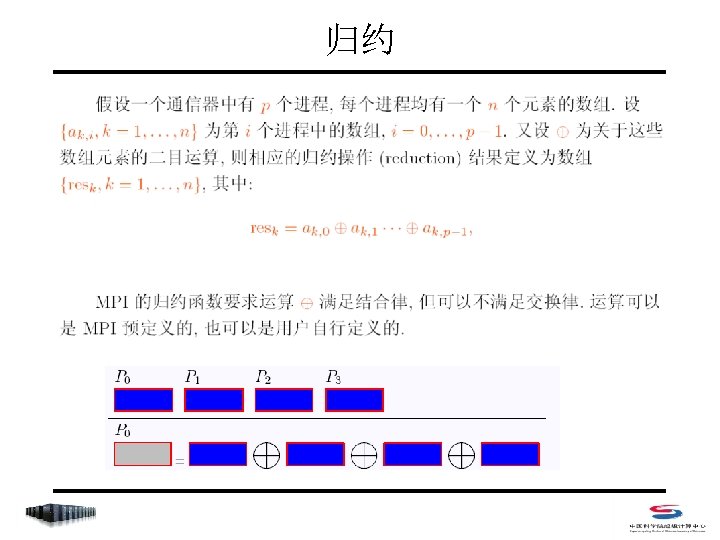
聚合函数列表 • MPI_Barrier • MPI_Bcast • MPI_Gather/MPI_Gatherv • MPI_Allgather/MPI_Allgatherv • MPI_Scatter/MPI_Scatterv • MPI_Alltoall/MPI_Alltoallv • MPI_Reduce/MPI_Allreduce/MPI_Reduce_scatter • MPI_Scan
Sample - Fortran …… CALL MPI_COMM_RANK(COMM, RANK, IERR) IF(RANK. EQ. 0) THEN CALL WORK 0(……) ELSE CALL WORK 1(……) …… CALL MPI_BARRIER(COMM, IERR) CALL MPI_COMM_RANK(COMM, RANK, IERR) CALL WORK 2(……) IF(RANK. EQ. 0) THEN CALL WORK 0(……) …… CALL MPI_BARRIER(COMM, IERR) √ ELSE CALL WORK 1(……) CALL WORK 2(……) ……
Sample - C #include<mpi. h> int main (int argc, char *argv[]) { int rank; double param; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if(rank==5) param=23. 0; MPI_Bcast(¶m, 1, MPI_DOUBLE, 5, MPI_COMM_WORLD); printf("P: %d after broadcast parameter is %fn", rank, param); MPI_Finalize(); } P: 0 P: 6 P: 5 P: 2 P: 3 P: 7 P: 1 P: 4 after after Program Output broadcast parameter is broadcast parameter is 23. 000000 23. 000000
收集 (MPI_Gather) ROOT
收集(MPI_Gatherv) A B B C A D C D
Sample – Fortran …… INTEGER A(100), RBUF(10000), SIZE, ROOT, RTYPE, RANK, RECS(100), DISP(100) CALL MPI_COMM_SIZE(COMM, SIZE, IERR) CALL MPI_COMM_RANK(COMM, RANK, IERR) IF(100*SIZE. GT. 10000) THEN 进程 i 向进程 0 发送 100 -i 个整型数, PRINT*, “NOT ENOUGH RECEIVING BUF” CALL MPI_FINALIZE(IERR) 每隔 100个整型数依次存储消息 ELSE ROOT=0 IF(RANK. EQ. 0) THEN DO I=0, SIZE-1 0 1 3 4 RECS(I)=100 -I DISP(I)=I*100 ENDDO ENDIF CALL MPI_GATHERV(A, 100 -RANK, MPI_INTEGER, RBUF, RECS, DISP, MPI_INTERGER, ROOT, COMM, IERR) ENDIF ……
收集(MPI_Allgather)
收集(MPI_Allgather)
收集(MPI_Allgatherv)
散发(MPI_Scatter)
散发(MPI_Scatterv) B A A B C C D D
Sample - C #include <mpi. h> int main (int argc, char *argv[]) { int rank, size, i, j; double param[400], mine; int sndcnt, revcnt; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); revcnt=1; if(rank==3) 根进程向所有进程次序分发 1个数组元素 { for(i=0; i<size; i++) param[i]=23. 0+i; sndcnt=1; } MPI_Scatter(param, sndcnt, MPI_DOUBLE, &mine, revcnt, MPI_DOUBLE, 3, MPI_COMM_WORLD); printf("P: %d mine is %fn", rank, mine); MPI_Finalize(); } Program Output P: 0 mine is 23. 000000 P: 1 mine is 24. 000000 P: 2 mine is 25. 000000 P: 3 mine is 26. 000000
全散发收集(MPI_Alltoall) AB CD E F GH I J KL MN O P • 各进程依次为根进程分发 MPI_Scatter; • 各进程依次为根进程收集 MPI_Gather AB CD E F GH I J KL MN O P AE I M BFJ N C GKO D HL P
全散发收集(MPI_Alltoall) Do I=0, NPROCS-1 CALL MPI_SCATTER(SENDBUF(I), SENDCOUNT, SENDTYPE, + RECVBUF+I*RECVCOUNT*extent(RECVTYPE), RECVCOUNT, RECVTYPE, I, COMM, IERR) ENDDO
全散发收集(MPI_Alltoallv) • 每个进程如同根进程一样,执行一次MPI_Scatterv发送 Do I=0, NPROCS-1 CALL MPI_SCATTERV(SENDBUF(I), SENDCOUNTS, SDISPLS, SENDTYPE, + RECVBUF+RDISPLS(I)*extent(RECVTYPE), RECVCOUNTS(I), RECVTYPE, I, …) ENDDO • 每个进程如同根进程一样,执行一次MPI_Gatherv接收 Do I=0, NPROCS-1 CALL MPI_GATHERV(SENDBUF+SDISPLS(I)*extent(RECVTYPE), SENDCOUNTS(I), + ENDDO SENDTYPE, RECVBUF(I), RECVCOUNTS, RDISPLS, RECVTYPE, I, …)
归约(MPI_Reduce) • 各进程提供数据(sendbuf, count, datatype) • 归约结果存放在root进程的缓存区recvbuf
Sample - C #include <mpi. h> /* Run with 16 processes */ int main (int argc, char *argv[]) { 数对的归约操作 int rank, root=7; struct { double value; int rank; } in, out; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); in. value=rank+1; (1. 000000, 0) (2. 000000, 1)…(16. 000000, 15) in. rank=rank; MPI_Reduce(&in, &out, 1, MPI_DOUBLE_INT, MPI_MAXLOC, root, MPI_COMM_WORLD); if(rank==root) printf("P : %d max=%lf at rank %dn", rank, out. value, out. rank); MPI_Reduce(&in, &out, 1, MPI_DOUBLE_INT, MPI_MINLOC, root, MPI_COMM_WORLD); if(rank==root) printf("P : %d min=%lf at rank %dn", rank, out. value, out. rank); MPI_Finalize(); } Program Output P: 7 max = 16. 000000 at rank 15 P: 7 min = 1. 000000 at rank 0
Sample - Fortran PROGRAM Max. Min C Run with 8 processes INCLUDE 'mpif. h' INTEGER err, rank, size integer in(2), out(2) CALL MPI_INIT(err) CALL MPI_COMM_RANK(MPI_WORLD_COMM, rank, err) CALL MPI_COMM_SIZE(MPI_WORLD_COMM, size, err) in(1)=rank+1 in(2)=rank call MPI_REDUCE(in, out, 1, MPI_2 INTEGER, MPI_MAXLOC, 7, MPI_COMM_WORLD, err) if(rank. eq. 7) print *, "P: ", rank, " max=", out(1), " at rank ", out(2) call MPI_REDUCE(in, out, 1, MPI_2 INTEGER, MPI_MINLOC, 2, MPI_COMM_WORLD, err) if(rank. eq. 2) print *, "P: ", rank, " min=", out(1), " at rank ", out(2) CALL MPI_FINALIZE(err) END Program Output P: 2 min=1 at rank 0 P: 7 max=8 at rank 7
全归约(MPI_Allreduce)
归约散发(MPI_Reduce_scatter)
归约散发(MPI_Reduce_scatter)
Sample - Fortran C PROGRAM User. OP Run with 8 processes INCLUDE 'mpif. h' INTEGER err, rank, size integer source, reslt EXTERNAL digit LOGICAL commute INTEGER myop CALL MPI_INIT(err) CALL MPI_COMM_RANK(MPI_WORLD_COMM, rank, err) CALL MPI_COMM_SIZE(MPI_WORLD_COMM, size, err) commute= true 满足交换律 call MPI_OP_CREATE(digit, commute, myop, err) source=(rank+1)**2 source={ 1, 4, 9, 16, 25, 36, 49, 64} call MPI_BARRIER(MPI_COM_WORLD, err) call MPI_SCAN(source, reslt, 1, MPI_INTEGER, myop, MPI_COMM_WORLD, err) print *, "P: ", rank, " my result is ", reslt CALL MPI_OP_FREE(myop, err) CALL MPI_FINALIZE(err) Program Output END P: 6 my result is integer function digit(in, inout, len, type) P: 5 my result is integer len, type P: 7 my result is integer in(len), inout(len) P: 1 my result is do i=1, len P: 3 my result is inout(i)=mod((in(i)+inout(i)), 10) P: 2 my result is end do P: 4 my result is digit=5 P: 0 my result is end 0 1 4 5 0 4 5 1