Compiler Construction Lexical Analysis The word lexical means







: NFA is a tuple:")




- Slides: 13
Compiler Construction Lexical Analysis
• The word lexical means textual or verbal or literal. • The lexical analysis implemented in the “SCANNER” module decomposes the source program, read in from a file as a string of characters, into a sequence of lexical units, called “SYMBOL”. • The scanner reads this character string from left to right. • If the work of the scanner, the screener and the parser is interleaved the parser calls the scanner-screener combination to obtain the next symbol. • The scanner begins the analysis with the character following the end of the last symbol found and searches for the longest string at the beginning of the remaining input that is a symbol of the language. • It returns a representation of this symbol to the screener, which determines whether this symbol is relevant for the parser or should be ignored. • If it is not relevant, the screener triggers the scanner again. • Otherwise, it returns a (possibly altered) representation of the symbol to the parser.
• In general, the scanner should be able to recognize infinitely many or at least, very many different symbols. • It deliberately divides this set into a finite number of classes. • Symbols with a related structure (for example, the same syntactic role) fall into the same “SYMBOL CLASS”. • Thus, we now distinguish between: • Symbols or words over an alphabet of characters, , for example, xyz 12, 125, “abc”. • Symbols Classes or set of symbols such as the set of identifiers, the set of integer constants and that of character strings identified by the names id, intconst, string, and • Representations of Symbols. For example, the scanner might pass the word xyz 12 to the screener in the representation (id, xyz 12), which the latter enters in its symbol table as (1, 17) and passes to the parser, where the code for the symbol class id is 1 and xyz 12 is the 17 th identifier found. • Theoretical Foundations: • Words and languages. We briefly review a number of important basic terms relating to formal languages, where denotes an arbitrary alphabet, that is, a finite non-empty set of characters:
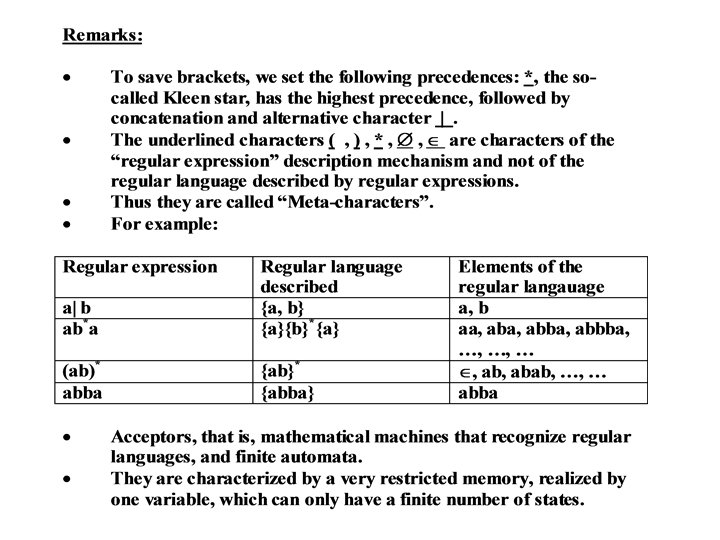
• Regular Languages, Regular Expressions and Finite Automata: • The lexical units recognized by the a scanner from a non-empty regular language. • Regular languages can be described by regular expressions. • Thus, these form the basis for all languages for specifying the lexical analysis. • Regular languages can be recognized by finite automata. • These terms will now be introduces. • Note that, we shall always assume an underlying alphabet . • Regular Language: The regular language are defined over by: • , { } are regular languages over • For all a , { a } is a regular language. • If R 1 and R 2 are regular languages over then so are R 1 U R 2, R 1 R 2 and R 1*.
• Regular Language: RE over and the regular languages they describe can also be defined inductively: • is a regular expression over and describes the regular language { } • a (for a ) is a regular expression over and describes the regular language {a} • If r 1 and r 2 are regular expressions, which describe the regular language R 1 and R 2 then • (r 1 | r 2) is a regular expression over and describes the regular language R 1 U R 2 and • (r 1 r 2) is a regular expression over and describes the regular language R 1 R 2, and • (r 1)* is a regular expression over describes the regular language R 1* • There are no other regular expressions.
• • • • • Non-Deterministic Finite Automata (NFA): NFA is a tuple: M = ( , Q, , q 0, F) Where: is an alphabet, the input alphabet, Q is a finite set of states, Q 0 Q is the initial state. F Q is the set of final states Q x ( U { }) x Q is transition relation. We now explain how an NFA used as a scanner work. An NFA checks whether or not input words are in a given language. It accepts a word if it lands in a final state after reading the whole word. A finite automaton used as a scanner decomposes an input word piece by piece into sub-words of the given language. Thus, each sub-word takes it from its initial state into a final state. It may have problems determining the end of the sub-word. The finite automaton is started in its initial state. Its read head is then at the beginning of the input tape. When a finite automaton is used as a scanner it begins with the first character that has not yet been “consumed”. Then it takes a sequence of steps. Each step depends on the actual state and possibly on the next input character.
• • • • This involves entering a new state and, when the input character has been read, moving the read head to the next character. The automaton accepts the input word when the input is exhausted and the actual state is a final state. The Scanner reports that it has found a symbol when it is in a final state and has no transition to the next input character. If it has no transition from the actual state, and the actual state is not a final state, it must backtrack to the last final state it passes through. If there is no such state for the actual symbol the an error has occurred. The future behavior of an NFA is determined by the actual state and the remainder of the input. These two together form the actual configuration of the automaton. A language for specifying the lexical analysis: The regular expressions provide the main description formalism for the lexical analysis. A specification of the lexical analysis should enable us to combine sets of characters into classes, if they can be exchanged in symbols without the resulting symbols being assigned to different symbol classes. For example: le = a-z, A-Z di = 0 -9 or = |
• open = / | { • close = / | } • star = * • • • We can now give the usual definition of the symbol class of identifiers: id = le ( le | di )* In the character class definitions, we manage with only three metacharacters, namely ‘=’, ‘-‘ and the space character ‘ ‘. The Screener: According to the distribution of tasks, the screener knows the set of reserved names or keywords. This presupposes that the scanner has one or more symbol classes containing these symbols. This is the case when, as for example in Pascal, C and Ada, the keywords have the same structure as identifiers. In the task as described above, for every identifier, whether reserved or not, the scanner will report the presence of an identifier. The screener will then determine whether it is a reserved symbol. This distribution of tasks keeps the set of states and the number of transitions of the scanner automaton small. However, the screener must have an efficient means of recognizing keywords.
• Symbol Classes: • Symbol classes are sets of symbols that are equivalent for the “consumer” in the compiler, that is, the parser. • Two symbols are equivalent if in every state the parser makes the same transition (takes the same decision) under each of the symbols. • Typical symbol classes include the various classes of constants, the identifiers (without the reserved symbols), comments, arithmetic operators of the same precedence and relational operators. • The designer of a scanner-screener combination will define such classes. • A well-defined class code will be assigned to each class either explicitly by the designer or implicitly by the generator. • This class code is passes to the parser when a symbol of the class is found by the generated scanner. • For example: • Character classes: • le = a-z • di = 0 -9
• • • • Symbol classes: Add. OP = +|Mul. Op = *|/|% Comp. OP = < | > | = | <= | >= | != (enumerated classes) Id = le(le | di)* Int. Const = di di* (defined by regular expression with iteration “infinite class”) For semantic analysis and for code generation, it is absolutely necessary to know which element of a symbol class has been found. Thus, in addition to the class code, the scanner/screener also passes on a relative code for the symbol found, which is generally not used by the parser, but noted for later use. If there exist different, but syntactically and semantically equivalent symbols, these may be combined within a symbols class definition. For example: Comp. Op = (<, lt) | (>, gt) | (=, eq) | (!=, neq) | (>=, ge) | (<=, le)