Yahoo BOSS Open up Yahoos Search data via

Yahoo! BOSS • Open up Yahoo!’s Search data via web services • Developer & Custom Tracks • Big Goal – If you’re in a vertical and you perform a search, you should be confident that the results you get back will be just as good as those on Google or Yahoo!, but only better because that vertical has additional relevant information

Yahoo! BOSS Developer • Unrestricted RESTful APIs – Presentation/Ranking control & Query limits Off – Web, News, Spelling, Images, Site Explorer • Disclosing once internal-only data – Delicious bookmarks metadata – Searchmonkey (microformats e. g. Linked. In profiles) – Extracted Entities (with scores, term variants) – Larger Abstracts

100’s of Developer Apps

Model • It’s not a Search API, it’s really a Data API • Search happens to be an easy way to retrieve data from billions of varying documents • Slowly moving beyond keyword match – searchmonkeyid, site restricts, doc type, inurl, intitle, lang, region, date, flickr • Defer re-ordering, blending to user – Scale: Tens of millions BOSS QPD – Difficult to universalize ranking models
 Search fresh data not on")
Yahoo! BOSS Custom • Most Common Requests – (1) Search fresh data not on web, (2) Do thousands of site restricts • Solution: Hosted Vertical Search in Yahoo!’s Cloud – Near real-time indexing of millions of documents – Data may be structured with fields, indexable properties • Schemas, Schema-less, Filters, Range Queries • • Access to more search ranking features API primitives for federating custom & developer search results – Very basic priority stacking – Backfill developer results to capture comprehensiveness for tail vertical queries • Create your own “view” of web, vertical search – More ranking control server-side – Logically, physically isolated from core web search engine
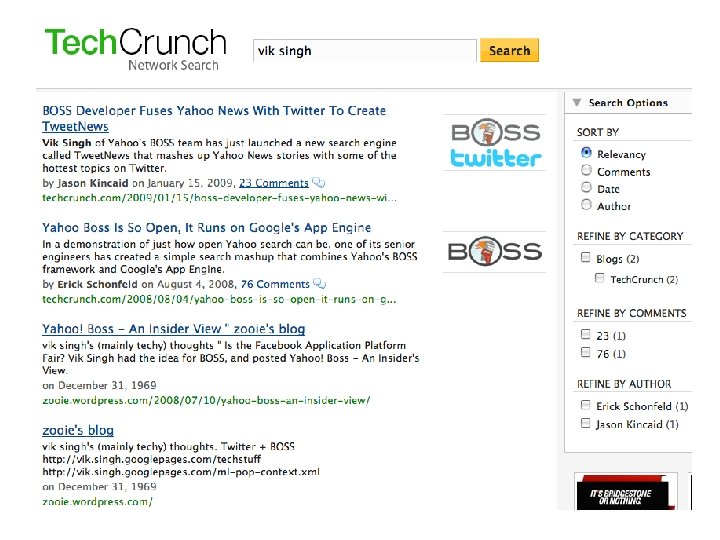

Blending Vertical + Web • Key to comprehensiveness • Right now Tech. Crunch search does basic backfilling • Can we do better? • Learning transfer functions – Normalizing two sets of results on same scale • Ex. delicious + web – X: <web result features> | Y: delicious count – Machine learn the delicious counts => f – Now do a web search, sort by f(web result); works well

Questions • Ranking/Blending interfaces. Learning models. • Which features to reveal? Spam concerns. • Would Search APIs benefit from a standardized structured language? • How much of research needs APIs versus raw web crawl dumps for specialized one-off analysis? • Should ranking be done API server-side or client-side?
- Slides: 8