Efficient Selective Unduplication Using the MODIFY Statement Paul




. Keep")



")

- Slides: 12
Efficient Selective Unduplication Using the MODIFY Statement Paul M. Dorfman Independent SAS Consultant, Jacksonville, FL
ETL Scenario /* Extract from a DW, legacy system, whatever */ proc sql ; connect to … ; create table Extract from connection to …. . . order by <what-we-need> quit ; ……… /* Somewhere downstream in the ETL */ data … ; set Extract ; by <what-we-need> ; … run ;
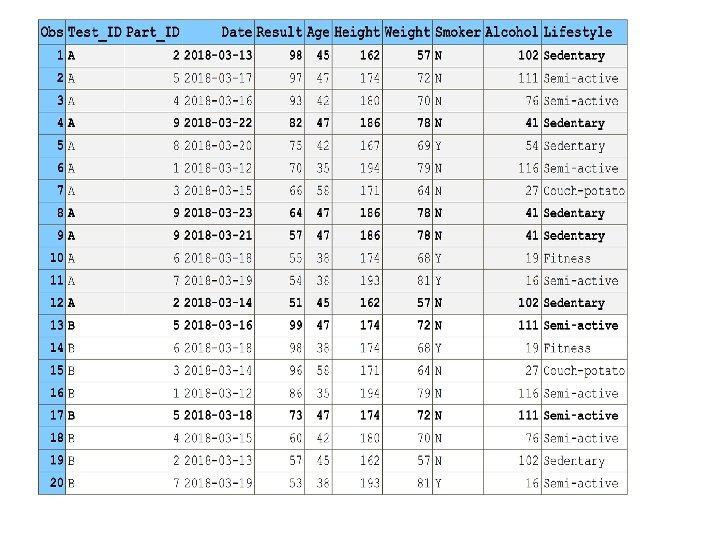
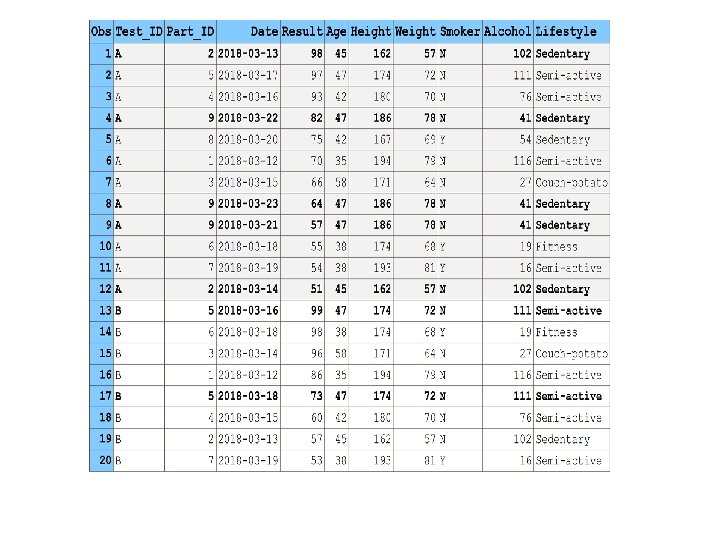
ETL Scenario: File Extract § The extract file is typically very large (more on that later). § It contains duplicate records for variables different from <what-we-need> key. § I. e. : Same key-values for different values of a control variable – such as date, datetime, a DW surrogate key, etc. § The duplicates/non-duplicates percentage is typically small. § We need only a single record from each duplicate-key group: For example, the record with the most recent date. § The duplicates must be eliminated before the downstream ETL step where the extract file is used. § Next slide: A miniscule “model” file TESTS.
Task Statement § Next ETL step task: • For each TEST_ID, extract N participants with the highest RESULT values, for example, N=3. • File is already ordered by (TEST_ID, descending RESULT). • So, we only need to read the file “as is” and get first N rows from each BY- group. § However! We need to unduplicate TESTS first: • Keep only the records with the most recent DATE within each (TEST_ID, PART_ID). • Otherwise, we would end up with wrong top scorers.
Standard “Sledge Hammer” Approach 1. Sort the entire file by (TEST_ID, PART_ID, DATE). Keep the record number in a variable SEQ. 2. From the result, create another, unduplicated, file by keeping only the records with LAST. PART_ID=1. 3. Re-sort the unduplicated file by SEQ to restore the original file order and drop it. 4. Feed the result to the downstream ETL step as required.
Standard Approach: The SAS Language data seq / view=seq ; set Tests ; Seq = _N_ ; run ; proc sort data=seq out=seq_sorted ; by Test_ID Part_ID Date ; run ; data Tests_nodup ; set seq_sorted ; by Test_ID Part_ID ; if last. Part_ID ; run ; proc sort data=Tests_nodup out=Tests_orig_seq (drop=Seq) ; by Seq ; run ;
So, What’s the Problem? § Sorting and re-sorting is resource-intensive. § Extremely taxing with respect to the utility space (such as SORT WORK). § For ~100 M rows and ~ 50 satellite variables it can take hours on end. § An ETL may have many such data feeds that need similar cleansing. § Unduplicating in this manner can bring the ETL to a standstill. § Or, the ETL may fail to fit into the production time window. § Q: Do we REALLY have to sort the WHOLE extract file? § A: Nope.
Duplicate RID-Marking: The Concept 1. 2. 3. 4. 5. 6. Use the extract file to create view ADD_RID with a variable RID (i. e. “Record ID”) to identify the observation numbers in the original extract file. Critical: In view ADD_RID, keep only: The keys, event identifier (e. g. DATE), and RID. Drop all the satellite variables. Sort view ADD_RID into file KEY_RID by (TEST_ID, PART_ID, DATE). Read KEY_RID and use NOT LAST. test_ID condition to save the RID values of the rows to be eliminated in a file DUP_RID. Use the RID values DUP_RID in the MODIFY statement with POINT=RID to mark the rows in the original extract file TESTS for deletion. Now file TESTS can be read by the next ETL step directly: The rows marked for deletion (i. e. the unneeded duplicates) will be automatically skipped.
Duplicate RID-Marking: SAS Code data ADD_RID / view=ADD_RID ; set TESTS (keep=Test_ID Part_ID Date) ; RID = _N_ ; Run ; proc sort data=ADD_RID out=KEY_RID ; by Test_ID Part_ID Date ; run ; data DUP_RID (keep=RID) ; set KEY_RID ; by Test_ID Part_ID ; if NOT last. Part_ID ; run ; data TESTS ; set DUP_RID ; MODIFY TESTS POINT=RID ; REMOVE ; run ;
Real-World Difference SETUP §An ETL with 5 extracts from different DW systems. §A few process-keys and ~50 satellite variables with total length ~500 bytes. §Number of records in the extracts varied from 50 to 80 million. §The duplicates comprised ~10 percent of the total number of records. STANDARD UNDUPLICAITON APPROACH § 1. 5 -2 hours of run time to unduplicate each data stream. § 8 -10 extra hours of ETL run time. MODIFY DUPLICATE-MARKING APPROACH §The unduplication run time reduced to 3 -5 minutes apiece. §No more problems with either SORTWORK or WORK. §The ETL process fit into the production window - with hours to spare.