Analysis on Batch Normalization Maxim Afteniy Table of

Analysis on Batch Normalization Maxim Afteniy
 How does Batch Normalization Help")
Table of contents Quick recap on Batch Normalization (BN) How does Batch Normalization Help Optimization? (first paper) - Introduction, motivation Internal covariate shift Smoothing effect of Batch. Norm Analysis and results A Quantitative Analysis of the Effect of Batch Normalization on GD (second paper) - Introduction, motivation OLS problem, background Mathematical Analysis of BNGD on OLS Experiments and results Conclusion on the papers
 Batch. Norm Technique was introduced in 2015, and it’s")
Recap on Batch Normalization (BN) Batch. Norm Technique was introduced in 2015, and it’s indeed one of the top approaches to improve performance. However BN field lacks analysis on “how and why” it improves the performance.

How it currently works in practice Empirical mean and variance is calculated over minibatch, adds a 2 learnable parameters that can be tuned with the gradient descent. This technique according to original BN paper is reducing “Internal Covariate Shift” (ICS). Ths approach controls the distribution of each learnable parameter, by scaling and shifting the distribution of the minibatch.

How does Batch Normalization Help Optimization?

Introduction, motivation Poor understanding of the ICS and how it helps training Questioning if the ICS is responsible at all for the success of the BN

Internal covariate shift Authors question that the is the real reason that BN works
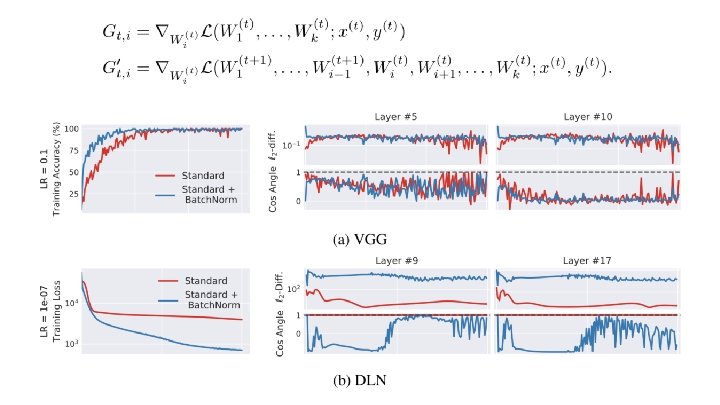

Smoothing effect of Batch. Norm Proposed that the BN makes the landscape of the loss function smoother with the help of the reparametrization, authors state that the BN introduces K-lipschitz continuous surface to the Loss. why K-Lipschitz continuity improves the training? Smoother surface of the loss guarantees that there’s no accident flat regions, sharp minimas that significantly reduce the stability of the gradient descent. Next slide presents statistics that indeed show that surface is much smoother with the use of BN.
 Variability of the loss over the time steps b) l 2 changes in")
a) Variability of the loss over the time steps b) l 2 changes in the gradient c) β-smoothness is referred as the maximum gradient change over the distance. Gradient of the loss is β-Lipschitz

Theoretical analysis Similair empirical results on random gradient directions, also the paper provides theoretical analysis to prove that indeed BNGD enforces K-Lipschitzness to the loss surface: Also they show that BNGD provides better weight initialization for the network.

A Quantitative Analysis of the Effect of Batch Normalization on GD

Introduction, motivation 1. Unclear what reducing the internal covariance shift means in precise mathematical terms 2. What BN contributes to the stability and the convergence of GD? - Overparametrization Introduction of the scale property in BN BNGD convergence is insensitive to learning rates

Ordinary least squares problem, background Simple enough solution and we can find optimal solution with simple derivations given: where unique minimizer

Optimal values for the learning rate, and optimal convergence rate can be derived with: Optimal values can be computed: where Similarly we could perhaps apply same technique to derive optimal value(s) for BNGD?

BNGD setup of the OLS problem Reparametrization of the OLS introduced with BNGD: Similar objective can be formulated (they prove that the scale is 0):

Mathematical Analysis of BNGD on OLS Similar analysis can be done for the BN convergence, through many derivations as long as following equation holds: given spectral radius The convergence of the BNGD is linear, assuming there is no dynamic learning rate change in the BN iterations.

Experiments and results Introduction of the scaling property of BNGD (replacing learning rate for weights versus scale parameter brought by GD is same as changing the norm of the initial weights). Paper concludes that the reparametrization of the batch introduces the insensitivity to the learning rate changes, comparing it to standard GD approach ε ∈ (0, 1]

η = the scale factor for the initialized weights, since they achieve near same learning curves, we can follow up from the scale property that the convergence is not that much dependent on the learning rate.
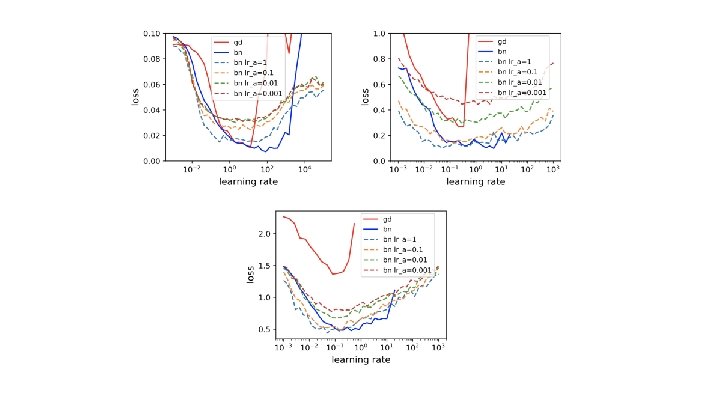

Conclusions Papers have different perspective on the “understanding” of the BN. What do you think what brings the success of the BN? In my opinion it allows gradient signals to be arbitrary (giving more freedom which results more flexibility and thus learning rate or weight magnitudes are not that significant anymore) in the neural network architecture, by scaling and shifting the single parameter.
- Slides: 21