Using Language Data A handson introduction to Sketch


 is a collection of texts")
 • a corpus is a large collection of text that is")


 or node word")
 • query: entering a word/lemma/phrase into the")


")
 for ? ? ? 1 position to the")





 is that a given")


, see")


 • collocation: a sequence of words")
. Corpus Linguistics. In: Simpson, J.")
- Slides: 26
Using Language Data A hands-on introduction to Sketch Engine Dr Saskia Kersten Dr Cathy Lonngren-Sampaio Senior Lecturer in English Language & Communication s. kersten@herts. ac. uk c. lonngren-sampaio 2@herts. ac. uk
“The language looks rather different when you look at a lot of it at once” (Sinclair 1991: 100)
Corpus – A Definition “A corpus (plural corpora, …) is a collection of texts used for linguistic analyses, usually stored in an electronic database so that the data can be accessed easily by means of a computer. Corpus texts usually consist of thousands or millions of words and are not made up of the linguist’s or a native speaker’s invented examples but on authentic (naturally occurring) spoken and written language. ” http: //www. anglistik. uni-freiburg. de/seminar/abteilungen/sprachwissenschaft/ls_mair/corpus-linguistics
Corpus (pl. corpora) • a corpus is a large collection of text that is searchable • the software used to search a corpus is called a corpus query system (or sometimes concordancer) • there are various corpus query systems, some have to be installed on your computer, some are web-based, e. g. the Corpus of Contemporary American English (COCA, http: //corpus. byu. edu/coca/) • some commonly used corpus query systems are: • • • Ant. Conc Word. Smith Tools Sketch Engine the subscription web-based corpus query system that UH subscribes to Lex. Tutor. . .
Why use a corpus? • It allows you to explore patterns in naturally occurring language data no need to rely on intuition (alone) • A corpus search can be as simple or as complex as you want it to be
Accessing Sketch Engine See also separate worksheet Ø Log on to Study. Net Ø Go to Online Library Ø Search for “Sketch Engine” Ø Click on the link on the top of the results list
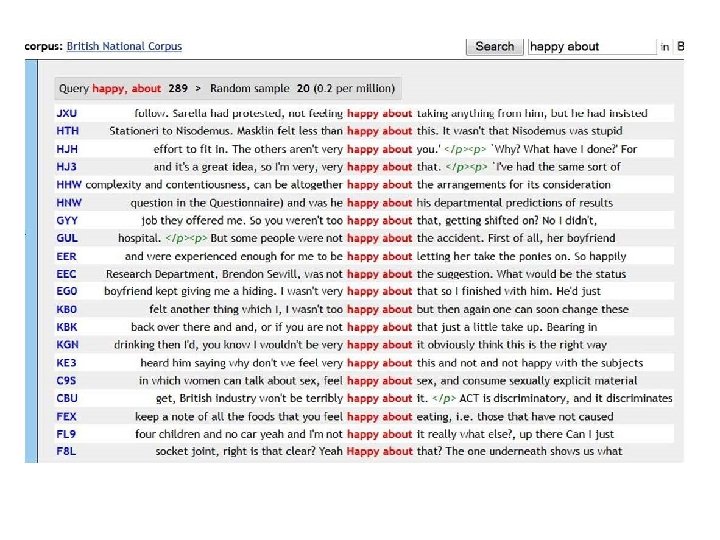
Lines of Concordance corpus ID KWIC (= Key word in context) or node word item that has been queried absolute and relative frequency of the queried item
Corpus Terminology (see also Sketch Engine Glossary) • query: entering a word/lemma/phrase into the search box of a specific corpus to retrieve lines of concordance • KWIC (= Key words in context), also node word, the form in the middle of the concordance column that matches the query • lines of concordance: individual lines of context around the queried word/lemma, the KWIC is normally highlighted and in the middle of these lines • lemma: the ‘dictionary version’ of a word, an abstract form which encompasses all possible forms of a word, e. g. go go, goes, going, went etc.
What can we do with corpora? quantitative analysis • What are the most frequent words in our corpus? rank order • How many instances of a given word are in the corpus? raw frequency • What percentage of the total number of words does the raw frequency represent? relative frequency • What are the most frequent collocations of a given word in our corpus? collocation candidates • What are the most frequent phrases of a given length? n-grams • What are the most frequent grammatical structures in our corpus? (Timmis 2015: 4)
Collocation “you shall know a word by the company it keeps” (Firth 1957: 11) Frequency-based definition: words that co-occur together more often than we would expect by chance Phraseological definition: arbitrary restrictions on substitutability (see e. g. Nesselhauf [2003] for a discussion)
Collocation candidates (simple query, attribute word) for ? ? ? 1 position to the left only, i. e. words directly preceding the mystery word Can you guess what the mystery word is?
BNC en. Ten 2008
en. Ten 2008 en. Ten 2013
Word Sketch - summary of a word’s behaviour “A word sketch is a one-page summary of the word’s grammatical and collocational behaviour. It shows the word’s collocates categorised by grammatical relations such as words that serve as an object of the verb, words that serve as a subject of the verb, words that modify the word etc. ” https: //www. sketchengine. co. uk/user-guide/user-manual/word-sketch/
Examples of a Word Sketch absolute frequency log. Dice score
Query the following and see if you can spot any patterns (focussing on the context to the right of the KWIC (group work) Group A: bordering on Group B: symptomatic of
Semantic Prosody “The notion of semantic prosody (or pragmatic meaning) is that a given word or phrase may occur most frequently in the context of other words or phrases which are predominantly positive or negative in their evaluative orientation [. . . ]. As a result, the given word takes on an association with the positive, or, more usually, the negative, and this association can be exploited by speakers to express evaluative meaning covertly. ” (Hunston & Thompson 1999, cited in Stewart 2010: 13)
Different Corpora View all in Sketch Engine, search for English
Representativeness of Corpora “designed to represent a wide cross-section of British English from the later part of the 20 th century” and “Work on building the corpus began in 1991, and was completed in 1994” (source) Web as Corpus UK, data obtained by crawling. uk domains, compiled in 2007
Corpora can also be used to… • … explore literary texts (Corpus Stylistics), see e. g. CLi. C Dickens project in Nottingham (http: //www. nottingham. ac. uk/research/groups/cral/projects/clic. aspx) • … map the emergence of words, ideas, concepts in everyday or specialised discourse, see e. g. the work by Grundmann and Krishnamurthy on climate change (http: //acorn. aston. ac. uk/RK-publications/2010 -CADAAD_Grundmann-and. Krishnamurthy. pdf) • … help with academic writing for both native and nonnative speakers • … scaffold foreign language learning • … explore language in any context imaginable (though you may have to compile your own corpus to do so )
Sk. ELL A pared down version of Sketch Engine for English Language Learners (Sk. ELL) is freely available online under http: //skell. sketchengine. co. uk/ There is also a version for mobile devices
Statistical Measures used in Corpus Linguistics (see also Anderson & Corbett 2009 and Sketch Engine’s Glossary) • Frequency (absolute/relative) • how often does a word occur in the corpus (absolute frequency) • how often does a word occur per 1 million/thousand/. . . words in the corpus (relative /normalised frequency) • Mutual Information (MI) • works by comparing the frequency of two words occurring together in a corpus, compared with the frequency of each word occurring independently, a high MI score suggests a significant association between words • log likelihood • compares observed corpus frequencies with expected frequencies (a log likelihood calculator and more details can be found here) • . . .
Corpus Terminology II (see also Sketch Engine Glossary) • collocation: a sequence of words that co-occur more often than would be expected by chance • Po. S: part of speech, the grammatical class of a word e. g. noun • word sketch: a corpus-based summary of a word's grammatical and collocational behaviour • keywords: words which are more frequent in one corpus compared to another • word list: a list of the words/lemmas occurring in a corpus ordered according to frequency • Text Type: a category or subcategory of a specific partition (usually the partitions are defined as documents) of the text of a corpus, the different texts in a corpus could e. g correspond to specific genres
References Adolphs, S. & Lin, P. M. S. (2011). Corpus Linguistics. In: Simpson, J. (ed. ), The Routledge Handbook of Applied Linguistics (pp. 597 -610). London: Routledge. Baker, P. (2006) Using Corpora in Discourse Analysis. London: Continuum. Baker, P. , Gabrielatos, C. , Khosravinik, M. , Krzyzanowski, M. , Mc. Enery, T. & Wodak, R. (2008) A useful methodological synergy? Combining critical discourse analysis and corpus linguistics to examine discourses of refugees and asylum seekers in the UK Press. Discourse and Society 19(3), 273 -306. Duguid, A. (2007) Men at Work: how those at Number 10 Construct their working Identity. In Garzone, G. and Srikant, S. (eds) Discourse, Ideology and Specialized Communication (pp. 453– 484). Bern: Peter Lang. Firth, J. R. (1957). A Synopsis of Linguistic Theory, 1930 -1955. In: J. R. Firth et al. Studies in Linguistic Analysis. Special volume of the Philological Society. Oxford: Blackwell. Gabrielatos, C. & Marchi, A. (2011). Keyness: Matching metrics to definitions. Corpus Linguistics in the South: Theoretical-methodological challenges in corpus approaches to discourse studies - and some ways of addressing them. University of Portsmouth, 5 November 2011. [http: //eprints. lancs. ac. uk/51449/] Gabrielatos, C. (2017). Clusters of Keyness. A principled approach to selecting key items. Corpus Linguistics in the South 15. University of Cambridge, 28 October 2017, https: //www. educ. cam. ac. uk/events/conferences/2017 corpusling/Clustersof. Keyness. CLS 15. pdf Mahlberg, M. , Stockwell, P. , de Joode, J. , Smith, C. & O’Donnell, M. B. (2016). CLi. C Dickens – Novel uses of concordances for the integration of corpus stylistics and cognitive poetics, Corpora, 11 (3), 433 -463. Mahlberg, M. (2016). Corpus Stylistics. In: Sotirova, V. (ed. , The Bloomsbury Companion to Stylistics (pp. 139 -156). London & New York: Bloomsbury. Partington, A. , Duguid, A. & Taylor, C. (2013). Patterns in Meaning and Discourse: Theory and practice in corpusassisted discourse studies (CADS). Amsterdam: John Benjamins. Krishnamurthy, R. (1996). Ethnic, racial and tribal: the language of racism? In: R. Caldas-Coulthard & M. Coulthard (eds), Texts and Practices: Readings in Critical Discourse Analysis (pp. 129– 49). London: Routledge. Sinclair, J. (1991). Corpus, Concordance, Collocation. Oxford: Oxford University Press. Stewart, D. (2010). Semantic prosody: A critical evaluation. New York: Routledge. Stockwell, P. & Mahlberg, M. (2015). Mind-modelling with corpus stylistics. David Copperfield. Language and Literature, 24(2), 129 -147. Timmis, I. (2015). Corpus linguistics for ELT: Research and practice. London: Routledge.