Doubly Linked Lists CS 308 Data Structures Node

Doubly Linked Lists CS 308 – Data Structures

Node data • info: the user's data • forw, back: the address of the next and previous node in the list . back . info . next
 template<class Item. Type> struct Node. Type { Item. Type info;")
Node data (cont. ) template<class Item. Type> struct Node. Type { Item. Type info; Node. Type<Item. Type>* next; Node. Type<Item. Type>* back; };

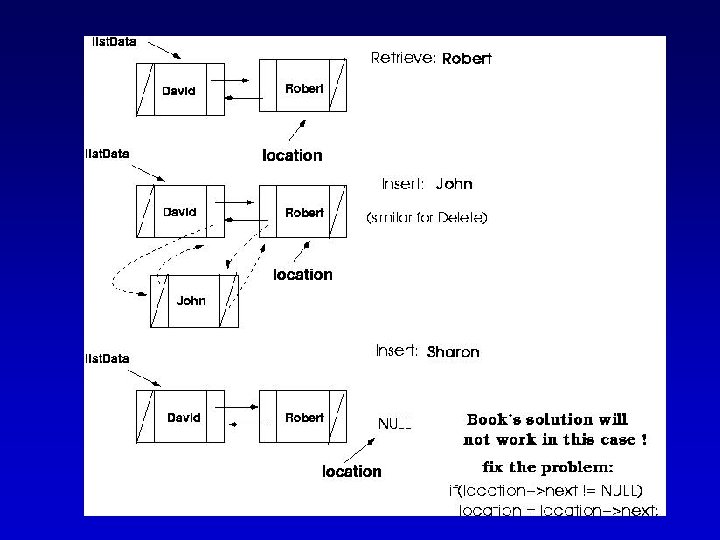
Finding a List Item • We no longer need to use prev. Location (we can get the predecessor of a node using its back member)
")
Finding a List Item (cont. )

Inserting into a Doubly Linked List 1. new. Node->back = location->back; 3. location->back->next=new. Node; 2. new. Node->next = location 4. location->back = new. Node;
 • Retrieve. Item, Insert. Item, and Delete. Item")
Find. Item(list. Data, item, location, found) • Retrieve. Item, Insert. Item, and Delete. Item all • • • require a search ! Write a general non-member function Find. Item that takes item as a parameter and returns location and found. Insert. Item and Delete. Item need location (ignore found) Retrieve. Item needs found (ignores location)
 template<class Item. Type> void Find. Item(Node. Type<Item. Type>*")
Finding a List Item (cont. ) template<class Item. Type> void Find. Item(Node. Type<Item. Type>* list. Data, Item. Type item, Node. Type<Item. Type>* &location, bool &found) { // precondition: list is not empty else { if(location->next == NULL) bool more. To. Search = true; more. To. Search = false; else location = list. Data; location = location->next; found = false; } } while( more. To. Search && !found) { } if(item < location->info) more. To. Search = false; else if(item == location->info) found = true;

How can we distinguish between the following two cases?

Special case: inserting in the beginning

Inserting into a Doubly Linked List template<class Item. Type> void Sorted. Type<Item. Type>: : Insert. Item(Item. Type item) { Node. Type<Item. Type>* new. Node; Node. Type<Item. Type>* location; bool found; new. Node = new Node. Type<Item. Type>; new. Node->info = item; if (list. Data != NULL) { Find. Item(list. Data, item, location, found); else list. Data = new. Node; (3) if (location->info > item) { location->back = new. Node; (4) (1) new. Node->back = location->back; } new. Node->next = location; (2) if (location != list. Data) // special case (location->back)->next = new. Node; (3)
 else { // insert at the")
Inserting into a Doubly Linked List (cont. ) else { // insert at the end new. Node->back = location; location->next = new. Node; new. Node->next = NULL; } } else { // insert into an empty list. Data = new. Node; new. Node->next = NULL; new. Node->back = NULL; } length++; }

Deleting from a Doubly Linked List • Be careful about the end cases!!

Headers and Trailers • Special cases arise when we are dealing • with the first or last nodes How can we simplify the implementation? – Idea: make sure that we never insert or delete the ends of the list – How? Set up dummy nodes with values outside of the range of possible values
 • Header Node: contains a value smaller than •")
Headers and Trailers (cont. ) • Header Node: contains a value smaller than • any possible list element Trailer Node: contains a value larger than any possible list element

A linked list as an array of records • What are the advantages of using linked lists? (1) Dynamic memory allocation (2) Efficient insertion-deletion (for sorted lists) • Can we implement a linked list without dynamic memory allocation ?
")
A linked list as an array of records (cont. )

Case Study: Implementing a large integer ADT • The range of integer values varies from one • • computer to another For long integers, the range is [-2, 147, 483, 648 to 2, 147, 483, 647] How can we manipulate larger integers?
 - A special list ADT")
Case Study: Implementing a large integer ADT (cont. ) - A special list ADT

Exercises • 1, 6, 8, 10, 12
- Slides: 21