LTPCL LTP remarks Carlo Caini LTPCL tuning LTPCL









- Slides: 11
LTPCL & LTP remarks Carlo Caini
LTPCL tuning
LTPCL aggregation: time and size limits • Aim: to save bandwidth by reducing LTP overhead • Mechanism: multiple bundles are aggregated into one LTP block until • Either a time aggregation limit expires • Or a size aggregation limit is exceeded • Time limit • A time limit (TL) introduces a corresponding delay at the beginning of a contact. • • • A new bundle is passed to LTPCL at contact start time (CST). The bundle however, is not encapsulated into an LTP block until (CST+TL). The first TL seconds of a contact are wasted. ETO in CGR/SABR is underestimated of TL • Proposed solution • To allow the user to select 0 instead of 1 second as a minimum aggregation time limit, to disable this feature if not desired (e. g. in tests) • Size limit • As the bundle aggregation stops after the size limit (SL) is exceeded, small bundles may be unsuitably aggregated to huge subsequent bundles • E. g. let SL 1 MB, if the first bundle is 900 k. B and the second is 10 MB the first is aggregated to the second leading to a block of 10. 9 MB. • Proposed solution • Check the size aggregation limit before aggregating the new bundle to the old ones. If the limit is exceeded, send the old bundle as one block, and start aggregating from the new.
LTPCL aggregation: priorities • Bundle of different priorities • LTP aggregation does not care about bundle priorities, thus high priority bundles can be aggregated to low priority bundles. • Once aggregated into the same LTP block the high priority bundle cannot be delivered until the aggregated block is received, i. e. it is delayed. • The problem is exacerbated by the fact that expedited bundles are usually shorter than bulk bundles • Best case: the delay is due only to the increased radiation time • Worst case: the delay can become huge if there are losses on the aggregated bundle, which is more likely if the LP bundle has a dominant dimension • Proposed solution • To avoid aggregating bundles of different cardinal priorities (or more generally, with different Qo. S requirements) • “Normal” rule: if HP bundles are waiting to be aggregated (as customary), stop aggregation when the first LP arrives; i. e. aggregate only the former and then re-start aggregation from the latter • “Exception” rule: If LP bundles are waiting to be aggregated, when the first HP arrives (it may happen) send the latter as a new block and continue aggregation of the former
LTP speed in ION
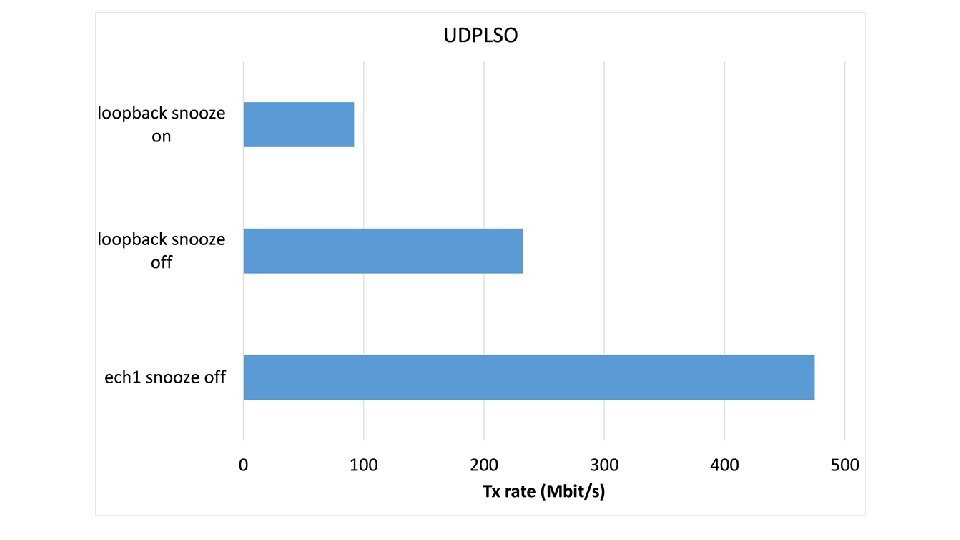
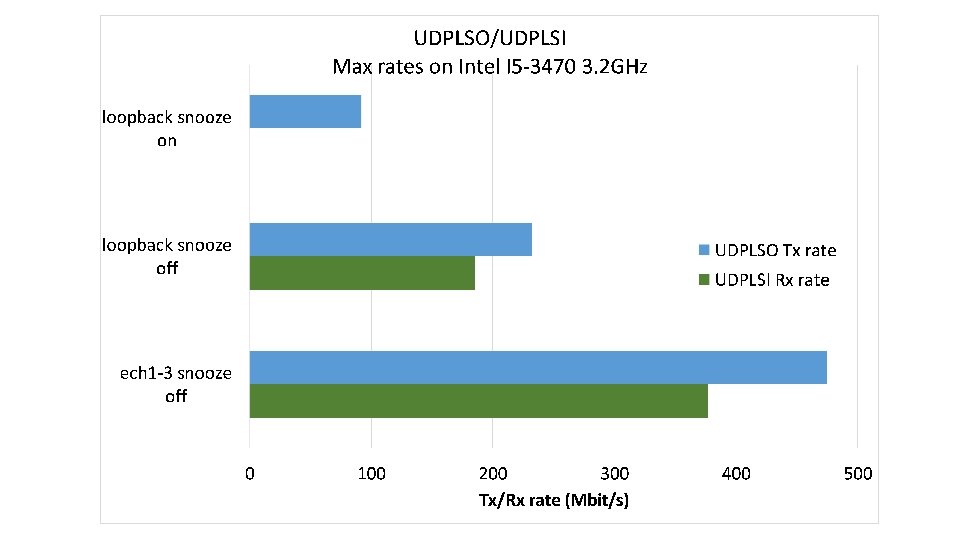
LTP segment rate control • Once bundle aggregation is terminated, a new LTP block (usually large) is created and then split into small LTP segments • UDPLSO • as UDP lacks rate control, LTP segments are not passed to UDP at full speed • a Tx rate control in udplso. c inserts a variable additional delay between a segment and the next, so that the interval between them is as close as possible to a target (inversely proportional to the wanted UDPLSO rate) • UDPLSI • reads the incoming UDP segments as soon as they arrive
UDPLSO • Punctual segment pacing perhaps not necessary • Average shaping, e. g. token bucket algorithm, could be a valid alternative • Problems to support high Tx rates (>100 Mbit/s) • Actual delays introduced by the microsnooze function are larger than expected • The value passed is actually a floor; when the value is small (min=1 microsecond in udplso. c code), the actual delay is longer • Processing time • Once removed the microsnooze, it is the sending cycle processing time that may become larger than the target interval • The corresponding Tx rate depends on the available CPU cycles • The result is that the maximum sending rate of udplso is limited and may become the bottleneck when high rates are requested
UDPLSI • In recent versions of ION, UDPLSI reads as fast as possible the incoming UDP segments • The reading cycle time determines the max Rx rate • If Tx -rate > Rx-rate , UDP segments accumulate in the UDP buffer, eventually resulting in LTP losses “internal” to the receiver • The insurgence of these losses limits the max Tx rate • The UDPLSI cycle reading time is dominated by the processing of the LTP segment itself • To go fast at Rx side, incoming LTP segments must be processed fast.
Conclusions • Current LTP implementation in ION is robust but not very fast • A few modifications in the LTP blue book specifications could help • Restricting LTP blocks to be “monochrome” (either red or green) • Fixed length fields (neither SDNV nor CBOR) • These modification could not be enough to reach high speeds • Andrea Bisacchi is developing an experimental LTP implementation as his master’s thesis in computer engineering • Speed as a primary design requirement