Econometria Estimao de Mxima Verossimilhana Estimao de Mxima





 = f(y 1| σ2, β). f(y 2| σ2, β)….")
 Equações de verossimilhanças: (1/n)Σi ∂logf(yi|")

 Consistência 2) Normalidade assintótica 3) Eficiência: o limite inferior de")

 =")
")






- Slides: 19
Econometria Estimação de Máxima Verossimilhança
Estimação de Máxima Verossimilhança Define uma classe de estimadores com base em uma distribuição particular que por hipótese gerou as variáveis aleatórias observadas. Principal vantagem dos estimadores de Máxima Verossimilhança: dentre os estimadores consistentes e assintoticamente normais, todos têm propriedades assintóticas ótimas. Principal desvantagem: não são estimadores robustos a falhas nas hipóteses sobre a distribuição das variáveis aleatórias. Estimadores muito dependentes de hipóteses particulares.
EMV A distribuição de uma variável aleatória observada é escrita como função dos parâmetros a serem estimados f(yi|dados, β) = densidade de probabilidade| parâmetros.
EMV A função de verossimilhança é construída com base na densidade. Construção: Função de densidade de probabilidade conjunta da amostra observada – geralmente um produto quando os dados vêm de uma amostra aleatória (variáveis iid). f(y 1…. yn|β, σ2) = f(y 1| σ2, β). f(y 2| σ2, β)…. f(yn| σ2, β)
EMV Princípio da Verossimilhança da estimação dos parâmetros: o o o Podemos observar os valores amostrais de y, mas não os parâmetros. A função de densidade de probabilidade conjunta é função dos parâmetros dados os valores observados de y na amostra. Podemos escolher valores dos parâmetros de forma a maximizar a função conjunta, ou seja, a probabilidade de obter a amostra dada.
Função de verossimilhança L( |dados) = f(y 1| σ2, β). f(y 2| σ2, β)…. f(yn| σ2, β) L( |dados) = П f(yi| σ2, β) Log L( |dados) =Σ f(yi| σ2, β).
EMV O log da função de verossimilhança: log-L( |dados) Equações de verossimilhanças: (1/n)Σi ∂logf(yi| )/∂ EMV = 0. “Condição de primeira ordem” para maximização Uma condição de momento – seu análogo é o resultado fundamental - E[ log-L/ ] = 0.
Tempo médio antes da falha Estimando o tempo médio antes da falha, , de lâmpadas. yi = vida útil da lâmpada. f(yi| )=(1/ )exp(-yi/ ) L( )=Πi f(yi| )= -N exp(-Σyi/ ) log. L ( )=-Nlog ( ) - Σyi/ Equação de verossimilhança: ∂log. L( )/∂ =-N/ + Σyi/ 2 =0 Note que: ∂logf(yi| )/∂ = -1/ + yi/ 2 Como E[yi]= , E[∂logf( )/∂ ]=0.
Propriedades do EMV 1) Consistência 2) Normalidade assintótica 3) Eficiência: o limite inferior de Cramer – Rao é atingido (versão assintótica de Gauss Markov) 4) Invariância. A estimação de funções não linearers dos parâmetros é relativamente fácil.
Modelo linear normal Definição da função de verossimilhança – densidade conjunta dos dados observados, escrita como função dos parâmetros que gostaríamos de estimar. Definição do estimador de máxima verossimilhança como a função dos dados observados que maximiza a função de verossimilhança ou seu logarítimo. Para o modelo: yi = xi + i, onde i ~ N[0, 2], os EMV para e 2 são: b = (X X)-1 X y e s 2 = e e/n. MQO é o EMV para as inclinações, mas a estimativa da variância não faz a correção pelos gl, sendo um EMV viesado.
Modelo linear normal Log da função de verossimilhança = i log f(yi| ) = soma dos logs das densidades. Para o modelo de regressão linear com termos de erro normalmente distribuídos, temos: log-L = i [ - ½log 2 - ½(yi – xi )2/ 2 ].
Equações de verossimilhança O estimador é definido conforme: log-L/ = 0. (equação de verossimilhança) O vetor de derivadas da funçao de verossimilhança é a função score. Para o modelo de regressão, g = [ log-L/ , log-L/ 2]’ = log-L/ = i [(1/ 2)xi(yi - xi ) ] log-L/ 2 = i [-1/(2 2) + (yi - xi )2/(2 4)] Para o modelo de regressão linear , a primeira derivada é: (1/ 2)X (y - X ) (K 1) e (1/2 2) i [(yi - xi )2/ 2 - 1] (1 1)
Matriz informacional O negativo da matriz de segundas derivadas da log -verossimilhança, -H = Matriz de informação. É uma matriz aleatória.
Hessiana do modelo linear Elementos fora da diagonal terão esperança igual a zero!
Estimação da matriz informação
Limite inferior de Cramer Rao o A variância assintótica de um estimador consistente e com distribuição assintótica normal para um vetor de parâmetros θ, será sempre maior ou igual ao limite inferior de Cramer – Rao: o A variância assintótica do EMV é igual ao limite inferior de Cramer Rao
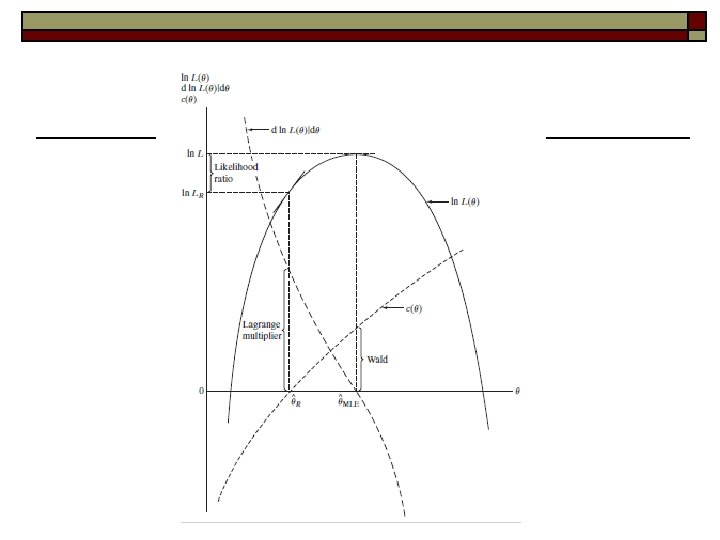
Testes de Hipóteses clássicos Razão de verossimilhança: Baseado na proposição de que restrições podem ser “ruins” Será que a redução no critério (log da verossimilhança) é alto? Multiplicador de Lagrange: Examinar as condições de primeira ordem. Se o gradiente é significativamente “não zero” para o estimador restrito. Wald: já visto.
Testes de Hipóteses clássicos Razão de verossimilhança: Baseado na proposição de que restrições podem ser “ruins” Será que a redução no critério (log da verossimilhança) é alto? Multiplicador de Lagrange: Examinar as condições de primeira ordem. Se o gradiente é significativamente “não zero” para o estimador restrito. Wald: já visto.