Big Data Myth Busters Benefiting from Big Data

Big Data Myth Busters Benefiting from Big Data Analytic Methods with Small Data Dan J. Putka Minnesota Professionals for Psychology Applied to Work (MPPAW) Minneapolis, MN May 16. 2017 Hum. RRO Headquarters: 66 Canal Center Plaza, Suite 700, Alexandria, VA 22314 -1578 | Phone: 703. 549. 3611 | www. humrro. org
 – Improve the algorithm Netflix")
A little story ● The Netflix Prize (2006 -2009) – Improve the algorithm Netflix uses to recommend movies to customers based on their previous movie ratings – Crowdsourced prediction contest - $1, 000 grand prize ● What does this have to do with I-O work? – Movies jobs: Parallels to person-job fit and selection/classification – Prediction methods went far beyond what is typically used in I-O psychology – Can new methods improve our ability to predict and understand criteria we care about? 2

Modern prediction methods and concepts ● The past 25 years have seen an explosion of research and application of new prediction methods and concepts ● Advances in linear models (e. g. , lasso, elastic nets) ● Advances in non-linear models (e. g. , random forests, gradient boosted trees, support vector machines, neural networks) ● New concepts that facilitate building better models (e. g. , bagging, boosting, diversity, ensembles, tuning, learning rate) 3

Myths about modern prediction methods “These new methods are irrelevant to me, I don’t deal with Big Data. ” “Bah! You’re just capitalizing on chance. Predictions from these new methods won’t generalize to new samples. ” “These new methods are black boxes. They won’t help me understand what’s driving prediction. ” “The results from these methods are too complex to convey to decision makers. ” “These new methods may help with prediction, but they have no theoretical value. ” 4

Where we go from here… ● A brief prediction primer ● Myth busting! ● An applied example – Recasting biodata keying as a modern modeling problem 5

A brief prediction primer

Two general types of prediction problems ● Classification problems – Predicting membership in two or more categories • Turnover (stayers vs. leavers) • Training (pass vs. fail) ● Regression problems – Predicting a continuous numeric outcome • Job performance • Employee engagement • Job satisfaction 7

Our default, go-to prediction methods ● I-O psychology graduate students have traditionally received training on a very narrow set methods for addressing these problems – Classification problems • Logistic regression and discriminant analysis (full, stepwise, and multilevel variants) – Regression problems • Ordinary least squares regression (full, stepwise, and multilevel variants) 8

Reality ● Today, the number of methods available for addressing prediction problems is staggering and continuously expanding ● Example: ~160 classification models and ~128 regression models available through R’s caret machine leaning package http: //topepo. github. io/caret/bytag. html ● When coupled with the ability to blend predictions from multiple models into new ensembles, the possibilities become limitless 9

Why should we care? Potential for… ● ● ● Improved prediction of valued criteria Improved understanding of how predictor content links to criteria Improved prediction + improved understanding better interventions/outcomes 10

Let the busting begin

Myth #1 “These new methods are irrelevant to me, I don’t deal with Big Data. ” 12

Myth #1: Kernel of truth ● Few of us deal with truly Big Data in research and practice ● When conducting empirical research, many still worry about having enough data, rather than too much of it! ● Small sample sizes in I-O and management research in general – Mdn n: 88 to 343 in JAP from 1920 -2008 (Austin et al. , 2002; Shen et al. , 2011) – Even smaller sample sizes for group and macro-level research 13

Debunking Myth #1 ● Tendency to label modern methods as Big Data prediction methods – Case in point, the title of my talk! – Labeling facilitates marketing of methods, but gives a false impression ● Easy to believe that recent developments bear no immediate relevance to traditionally-sized validation and prediction efforts ● Many modern prediction methods can have value for data big and small 14

Why? ● Building a prediction model is a balancing act… – Overfitting the model over-utilizing the available data • Model is too complex • Example: Predicting job performance with GMA, the Big Five, and all two and three way interactions among them – Underfitting the model under-utilizing the available data • Model is too simple • Example: Predicting job performance with a unit weighted composite of GMA and the Big Five ● Overfitting and underfitting both lead to lower cross-validities 15 15

Modern methods help strike a balance ● Offer the ability to tune or more meta-parameters that govern the complexity of a model ● Model tuning and estimation is done with cross-validation as a primary concern ● Striking a balance is even more important when we have limited data! “Bah! You’re just capitalizing on chance. Predictions from these new methods won’t generalize to new samples. ” 16 16

Contrast with traditional methods ● How do we typically balance overfitting and underfitting? Traditional Perspective Modern Perspective • Aggregate items to form scale or instrument-level scores based on psychometric theory • Consider theoretically informed constraints up front, but have greater flexibility to evaluate them • Exclude predictors and limit interactions/nonlinearities based on prevailing theories in a domain of interest • Optimally scale the complexity of the model through tuning, rather than through limited sample size rules • Limit the number of predictors based on rules of thumb for simple regression models • Proactively factor cross-validation into the model building and estimation process, rather than looking at it as something beyond our control • Estimate cross-validity after the fact 17

Myth #2 “These new methods are black boxes. They won’t help me understand what’s driving prediction. ”

Myth #2: Kernel of truth ● ● ● Many modern methods look like black boxes (and some are) Hard to assign a single number that says: “here’s the direction/strength of the relationship between X and Y” However, we can do plenty to understand… – How well the model will predict in future samples of data – What variables are driving model prediction – The form of the relationship between a predictor and model predictions …and readily convey that information to decision makers! 19

Debunking Myth #2 ● Like traditional models, we can produce common estimates of model performance – R 2, cross-validated R 2 ● Like traditional models, we can translate validity estimates into more accessible metrics – Expectancy charts – Input into Taylor-Russell tables expected increase in % of successful performers – Input into utility formulae (e. g. , BCG) expected benefit in dollars “The results from these methods are too complex to convey to decision makers. ” 20

Debunking Myth #2 ● Like traditional models, we can produce estimates of predictor importance – Using relative weights analysis (RWA) to generate predictor importance estimates in lasso and elastic net models – Predictor importance estimates are available for several non-linear methods as well (e. g. , random forests, gradient boosted trees) ● We can summarize predictor importance estimates in pie charts, bar charts, and heat maps – oh my! 21

Debunking Myth #2 22

Debunking Myth #2 Average Y-Hat We can generate partial dependence plots to visualize relationships between individual predictor variables and model predictions Average Y-Hat ● x 6 x 259 23

Myth #3 “These new methods may help with prediction, but they have no theoretical value. ”

Myth #3: Kernel of truth Correlation =. 94 25

Myth #3: Kernel of truth ● Modern prediction methods are limited for… – Distinguishing between and estimating direct and indirect effects of predictors on a criterion – Evaluating causal arguments ● Both of the above are often viewed as central to theory testing and informing the design of organizational interventions – SEM + careful study design 26

Debunking Myth #3 ● Modern methods offer opportunities for gaining new insights into predictorcriterion relations ● They can facilitate building and refining of theories of interest in I/O – Psychometric theory – Theories of individual differences – Theories of performance determinants – Theories of engagement/turnover 27

Debunking Myth #3: Examples ● We find modern prediction methods outperform a simple, theory-based model upon cross-validation – Benchmarking theory-based models against what is possible vs. R 2 = 0 – Where is theory-based model falling short? – Where are the gaps in our knowledge? ● We find modern prediction methods with item-level predictors outperform a model using theory-based scale-level predictors upon cross-validation – Psychometric theory typically views item-specificity as error variance – Such a finding would suggest such specificity may have value – What characteristics of items are driving prediction beyond construct-based explanations? 28

An applied example

The case of biodata ● ● ● Long history within personnel selection Rational vs. empirical keying A variety of empirical keying methods exist – Largely ad-hoc rules developed in the 1920 s-1960 s – pre computer era ● Recast biodata keying as a modern modeling problem – Formalizes the problem of linking biodata to criteria – Takes advantage of modern advances in prediction theory/technology – Enables new insights into links between biodata content and criteria 30

The data ● Archival data on 9, 000+ individuals participating in a multi-month leadership training course Predictors – Rationally keyed biodata inventory designed to predict leader performance and retention – 83 biodata items designed to measure 12 constructs – 12 construct-focused scales (average α =. 72) Criterion – Multifaceted performance composite including performance on various leadership exercises as rated by multiple instructors, academic performance, ratings of future leader potential 31
 of a suite of modern prediction")
Method ● Evaluated the performance (cross-validated R 2) of a suite of modern prediction methods versus traditional methods – Traditional Methods: Full OLS regression, stepwise regression, CART – Modern Prediction Methods • Least angle regression and elastic nets extension of simple linear regression models well suited to striking balance between overfitting/underfitting • Random forests and gradient boosted trees extension of CART well suited to striking balance between overfitting/underfitting + handing nonlinearities and interactions • Support vector machines (SVM) grounded in statistical learning theory – ask me over a beer ● Compared models that used item-level data as predictors (p = 83) and models that examined construct-level scales as predictors (p = 12) 32

Method ● Randomly selected 20% of the full sample to form an independent cross-validation sample (n = 1, 852) on which to evaluate model performance ● Subsampled remaining 7, 405 individuals to create model development samples of varying size – n = 100, 150, 200, 300, 400, 500, 650, 800, 1, 110, and 1, 500 – Represented broad range of sample size to # of predictor ratios (n/p) – Replicated sampling process 30 times ● Examined variation in item-level importance indices stemming from each prediction method as a function of… – The type of construct each item was written to assess – Other item-level characteristics (e. g. , Mael’s taxonomy of biodata item types) 33

Cross-validation results
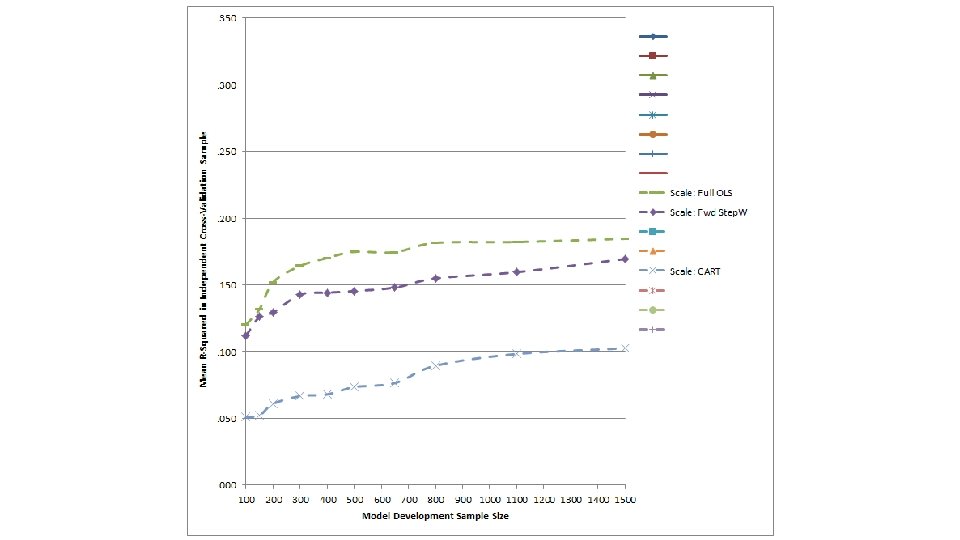
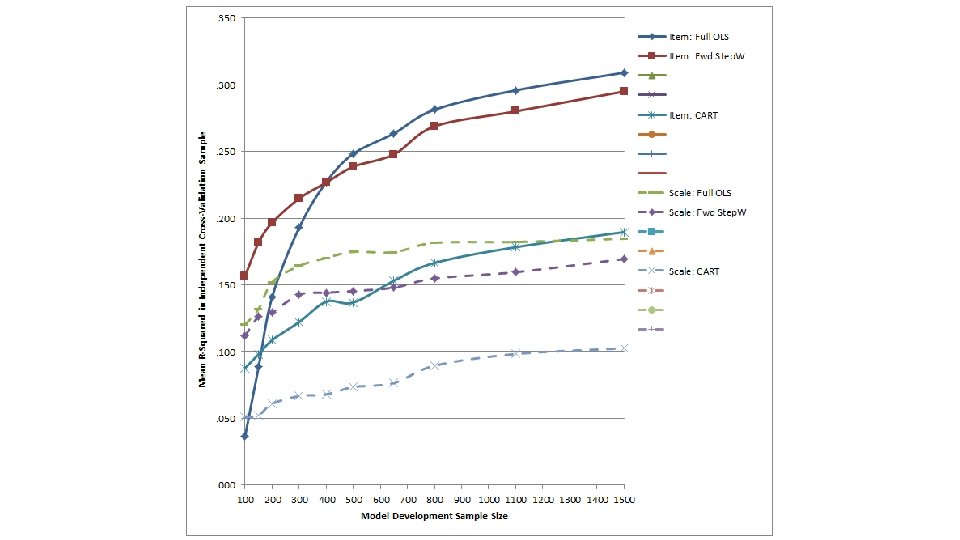
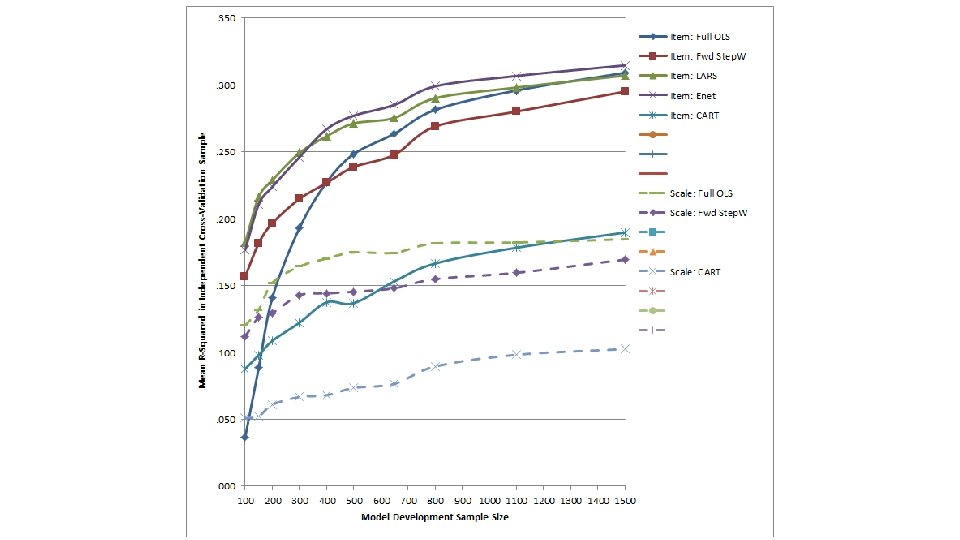
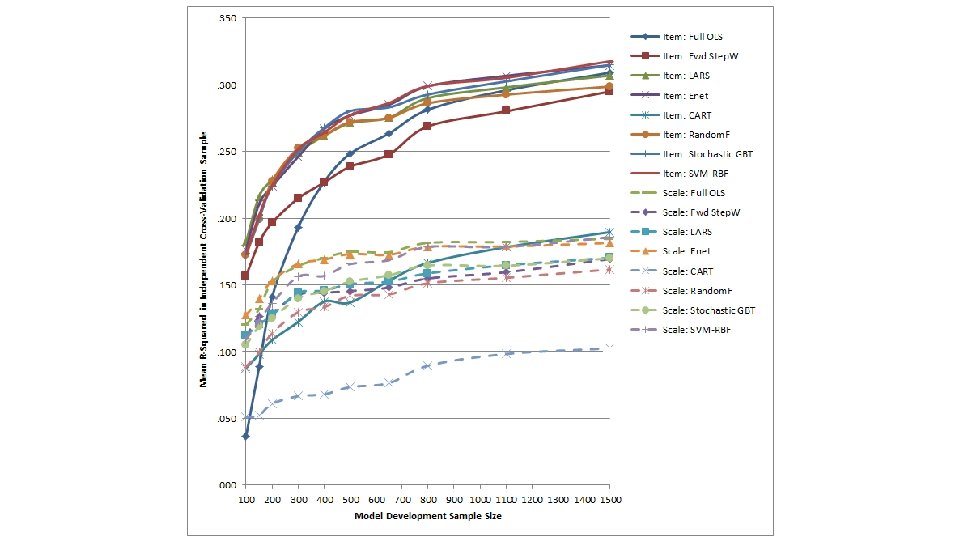

Insights into biodata item functioning

Item-level importance Aside: Construct A α =. 74, Construct B α =. 79 41

Item importance by item characteristic 42

Final thoughts

Where may modern methods have the most value? ● ● ● Item-level data from assessment methods that historically suffered from construct validity or internal consistency problems – Biodata - SJTs – simulations – ACs – Item specificity may have value for prediction Situations where theory linking to predictors to criteria is sparse – Predictor data resulting from parsing of text or speech – Item-level data of the type described above – New criteria without a deep research literature Predictor content where interactions or nonlinearities are likely – Person-job fit and person-organization fit content (e. g. , values/interests/preferences) – Situational judgment tests with w/ effectiveness rating response formats 44

Where may modern methods have the most value? ● Situations where there is a relatively large number of potential predictors (p) compared to the available sample size (n) - but there are limits to this! ● Situations where we have a solid criterion measure – Be wary of optimizing prediction against “error” or a criterion that’s not defensible 45
 Elements of Statistical Learning –")
Learning more…in general ● Hastie et al. ’s (2009) Elements of Statistical Learning – http: //statweb. stanford. edu/~tibs/Elem. Stat. Learn/ ● James et al. ’s (2013) Introduction to Statistical Learning with Applications in R – http: //www-bcf. usc. edu/~gareth/ISL/ ● Kuhn & Johnson’s (2013) Applied Predictive Modeling – http: //appliedpredictivemodeling. com/ More theoretical More practical 46

Learning more…with an I-O perspective ● Tonidandel, S. , King, E. B. , & Cortina, J. M. (Eds. ). (2015). Big data at work: The data science revolution and organizational psychology. New York: Routledge. ● Putka, D. J. , Beatty, A. , & Reeder, M. (2017). Modern prediction methods: New perspectives on a common problem. Organizational Research Methods. Online at: http: //journals. sagepub. com/doi/full/10. 1177/1094428117697041 ● Oswald, F. & Putka, D. J. (2016). Big Data predictive analytics: A hands-on workshop using R. Friday seminar delivered at the 2016 SIOP Conference. 47

Questions? Dan Putka dputka@humrro. org
- Slides: 47