Anthony Delprete Jason Mckean Ryan Pineres Chris Olszewski



 is a Object Oriented programming library The")

 Parallelism Computation where many calculations are")

")


 Regional Access (Flattening) - Ignores tiling and returns")

 2 for i = 2:")









- Slides: 23
Anthony Delprete Jason Mckean Ryan Pineres Chris Olszewski
Overview • • History and Purposes Tiles, Locality and Parallelism Structure, Creation of and Accessing HTAs Operations on HTAs o Communication and Global HTA Implementations HTA vs MPI Conclusion Resources
History Developed in 2004 by: Jia Guo, Ganesh Bikshandi, María J. Garzarán and David Padua Dept. of Computer Science U. of Illinois at Urbana-Champaign Basilio B. Fraguela Dept. de Electrónica e Sistemas Universidade da Coruña, Spain Gheorghe Almási and José Moreira IBM Thomas J. Watson, Research Center Yorktown Heights, NY, USA
Purpose • • Hierarchically Tiled Array (HTA) is a Object Oriented programming library The purpose of the library was to improve the programmability of distributed memory environments. This allows for improving performance by enhancing locality and parallelism. This was done through creating a new data type, HTA, allowing for easier manipulation of tiles.
What are Tiles, Locality and Parallelism? Tile • • • A tile is a block of information. It is used in scientific computing An example of a tile would be a matrix. Locality When the same value or location is frequently accessed. It is a predictable behavior that occurs in computers and is a good candidate for performance optimization • •
What are Tiles, Locality and Parallelism? (cont. ) Parallelism Computation where many calculations are carried out simultaneously. • • Based on the principle of taking a large problem and dividing it into smaller ones and solving them at the same time.
Structure of an HTA • • HTAs are arrays partitioned into tiles. The tiles can be arrays or other HTAs. Allows for easier access to a specific location in an array By distributing the tiles across processors, parallelism is carried out. By arranging the tiles in a certain order, locality can be utilized.
Structure of an HTA (cont. )
Creating an HTA Using Existing Array Matrix and delimiters See picture • • New Empty HTA F = hta(3, 3) Must be assigned data to complete • •
Accessing the HTAs Contents Notation - { } used to index tiles - ( ) used to access elements within HTA or its tiles Accessing Tiles - C{2, 1} refers to the lower left tile Accessing Elements Directly - C(5, 4) refers directly to a specific element at 5, 4 Accessing Elements Relatively - C{2, 1}(1, 4) refers to lower left tile, element at 1, 4 - C{2, 1}{1, 2}(1, 2) refers to lower left tile, upper right tile of {2, 1}, element at 1, 2
Accessing the HTAs Contents (cont. ) Regional Access (Flattening) - Ignores tiling and returns array - C(1: 2, 3: 6) returns a 2 x 4 matrix Logical Indexing/Selection - Matrix of boolean values with same dimensions as HTA
Communication Operations • • • Some of the overloaded array operations provided by the HTA library. • HTAs execute these operations at the tile level. o When circular shift is called, whole tiles are shifted instead of individual array elements. Communication is represented as assignments on distributed HTAs. o V{2: 3, : }(1, : ) = V{1: 2, : }(5, : ) Can also be represented by overloaded HTA library methods. Permute Operations o permute(h, [x, y]) o dpermute{h, [x, y]} § Operates on a 3 D array.
Matrix Multiplication 1 function C = cannon(A, B, C) 2 for i = 2: m 3 A{i, : } = circshift(A{i, : }, [0, -(i 4 1)]); 5 B{: , i} = circshift(B{: , i}, [-(i-1), 6 0]); 7 end 8 9 for k = 1: m - 1 10 C = C + A * B; 11 A = circshift(A, [0, -1]); B = circshift(B, [-1, 0]); end MATLAB Code for Cannon's Algorithm using HTAs • Cannon's Algorithm for matrix-matrix multiplication shows how circular shift can be used to distribute work. • Normal Implementation o Shift rows and columns o Perform multiplication by element HTA Implementation o Shift entire tiles o Perform multiplication as matrix multiplication of tiles where each processor or unit owns a tile. • • HTA Implementation increases locality due to single matrix multiplication. o Can increased even further if more levels of tiling are used.
Global Computations Passing an HTA to a function/operation • • Operates in parallel on a set of tiles from an HTA distributed across a parallel machine par. HTA(@func, H) where func is a function pointer Reduction • • reduce(+, [5, 1, 3, 8]) = 17 An operation applied to all the specified regions of a n dimensional vector to produce a scalar, producing a n-1 dimensional array. o If no dimension is given, the output contains only one scalar in each tile, corresponding the associated input HTA tile in every dimension. reduce. HTA(op, dim, recur. Level, replic. Flag) o op = any associative and commutative operation o dim = dimension of the reduction o recur. Level = termination level of recursion o replic. Flag = replication flag
Matrix-Vector Product • The simplest global computation is achieved by operating in parallel on a set of distributed tiles from an HTA. • Matrix-vector multiplication is one example of utilizing HTA global computation. • A is an HTA containing the matrix MX MATLAB code implementing HTA o Distributed across m n processors. Sparse Matrix-Vector Multiplication B is a two-dimensional HTA obtained by replicating the HTA V which contains the vector VX to multiply. The HTA V is replicated m times as specified by the operator repmat(V, m, 1). • • 1 2 3 4 5 6 A = hta(MX, {partition_A}, [m n]); V = hta(VX, {partition_B}, [m n]); B = repmat(V, m, 1) B = par. HTA(@tranpose, B) C = reduce. HTA(@sum, A * B, 2, true); Before multiplication, the row-vector B is transposed to a column. The matrix-vector product A * B takes place locally and each processor multiplies its portion of the matrix A by its portion of the vector in B.
HTA Implementations • HTAs can be added to almost any object-based or object oriented language. • Most research was done on MATLAB and C++
MATLAB Implementation Pros • • Overall MATLABS syntax lends itself to HTAs MATLAB provides a rich set of scientific operations which can be easily incorporated in the HTA toolbox. Cons • There is an immense overhead when MATLAB is interpreted. o MATLAB creates temporary variables to hold the partial results of an o expression. Greatly slows the program. MATLAB passes parameters by value and copies of the data are created from assignment statements.
C++ Implementation: htalib Why C++ over MATLAB? • Allocation/Deallocation improves performance: a. b. c. • HTAs are allocated onto the heap. Return a handle Typically small in size Once all handles are removed, HTAs are deleted. Inline functioning o o Compiler will replace functions with their full body of instructions. Used for Tile access
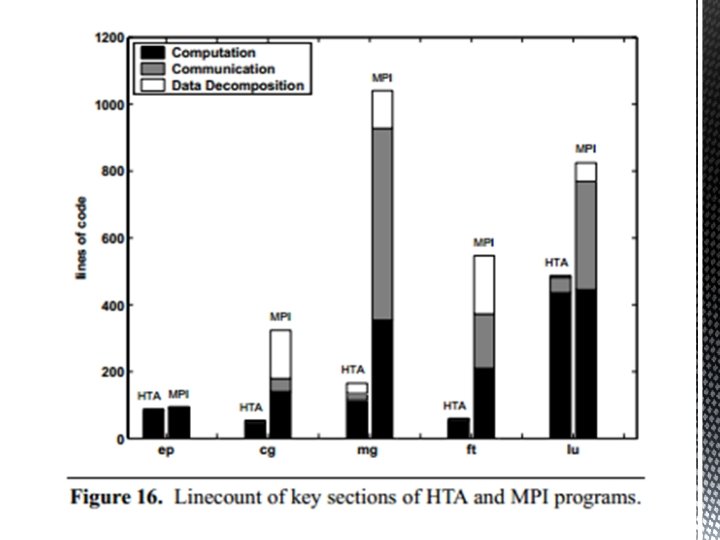
HTA compared to MPI • HTAs can be naturally implemented into many different languages. § MPI's unstructured manner, can potentially lead to programs that are difficult to understand maintain • Follows a single threaded programming approach. § • eases the programmer from sequential to parallel programming HTAs are partitioned using the single HTA constructor. § MPI has to make a lot more computations • The lines of code for communication is significantly lower in HTA.
Conclusion • • • Data Tiling is an effective mechanism for improving performance for both locality and parallelism. HTA as a library gives the programmer more control. HTAs facilitate algorithms that use multiple independent CPUs.
Resources Bikshandi, Ganesh, et al. "Programming for parallelism and locality with hierarchically tiled arrays. " Proceedings of the eleventh ACM SIGPLAN symposium on Principles and practice of parallel programming. ACM, 2006. Basilio B. Fraguela , Jia Guo , Ganesh Bikshandi , María J. Garzarán , Gheorghe Almási , José Moreira , David Padua, The Hierarchically Tiled Arrays programming approach, Proceedings of the 7 th workshop on Workshop on languages, compilers, and runtime support for scalable systems, p. 1 -12, October 22 -23, 2004, Houston, Texas [doi>10. 1145/1066650. 1066657]
Anthony Delprete Jason Mckean Ryan Pineres Chris Olszewski