Billions and Billions of Likes Understanding and Representing

Billions and Billions of Likes: Understanding and Representing Online Science Enthusiasm Oliver Marsh Science and Technology Studies, University College London oliver. marsh. 13@ucl. ac. uk @Sideways. Science sidewayslookatscience. wordpress. com
 How to turn websites into datasets (Decisions and Scrapers) 2) How")
Today’s Talk 1) How to turn websites into datasets (Decisions and Scrapers) 2) How to use datasets (Visualisation and Computer Aided Text Analysis) 3) Reporting data ethically (Accountabilities and Aggregating)
")
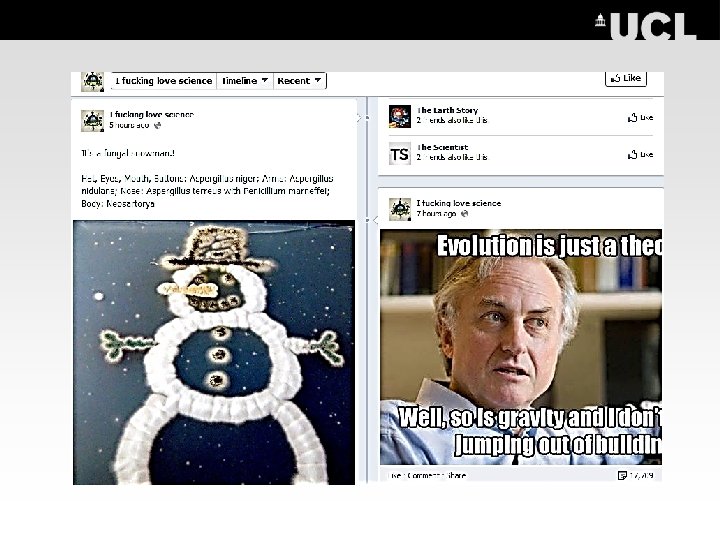
IFLScience (Facebook)

Subreddits – r/Science and r/Ask. Science
 IFLS 20 m r/Science r/Ask. Science #")
Some Quant Page Subscribers # Posts (March) IFLS 20 m r/Science r/Ask. Science # Comments & Replies (March 2015) Total Words (March 2015) Total likes / upvotes (March 2015) 275 (159 by 535041 + page, 116 by 81185 + 28109 users) 4. 8 m 17. 3 m 8. 7 m 593 16561 681, 000 320, 000 5. 7 m 989 9625 740, 000 137, 000

Computer Aided Text Analysis with Iramuteq

Some Concluding Advice • Approach problems of large digital datasets with traditional social science expertise – but also look into natively digital approaches (Marres and Gerlitz 2011, Rogers 2014). • Take time to become familiar with technical elements underlying any tools used (and websites studied). • Take an abductive approach (Mc. Cosker and Wilkin 2014, Smallman 2014). Do not treat any one tool as providing answers - constantly triangulate with different tools and methods. • Share expertise and experience – technical details, useful research methods, and approaches to ethical dilemmas (http: //ethics. aoir. org). Resources here! oliver. marsh. 13@ucl. ac. uk | @Sideways. Science | sidewayslookatscience. wordpress. com

Some Useful Resources Finding Scraper Tools: • The tools here are designed by academics, for academics https: //wiki. digitalmethods. net/Dmi/Tool. Database • Some social research tools now incorporate scraper tools, e. g. NVivo https: //www. youtube. com/watch? v=Rzub. Xk 30 Yfc • Finding existing examples http: //stackoverflow. com/questions/22168883/whats-thebest-way-of-scraping-data-from-a-website & http: //www. quora. com/Which-are-some-of-the-best-webdata-scraping-tools

Some Useful Resources Building Scraper Tools: • • I use the open source language Python – it’s more intuitive than many of the others https: //www. python. org/. It is a huge and ever-growing language so learn by doing – if you try to ‘get to grip with the basics’ before starting you might end up learning a lot of terms which you’ll never use http: //stackoverflow. com/ is a great forum for finding answers to annoyances, reddit’s r/python can be good too. But just googling any problems (particularly if your programme produces a certain error code) is often surprisingly efficient too. Many larger websites have their own ‘APIs’ (Application Programming Interfaces) and advice on how to use them, which can simplify programming (and also stop you accidentally annoying the websites…): https: //developers. facebook. com/docs/graph-api , http: //praw. readthedocs. org/en/latest/pages/getting_started. html. Though be careful – sites can also use APIs to control data output (boyd and Crawford 2011). A great example of sample code (and tutorial) which I used to develop my Facebook scraper http: //simplebeautifuldata. com/2014/08/25/simple-pythonfacebook-scraper-part-1/

Some Useful Resources Analysis and Visualisation: • • Good CATA tools I am familiar with are MALLET ( http: //mallet. cs. umass. edu/ ), IRAMUTEQ ( http: //www. iramuteq. org/ ), and OPENCALAIS ( http: //new. opencalais. com/ ). See also http: //web. mit. edu/ruggles/Mapping. Controversy/web-directory/336. html A popular network visualisation tool is Gephi http: //gephi. github. io/ , but it’s quite graphics-heavy; Pajek requires less computing power http: //vlado. fmf. unilj. si/pub/networks/pajek/.
- Slides: 11