Graph Databases and Query Languages Graph Data Systems

Graph Databases and Query Languages


Graph Data Systems q Triple stores ü Typically, pattern-matching queries and inferencing ü Data model: RDF q Graph databases ü Typically, navigational queries ü Prevalent data model: property graphs q Graph processing systems (E. g. PREGEL) ü Typically, complex graph analysis tasks ü Prevalent data model: generic graphs ü Graph dataflow systems

• IBM System G

IBM System G Acomprehensive set of Graph Computing Tools, Cloud, and Solutions for Big Data. "G" stands for graphs -- large or small, static or dynamic, topological or semantic, and property or bayesian. It includes: • Graph Database, • plus Graph Visualizations • plus Graph Analytics Library • plus Graph Middleware for various hardware, for in-memory, and for distributed cluster • plus Network Science Analytics tools, including: Cognitive Networks, Cognitive Analytics, Spatiotemporal Analytics, and Behavioral Analytics • IBM System G can be used in many cases such as social network analysis, anomaly detection, smarter commerce, smarter planet, cloud, telecomm, etc. (Know more about solutions and use cases. . . )

Graph Data Systems q Triple stores ü Typically, pattern-matching queries and inferencing ü Data model: RDF q Graph databases üTypically, navigational queries üPrevalent data model: property graphs q Graph processing systems (E. g. PREGEL) ü Typically, complex graph analysis tasks ü Prevalent data model: generic graphs ü Graph dataflow systems

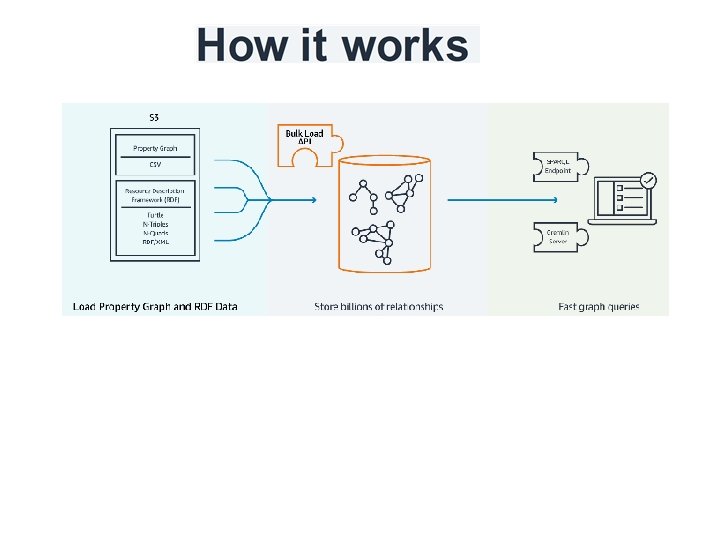
Amazon Neptune is a fast, reliable, fully-managed graph database service that makes it easy to build and run applications that work with highly connected datasets. The core of Amazon Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with milliseconds latency. Amazon Neptune supports popular graph models Property Graph and W 3 C's RDF, and their respective query languages Apache Tinker. Pop Gremlin and SPARQL, allowing you to easily build queries that efficiently navigate highly connected datasets. Neptune powers graph use cases such as recommendation engines, fraud detection, knowledge graphs, drug discovery, and network security.

Graph DBs: use cases
")
Use Cases (cont. )

Use Cases: Knowledge Graphs For example, if a user is interested in The Mona Lisa, you can also help them discover other works of art by Leonardo da Vinci, or other works of art located in The Louvre. Using a knowledge graph, you can add topical information to product catalogs, build and query complex models of regulatory rules, or model general information, like Wikidata.

Neptune: Life Science Neptune helps you build applications that store and navigate information in the life sciences, and process sensitive data easily using encryption at rest. For example, you can use Neptune to store models of disease and gene interactions, and search for graph patterns within protein pathways to find other genes that may be associated with a disease. You can model chemical compounds as a graph and query for patterns in molecular structures

Getting Started with Tinker. Pop and Gremlin • Tinker. Pop is a graph abstraction layer over different graph databases and different graph processors, so there are many Graph instances you can choose from to instantiate in the console. The best Graph instance to start with however is Tinker. Graph is a fast, in-memory graph database with a small handful of configuration options, making it a good choice for beginners. E. g. , start with the modern graph, below:
![Generating a Graph in gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0]](http://slidetodoc.com/presentation_image_h2/48e6549a67173336949c190ced202cb9/image-14.jpg "Generating a Graph in gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0]")
Generating a Graph in gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0] gremlin> v 1 = graph. add. Vertex(id, 1, label, "person", "name", "marko", "age", 29) ==>v[1] gremlin> v 2 = graph. add. Vertex(id, 3, label, "software", "name", "lop", "lang", "java") ==>v[3] gremlin> v 1. add. Edge("created", v 2, id, 9, "weight", 0. 4) ==>e[9][1 -created->3] There a number of important things to consider in the above code. First, recall that id and label are "reserved" for special usage in Tinker. Pop. . You would normally refer to them as T. id and T. label.
![Visiting a Graph gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0] gremlin>](http://slidetodoc.com/presentation_image_h2/48e6549a67173336949c190ced202cb9/image-15.jpg "Visiting a Graph gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0] gremlin>")
Visiting a Graph gremlin> graph = Tinker. Graph. open() ==>tinkergraph[vertices: 0 edges: 0] gremlin> v 1 = graph. add. Vertex(id, 1, label, "person", "name", "marko", "age", 29) ==>v[1] gremlin> v 2 = graph. add. Vertex(id, 3, label, "software", "name", "lop", "lang", "java") ==>v[3] gremlin> v 1. add. Edge("created", v 2, id, 9, "weight", 0. 4) ==>e[9][1 -created->3] There a number of important things to consider in the above code. First, recall that id and label are "reserved" for special usage in Tinker. Pop. . You would normally refer to them as T. id and T. label

Let’s start with finding "marko". This operation is a filtering step as it searches the full set of vertices to match those that have the "name" property value of "marko". This can be done with the has() step as follows: gremlin> g. V(). has('name', 'marko') ==>v[1] Now that Gremlin has found "marko", he can now consider the next step in the traversal where we ask him to "walk" along "created" edges to "software" vertices. As described earlier, edges have direction, so we have to tell Gremlin what direction to follow. In this case, we want him to traverse on outgoing edges from the "marko" vertex. For this, we use the out. E step. gremlin> g. V(). has('name', 'marko'). out. E('created') ==>e[9][1 -created->3]

Finally, now that Gremlin has reached the "software that Marko created", he has access to the properties of the "software" vertex and you can therefore ask Gremlin to extract the value of the "name" property as follows: gremlin> g. V(). has('name', 'marko'). out('created'). values('name') ==>lop You should now be able to see the connection Gremlin has to the structure of the graph and how Gremlin maneuvers from vertices to edges and so on. Your ability to string together steps to ask Gremlin to do more complex things, depends on your understanding of these basic concepts. Graph Traversal - Increasing Complexity…

 Lovers Ian Robinson, Jim Webber & Emil Eifren: Graph")
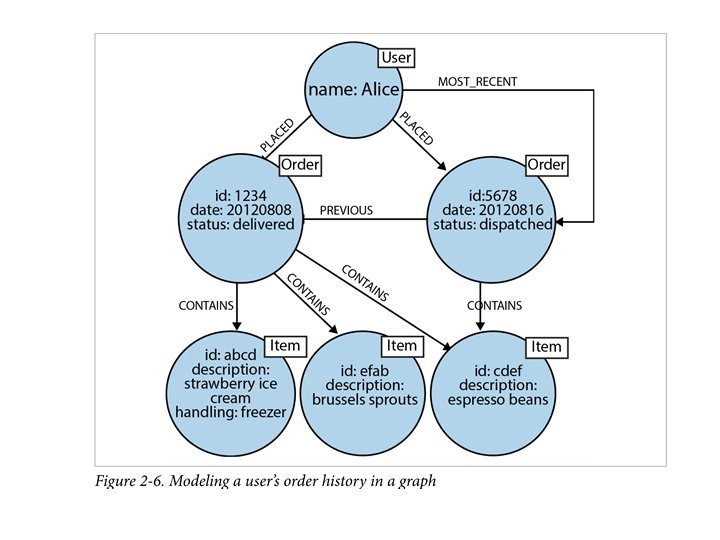
Friends, colleagues, workers and (unrequited) Lovers Ian Robinson, Jim Webber & Emil Eifren: Graph Databases, O’Reilly , 2015

Cypher

Cypher Queries c b a A Cypher query to find the mutual friends of a user named Jim:

Other Cypher Constructs WHERE: Provides criteria for filtering pattern matching results clause. E. g. instead of: We could have written: • UNION: Merges results from two or more queries. • WITH: Chains subsequent query parts and forwards results from one to the next. Similar to piping commands in Unix. • START: Specifies one or more explicit starting points—nodes. or relationships—in the graph. (START is deprecated in favor of specifying anchor points in a MATCH clause. )

Cypher Updates CREATE and CREATE UNIQUE: Create nodes and relationships. DELETE: Removes nodes, relationships, and properties. SET : Sets property values FOREACH: Performs an updating action for each element in a list.

Discussion • What will the future bring?
- Slides: 25