1 Storage and Querying of ECommerce Data VLDB


主要参考文献 1 Storage and Querying of E-Commerce Data VLDB 2001 2 Extending RDBMSs To Support Sparse Datasets Using An Interpreted Attribute Storage Format VLDB 2006 3 The Case for a Wide-Table Approach to Manage Sparse Relational Data Sets SIGMOD 2007 4 A Comparison of Flexible Schemas for Software as a Service SIGMOD 2009 5 The Design of the Force. com Multitenant Internet Application Development Platform SIGMOD 2009 2



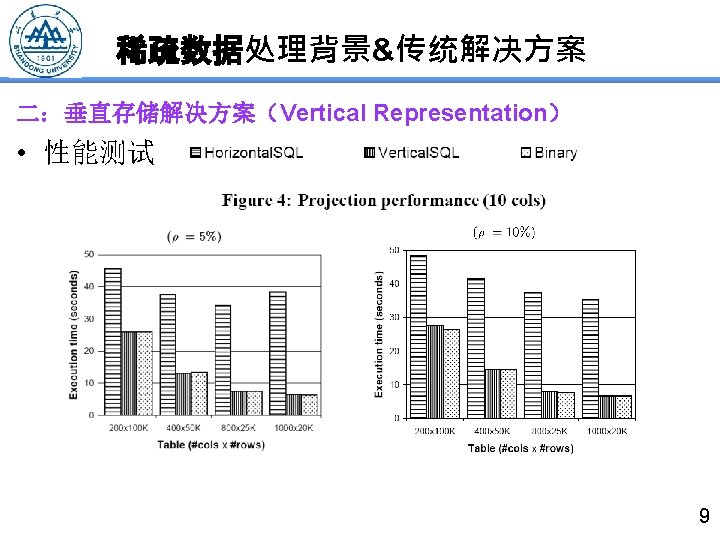
稀疏数据处理背景&传统解决方案 一:电子商务数据特点 • In trying to store all our electronic parts in one table using this scheme, we ran into the following problems: – Large Number of Columns The current database systems do not permit a large numbers of columns in a table. This limit is 1012 columns in DB 2 (also in Oracle), whereas we had nearly 5000 attributes across different categories. – Sparsity Even if DB 2 were to allow the desired number of columns, we would have had nulls in most of the fields. In addition to creating storage overhead 1, nulls increase the size of the index and they sort high in the DB 2 B+ tree index. – Schema Evolution We would need frequent altering of the table to accommodate new parts and categories. The schema evolution is expensive in the current database systems. – Performance A query incurs a large performance penalty if the data records are very wide but only a few columns are used in the query. 5
 However, once the data is stored in the vertical format, new")
稀疏数据处理背景&传统解决方案 二:垂直存储解决方案(Vertical Representation) However, once the data is stored in the vertical format, new problems arise. Writing SQL queries against this scheme becomes very cumbersome and error-prone. More importantly, the current application development tools designed for horizontal format for storing objects no longer work. We create a logical horizontal view of the vertical representation and transform queries on this view to the vertical table. 6
 table V has the scheme (Oid; Key; Val) H has the")
稀疏数据处理背景&传统解决方案 二:垂直存储解决方案(Vertical Representation) table V has the scheme (Oid; Key; Val) H has the scheme(Oid; A 1; : : : ; An) with the column Oid being non-ullable. • v 2 h Operation creates a horizontal table of arity k+1 whose first column is Oid and the first k key values form the rest of the k columns. • h 2 v Operation creates a vertical table with the scheme (Oid; Key; Val) 7
 • Rewrite – Projection – Selection – Jion 8")
稀疏数据处理背景&传统解决方案 二:垂直存储解决方案(Vertical Representation) • Rewrite – Projection – Selection – Jion 8
 • If one uses the normal “horizontal” schema to store")
稀疏数据处理背景&传统解决方案 三:解释属性存储(Interpreted Attribute Storage) • If one uses the normal “horizontal” schema to store such data sets in any of the three leading commercial RDBMS, the result is tables that occupy vast amounts of storage, most of which is devoted to nulls. • If one attempts to avoid this storage blowup by using a “vertical” schema, the storage utilization is indeed better, but query performance is orders of magnitude slower for certain classes of queries • VLDB 06 argue that the proper way to handle sparse data is not to use a vertical schema, but rather to extend the RDBMS tuple storage format to allow the representation of sparse attributes as interpreted fields. 10

 • • • In practice, if some attributes are dense")
稀疏数据处理背景&传统解决方案 三:解释属性存储(Interpreted Attribute Storage) • • • In practice, if some attributes are dense and others sparse, a system would use a record format in which the dense attributes are stored positionally toward the beginning of the record and are followed by an interpreted section that contains any sparse attributes that are defined for the tuple. 解释属性存储可以认为是水平存储的一种备选,或者垂直存储的优化 与vertical区别(both store the same repeating “attr, value” pairs) – (a) in interpreted, all the pairs are viewed as a single object so there is no need to tie them together with a common tuple id or reconstruct the tuple during query evaluation; – (b)in interpreted, the attributes are collected together as one object, and in contrast, the vertical entity is a set of independent tuples that can be organized (or clustered) in any order; – (c) in interpreted, the system catalog records the attribute names, whereas in the vertical format these names must be managed externally by the application. 12
 • 如何取数据? • 与普通存储相比更复杂 While the interpreted format clearly has")
稀疏数据处理背景&传统解决方案 三:解释属性存储(Interpreted Attribute Storage) • 如何取数据? • 与普通存储相比更复杂 While the interpreted format clearly has storage benefits for sparse data, retrieving the values from attributes in tuples is more complex. • 为什么称为“解释” In fact, the format is called interpreted because the storage system must discover the attributes and values of a tuple at tuple-access time, rather than using precompiled position information from a catalog, as the positional format allows. • 引入额外操作(EXTRACT) For this purpose we introduce a new operator, called EXTRACT. In a query plan the EXTRACT operator precedes any reference to attributes stored in the interpreted format. It returns the offsets to the referenced interpreted attribute values, and these resulting offsets are then used to retrieve the values. 13



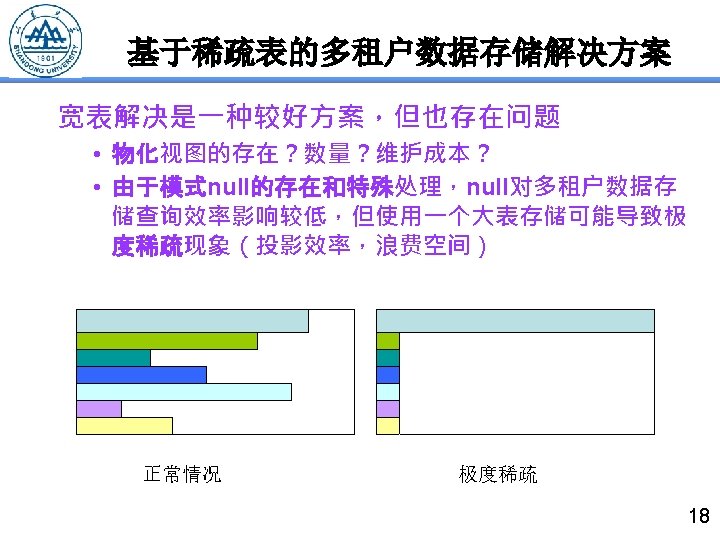
基于稀疏表的多租户数据存储解决方案 • 以Force. com为代表 • 500列宽表,varchar类型 Force. com stores the application data for all virtual tables in a few large database tables that serve as heap storage. The platform’s engine then materializes virtual table data at Runtime by considering corresponding metadata. • 元数据驱动 • Pivot tables做索引 Force. com manages an index of the Data table by synchronously copying field data marked for indexing to an appropriate column in a pivot table called Indexes. 17


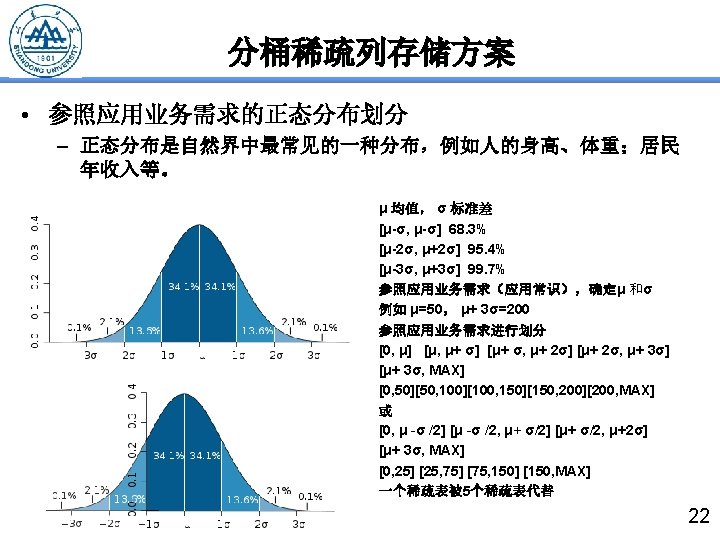
- Slides: 22