DASI Advanced Analysis Methods Comparing SPSS Modeler and









 Click Run: the Interactive Workbench")











 #runs dialog box -download 'book'")

: #returns")

![# After looking at the data, remove more stopwords. mystopwords = ']came', 'f', 'p',](https://slidetodoc.com/presentation_image_h/19c35b3ab7eaea2e1d42e632880a6e37/image-26.jpg "# After looking at the data, remove more stopwords. mystopwords = ']came', 'f', 'p',")

 def Merge.")
: # summarize counts for the words-output")





- Slides: 35
DASI - Advanced Analysis Methods: Comparing SPSS Modeler and Python for Teaching Text Mining November 18, 2017 Kellie Keeling DSI Washington, DC
Natural Language Processing • • Stop Words – common words that have little value. After getting a term frequency, these can be hand-filtered for semantic content relative to domain Bigrams (also tri-grams, etc) – sequence of 2 items from text Collocation – sequence of words that occur together unusually often – can be displayed with network diagram Stem – base of a word. For example 'time" for timing, timer, times Department of Business Information & Analytics
SPSS Modeler – with Text Analytics In SPSS Modeler, you build a stream using different nodes. They are grouped by type. In order to perform Text Analytics, you will need that set of tools separately installed. Department of Business Information & Analytics
SPSS Modeler Stream Text Mining Node Department of Business Information & Analytics
Department of Business Information & Analytics
Choose worksheet by Name – pick All. Department of Business Information & Analytics
Comments Variable set to Categorical and have READ column set to PASS Department of Business Information & Analytics
Department of Business Information & Analytics
Choose Text field: Comment Department of Business Information & Analytics
Under Copy Resources From: Resources template (Load if needed) Click Run: the Interactive Workbench will open Department of Business Information & Analytics
Concepts/Terms that have been found in the text Categories that have been scored/found in the text Department of Business Information & Analytics Click display to view the concept/term in context
After clicking “Build”, we can see that the first pass of combining concepts into Categories Example Rule Assigned to Category Assigned to Rule Not Assigned Department of Business Information & Analytics
After finalizing the Categories and cleaning up the concepts, you can view the results. Department of Business Information & Analytics
Department of Business Information & Analytics
You can create a model node from the categories, and select the terms to save to your data
You can also have the Text Mining Node focus on coword clusters
Python - NLTK • Anaconda Navigator • Install Anaconda Data Science Platform with Python 2. 7 • https: //www. anaconda. com/download • Windows (Python 2. 7 version: pick 32 or 64) • Mac (Python 2. 7 version: pick graphical installer) Department of Business Information & Analytics
Software Lingo to know! • Anaconda is a free, easy to install package manager (uses Conda), environment manager, and Python distribution. It is platform-agnostic. • • • Conda is a cross-platform package manager that uses dependency management and helps to keep packages updated. Anaconda Navigator is its desktop GUI (graphical user interface) that will allow us to get to the spyder IDE (integrated development environment). Spyder is a powerful python IDE that has advanced editing, debugging, and a numerical computing environment which uses i. Python to display the results. Department of Business Information & Analytics
Anaconda Navigator Interface At first it will say “Install” Afterwards, hit Launch to start spyder
Spyder IDE Interface Variable Explorer Write your code here in scripts with. py extension. See the output in an i. Python console
#set up environment to work like Python 3. x from __future__ import absolute_import, division, print_function df. Ratings is a import pandas as pd Pandas import os Data. Frame my. Path = '/…/DSI 17/teaching text analytics' os. chdir(my. Path) df. Ratings = pd. read_excel('Doctor. Ratings. xlsx', sheetname='All') df. Ratings. head() Out[61]: Name Date Location Staff Punctual 0 Rand, Jerry N. 2011 -10 -30 00: 00 San. Diego 3. 0 1 Houghton, Robert A. 2009 -09 -19 00: 00 San. Diego 3. 0 4. 0 2 Sacks, Anthony H. 2005 -11 -30 00: 00 San. Diego Na. N 3. 0 3 Zeiner, Rebecca L. 2013 -01 -17 00: 00 San. Diego 1. 0 4 Qaqundah, Joyce 2010 -03 -28 00: 00 San. Diego 5. 0 Helpful Knowledge Comment 0 1. 0 $375 out of pocket. While waiting for 2 hours. . . 1 4. 0 5. 0 A great doctor 2 1. 0 A poor listener and not at all helpful. He exu. . . 3 1. 0 A truly awful "gatekeeper" physician. I fired. . . 4 5. 0 A wonderful doctor! She takes time to listen a. . .
import nltk #Only run the following once #nltk. download() #runs dialog box -download 'book' from nltk. book import *
#So to grab just the comments from our data, #use this code to create a Data Frame #with comments for each location df. Ratings. Den = df. Ratings. ix[df. Ratings. Location =='Denver'] ratcomments. Dentokens = nltk. word_tokenize(str(df. Ratings. Den. Comment). lower()) my. Den. Text = nltk. Text(ratcomments. Dentokens). ix is indexer statement used for filtering word_tokenize creates "tokens" or words from text. Text creates a nltk Text object for further processing df. Ratings. Alex = df. Ratings. ix[df. Ratings. Location=='Alexandria'] ratcomments. Alextokens = nltk. word_tokenize(str(df. Ratings. Alex). lower()) my. Alex. Text = nltk. Text(ratcomments. Alextokens) df. Ratings. SD = df. Ratings. ix[df. Ratings. Location =='San Diego'] ratcomments. SDtokens = nltk. word_tokenize(str(df. Ratings. SD). lower()) my. SDText = nltk. Text(ratcomments. SDtokens)
#Create functions of code that will reuse def Remove. Stop. Words(stopwords, my. Text): #returns so call with _____ = Remove. Stop. Words() New. Text = [w for w in my. Text if w not in stopwords] # make sure it is in the. Text format New. Text = nltk. Text(New. Text) return New. Text def Get. Word. Summary(my. Text): # How many words you have at the moment? print("Word Count: ") print(len(my. Text) ) # How many unique words do you have? print("Unique Word Count: ") print(len(set(my. Text))) # Lets see what they are print("List of Unique Words: ") print(sorted(set(my. Text)))
my. Text = my. Den. Text #Do for other 2 and change outfile names later #my. Text = my. Alex. Text #my. Text = my. SDText stopwords = nltk. corpus. stopwords('english') # could be a list of words (i. e. , stopwords = ['for', 'in'] NSmy. Text = Remove. Stop. Words(stopwords, my. Text) Get. Word. Summary(NSmy. Text) Word Count: 476 Unique Word Count: 280 List of Unique Words: '" , "'" , '!']s", "'ve", '(', ', ', '--', '. . . ', '10', '1000', '1001', '1002', '10: 30', '2008', '3. 0. will', '468', '535', '536', '537', '538', '539', '540', '541', '542', '543', '544', '545', '546', '547', '548', '549', '550', '551', '552', '553', '554', '555', '556', '557', '558', '559', '560', '561', '562', '563', '564', '973', '974', '975', '976', '977', '978', '979', '980', '981', '982', '983', '984', '985', '986', '987', '988', '989', '990', '991', '992', '993', '994', '995', '996', '997', '998', '999', ': ', '? ', '``', 'absolutely', 'accurately', 'advanced', 'agreed', 'ailments', 'always', 'alzhe', 'anna', 'another', 'anyone', 'appt', 'area', 'asked', 'assistant', 'awesome', 'bedside', 'best', 'blackmailed', 'bloodwork', 'borja',
# After looking at the data, remove more stopwords. mystopwords = ']came', 'f', 'p', 'ro', 'sh', 'th[' New. NSmy. Text = Remove. Stop. Words(mystopwords, NSmy. Text) Get. Word. Summary(New. NSmy. Text) Word Count: 469 Unique Word Count: 273 List of Unique Words: '" , "'" , '!']s", "'ve", '(', ', ', '--', '. . . ', '10', '1000', '1001', '1002', '10: 30', '2008', '3. 0. will', '468', '535', '536', '537', '538', '539', '540', '541', '542', '543', '544', '545', '546', '547', '548', '549', '550', '551', '552', '553', '554', '555', '556', '557', '558', '559', '560', '561', '562', '563', '564', '973', '974', '975', '976', '977', '978', '979', '980', '981', '982', '983', '984', '985', '986', '987', '988', '989', '990', '991', '992', '993', '994', '995', '996', '997', '998', '999', ': ', '? ', '``', 'absolutely', 'accurately', 'advanced', 'agreed', 'ailments', 'always', 'alzhe', 'anna', 'another', 'anyone', 'appt', 'area', 'asked', 'assistant', 'awesome', 'bedside', 'best', 'blackmailed', 'bloodwork', 'borja', 'butt', 'caring', 'case', 'child', 'chr', 'comment', 'complaint', 'concern', 'conditi', 'considering, '
# Also clean up - like see if any - or ' in text def Remove. Junk(removelist, my. Text): newlist = [] for word in my. Text: newword = '' for character in range(len(word)): flag = 'false for check in removelist: if word[character]. encode('ascii', 'replace')==check: flag = 'true' if flag == 'false': newword = str(newword)+ str(word[character]. encode('ascii', 'replace')) newlist. append(newword) newlist = nltk. Text(newlist) return newlist removelist = ["-", "? ", "(", ")", "\", "!", ", "] Strip. New. NSmy. Text = Remove. Junk(removelist, New. NSmy. Text) Get. Word. Summary(Strip. New. NSmy. Text)
# merging of words (1: look up, 2: 'stem' will change to) def Merge. Tokens(wordstems, my. Text): newlist = [] for word in my. Text: newword = '' for check in wordstems: if word == check[0]: newword = check[1] if newword == '': newlist. append(word) else: newlist. append(newword) return newlist wordstems = ('biggest', 'big'), ('appt', 'appointment'), ('appts', 'appointment'), ('answered', 'answer'), ('balanced', 'balance'), ('availability', 'available') Merge. Strip. New. NSmy. Text = [] Merge. Strip. New. NSmy. Text = Merge. Tokens(wordstems, Strip. New. NSmy. Text) Get. Word. Summary(Merge. Strip. New. NSmy. Text)
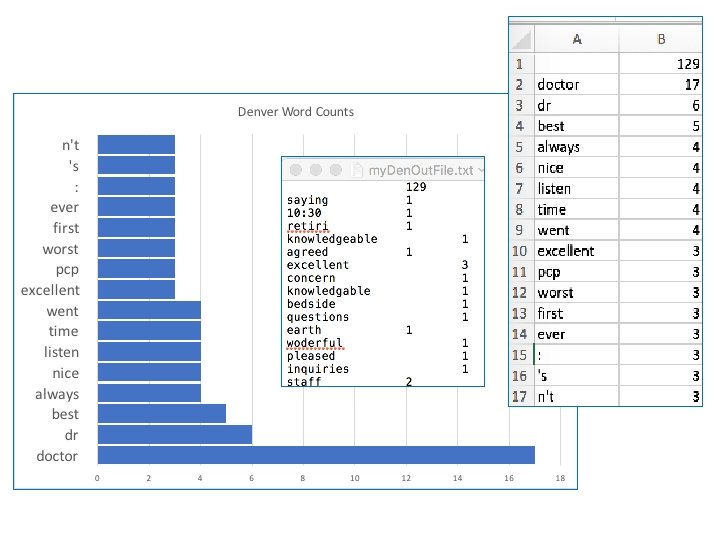
def Get. Freq. Words(my. Out. File, my. Text): # summarize counts for the words-output to text file # Let’s make a table of all the words and the # frequency of each word, then write it out to a file. # First, let's view the top 200 words fdist 1 = nltk. Freq. Dist(my. Text) vocab = fdist 1. keys() print(vocab[: 200]) #used print so would wrap # Second, open a file to write out our table: Out. File = open(my. Out. File, 'w') # Finally, create table and write to my. Out. File word_freq = dict([(word, my. Text. count(word)) for word in set(my. Text)]) for word, count in word_freq. items(): print(word, 't t', count, file=Out. File) #t tab Out. File. close() # return word_freq #if want to see what is written my. Out. File = my. Path + '/my. Den. Out. File. txt' Get. Freq. Words(my. Out. File, Merge. Strip. New. NSmy. Text)
#Let's get our bigrams of the non-tagged text def Get. Bigrams(my. Out. File, my. Text): bg = list(nltk. bigrams(my. Text)) # Let's get a list with counts of how frequent # they occur (counts of each) word_freq = dict([(word, bg. count(word)) for word in set(bg)]) Out. File = open(my. Out. File, 'w') #These next 2 lines need to be run together!!! for word, count in word_freq. items(): print(word, 't t', count, file=Out. File) #t tabs Out. File. close() #return word_freq #if want to see what is written my. Out. File = my. Path + '/my. Den. Out. File. Bigrams. Counts. txt' Get. Bigrams(my. Out. File, Merge. Strip. New. NSmy. Text)
Node. XL Basic
Node. XL Basic
Node. XL Basic
Resources • ftp: //public. dhe. ibm. com/software/analytics/sp ss/documentation/modeler/18. 0/en/Modeler. T ext. Analytics. pdf • http: //www. nltk. org/book • https: //nodexl. codeplex. com/releases/view/11 7659 Department of Business Information & Analytics