COMP 73307336 Advanced Parallel and Distributed Computing Dr

COMP 7330/7336 Advanced Parallel and Distributed Computing Dr. Xiao Qin Auburn University http: //www. eng. auburn. edu/~xqin@auburn. edu
")
Your Background Not-A-Quiz • • Have you taken the parallel and distributed computing (PDC) class? What lab assignments have you completed in the PDC class? What is your on-going dissertation or thesis research project? Is your current research project related to parallel and distributed computing?

Today’s Goal: • Course Objectives • Course Content & Grading • Answer your questions about COMP 7330/7336 • Provide you a sense of the trends that shape the parallel and distributed computing field

COMP 7330/7336: Semester Calendar See the class webpage for the most up to date version! http: //www. eng. auburn. edu/~xqin/courses/comp 7330

Will it be worthwhile?

Will it be worthwhile?

Will it be worthwhile?

Will it be worthwhile?

Will it be worthwhile?

Textbook Ananth Grama, Anshul Gupta, George Karypis, Vinpin Kumar, “Introduction to Parallel Computing”, Second Edition, Pearson, ISBN 0 -201 -64865 -2

Topic Coverage • Handouts, book chapters, and papers will be used as supplement course material. The course material will be posted online. • Covers (These topics may change) – Advances of technologies and system architectures for parallel and distributed computing – Parallel computing algorithms – Parallel programming models – Message Passing Interface – Convergence of parallel, distributed and cloud computing – Analytical modeling and system evaluation – Cloud Computing and Big Data

Course Syllabus • Prerequisite: – COMP 4300, Computer Architecture – COMP 4320, Introduction to Computer Networks • Midterm exam and Final exam • Grading – Class Participation 10% – Midterm 20% – Final 20% – Homework Assignment 20% – Research Projects 30%
 • Scale – Letter grades will be awarded based on")
Course Syllabus (cont. ) • Scale – Letter grades will be awarded based on the following scale. This scale may be adjusted upwards if it is necessary based on the final grades. – A 90 B 80 C 70 D 60 F < 60

Office Hours and Exams Office hours: MWF 10: 55 am-11: 55 am Mid-term W 10/9/2013

Am I going to read papers to you? • NO! • Papers provides a framework and complete background, so lectures can be more interactive. – You do the reading – We’ll discuss it • Projects will go “beyond”

Questions Please ask at any time!

The History 1969: CDC 6600 1 st system for scientific computing 1975: CDC 7600 1 st supercomputer 1985: Cray X-MP / 4 8 1 st vector supercomputer 1989: Cray Y-MP / 4 64 1993: Cray C-90 / 2 128 1994: Cray T 3 D 64 1 st parallel supercomputer 1995: Cray T 3 D 128 1998: Cray T 3 E 256 1 st MPP supercomputer 2002: IBM SP 4 512 1 Teraflops 2005: IBM SP 5 512 2006: IBM BCX 10 Teraflops 2009: IBM SP 6 100 Teraflops 2012: IBM BG/Q > 1 Petaflops Source: scc. acad. bg/ncsa/documentation/Presentations/Gi. Erbacci_slides. ppt

HPC Infrastructure for Scientific Which machine is the computing most energy efficient? Logical Name SP 6 (Sep 2009) BGP (jan 2010) PLX (2011) IBM P 575 IBM BG / P IBM IDATAPLEX SMP MPP Linux Cluster IBM Power 6 4. 7 Ghz IBM Power. PC 0, 85 GHz Intel Westmere Ec 2. 4 Ghz # of core 5376 4096 3288 + 548 GPGPU Nvidia Fermi M 2070 # of node 168 32 274 # of rack 12 1 10 Total RAM 20 Tera Byte 2 Tera Byte ~ 13 Tera Byte IBM 3 D Torus Qlogiq QDR 4 x Suse Red. Hat ~ 800 Kwatts ~ 80 Kwatts ~ 200 Kwatts > 101 Tera Flops ~ 14 Tera Flops ~ 300 Tera Flops Model Architecture Processor Interconnecti Qlogic Infiniband DDR 4 x on Operating AIX System Total Power Peak Performance

SP Power 6 @ CINECA - 168 compute nodes IBM p 575 Power 6 (4. 7 GHz) - 5376 compute cores (32 core / node) - 128 Gbyte RAM / node (21 Tbyte RAM) - IB x 4 DDR (double data rate) Peak performance 101 TFlops Rmax 76. 41 Tflop/s Efficiency (workload) 75. 83 % N. 116 Top 500 (June 11) - 2 login nodes IBM p 560 - 21 I/O + service nodes IBM p 520 - 1. 2 PByte Storage row: 500 Tbyte working area High Performance 700 Tbyte data repository

BGP @ CINECA Model: IBM Blue. Gene / P Architecture: MPP Processor Type: IBM Power. PC 0, 85 GHz Compute Nodes: 1024 (quad core, 4096 total) RAM: 4 GB/compute node (4096 GB total) Internal Network: IBM 3 D Torus OS: Linux (login nodes) CNK (compute nodes) Peak Performance: 14. 0 TFlop/s

PLX @ CINECA IBM Server dx 360 M 3 – Compute node 2 x processori Intel Westmere 6 c X 5645 2. 40 GHz 12 MB Cache, DDR 3 1333 MHz 80 W 48 GB RAM su 12 DIMM 4 GB DDR 3 1333 MHz 1 x HDD 250 GB SATA 1 x QDR Infiniband Card 40 Gbs 2 x NVIDIA m 2070 (m 2070 q su 10 nodi) Peak performance 32 TFlops (3288 cores a 2. 40 GHz) Peak performance 565 TFlops Single Precision o 283 TFlops Double Precision (548 Nvidia M 2070) N. 54 Top 500 (June 11)

Visualisation system • Visualisation and computer graphycs • Virtual Theater • 6 video-projectors BARCO SIM 5 • Audio surround system • Cylindric screen 9. 4 x 2. 7 m, angle 120° • Ws + Nvidia cards • RVN nodes on PLX system
 Space (TB) Connection Tecnology Disk Tecnology 2 x")
Storage Infrastructure System Available bandwidth (GB/s) Space (TB) Connection Tecnology Disk Tecnology 2 x S 2 A 9500 3, 2 140 FCP 4 Gb/s FC 4 x S 2 A 9500 3, 2 140 FCP 4 Gb/s FC 6 x DCS 9900 5, 0 540 FCP 8 Gb/s SATA 4 x DCS 9900 5, 0 720 FCP 4 Gb/s SATA 3 x DCS 9900 5, 0 1500 FCP 4 Gb/s SATA Hitachi Ds 3, 2 360 FCP 4 Gb/s SATA 3 x SFA 1000 10, 0 2200 QDR SATA 1 x IBM 5100 3, 2 66 FCP 8 Gb/s FC > 5, 6 PB
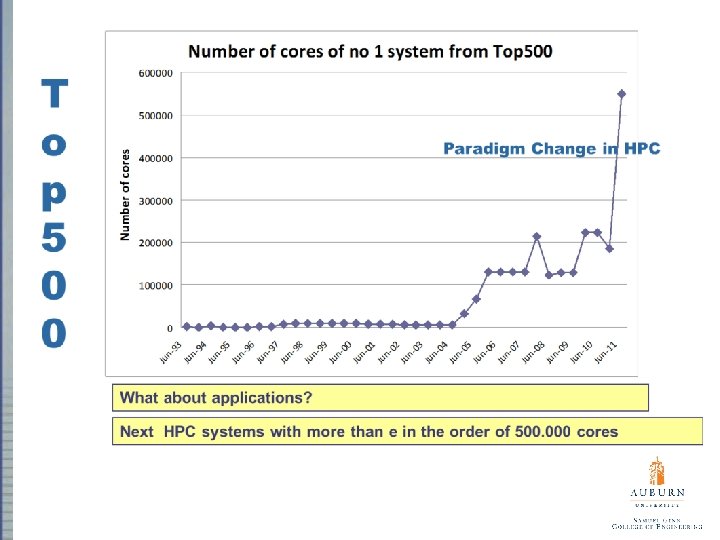

HPC Evolution Moore’s law is holding, in the number of transistors – Transistors on an ASIC still doubling every 18 months at constant cost – 15 years of exponential clock rate growth has ended Moore’s Law reinterpreted – Performance improvements are now coming from the increase in the number of cores on a processor (ASIC) – #cores per chip doubles every 18 months instead of clock – 64 -512 threads per node will become visible soon

Real HPC Crisis is with ____? A supercomputer application and software usually much more long-lived than a hardware - Hardware life typically four-five years at most. - Fortran and C are still the main programming models Programming is stuck - Arguably hasn’t changed so much since the 70’s Software is a major cost component of modern technologies. - The tradition in HPC system procurement is to assume that the software is free.

It’s time for a change • Complexity is rising dramatically • Challenges for the applications on Petaflop systems • The use of O(100 K) cores implies dramatic optimization effort • New paradigm as the support of a hundred threads in one node implies new parallelization strategies
 • Improvement of existing codes will become")
It’s time for a change (cont. ) • Improvement of existing codes will become complex and partly impossible • Implementation of new parallel programming methods in existing large applications has not always a promising perspective • There is the need for new community codes
")
Roadmap to Exascale (architectural trends)
- Slides: 32