Xpath Query Evaluation Goal Evaluating an Xpath query




 { S: -= Apply Q. first to n; If |Q|>")






![Xpath query parse tree descendant: : b/following-sibling: : * [position() != last()]](https://slidetodoc.com/presentation_image_h2/99758580caf35d2ca8bd8c42251da33f/image-12.jpg "Xpath query parse tree descendant: : b/following-sibling: : * [position() != last()]")





: all nodes satisfying a predicate t • E(e): all nodes")



 space ignoring strings and numbers – O(|Q|) tables, with 3 columns,")






 algorithm for type inference can work its way to")


 =>")
- Slides: 33
Xpath Query Evaluation
Goal • Evaluating an Xpath query against a given document – To find all matches • We will also consider the use of types • Complexity is important – Huge Documents
Data complexity vs. Combined Complexity • Two inputs to the query evaluation problem – Data (XML document) of size |D| – Query (Xpath expression) of size |Q| – Usually |Q| << |D| • Polynomial data complexity – Complexity that is polynomial in |D|, possibly exponential in |Q| • Polynomial combined complexity – Complexity that is polynomial in |D| and |Q| • Fixed Parameter Tractable complexity – Complexity Poly(|D|)*f(|Q|)
Xpath Query Evaluation • Input: XML Document D, Xpath query Q • Output: A subset of the nodes of D, as defined by Q • We will follow Efficient Algorithms for Processing Xpath Queries / Gottlob, Koch, Pichler, TODS 2005
Simple algorithm process-location-step(n, Q) { S: -= Apply Q. first to n; If |Q|> 1 For each node n’ in s do process-location-step(n’, Q. next) }
Complexity • Worst case: in each step of Q the axis is “following” • So we apply the query in each step on O(|D|) nodes • And we get Time(|Q|)= |D|*Time(|Q|-1) • I. e. the complexity is O(|D|^|Q|)
Early Systems Performance Figure taken from Gottlob, Koch, Pichler ‘ 05
Internet Explorer 6 Figure taken from Gottlob, Koch, Pichler ‘ 05
IE 6 – performance as a function of document size Figure taken from Gottlob, Koch, Pichler ‘ 05
Polynomial data complexity • Poly data complexity is sometimes considered good even if exponential in the query size • But can we have polynomial combined complexity for Xpath query evaluation? • Yes!
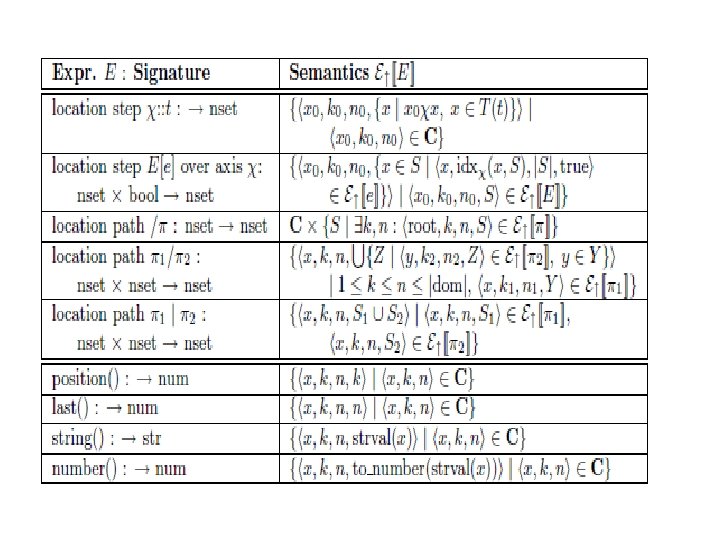
Two main principles • Query parse trees: the query is divided to parts according to its structure (not to be confused with the XML tree structure) • Context-value tables: for every expression e occurring in the parse tree, compute a table of all valid combinations of context c and value v such that e evaluates to v in c.
Xpath query parse tree descendant: : b/following-sibling: : * [position() != last()]
Bottom-up vs. Top-down evaluation • We will discuss two kinds of query evaluation algorithms: – Bottom-up means that the query parse tree is processed from the leaves up to the root – Top-down means that the parse tree is processed from the root to the leaves • When processing we will fill in the contextvalue table
Bottom-up evaluation • Main idea: compute the value for each leaf for every possible context • Propagate upwards until the root • Dynamic programming algorithm to avoid reevaluation of queries in the same context
Operational semantics • Needed as a first step for evaluation algorithms • Similar ideas used in compilers design • Here the semantics is based on the notion of contexts
Contexts • The domain of contexts is C= dom X {<k, n> | 1<k<n< |dom|} A context is c=<x, k, n> where x is a context node k is a context position n is the context size
Semantics for Xpath expressions • The semantics of evaluating an expression is a 4 -tuple where the first 3 elements are the context, and the fourth is the value obtained by evaluation in the context
Some notations • T(t): all nodes satisfying a predicate t • E(e): all nodes satisfying a regular exp. e (applied with respect to a given axis) • Idxx(x, S) is the index of a node x in the set s with respect to a given axis and the document order
Context-value Table • Given a query sub-expression e, the contextvalue table of e specifies all combinations of context c and value v, such that computing e on the context c results in v • Bottom-up algorithm follows: compute the context-value table in a bottom-up fashion with respect to the query
Bottom-up algorithm
Example 4 times
Complexity • O(|D|^3*|Q|) space ignoring strings and numbers – O(|Q|) tables, with 3 columns, each including values in 1…|D| thus O(|D|^3*|Q|) – An extra O(|D|*|Q|) multiplicative factor for strings and numbers • O(|D|^5*|Q|) time ignoring strings and numbers – It can take O(|D|^2) to combine two nodesets – Extra O(|Q|) in case of strings and numbers
Optimization • Represent contexts as pairs of current and previous node • Allows to get the time complexity down to O(|D|^4* |Q|^2) • Space complexity can be brought down to O(|D|^2*|Q|^2) via more optimizations
Top-down evaluation • Similar idea • But allows to compute only values for contexts that are needed • Same worst-case bounds
Top-down or bottom-up? • General question in processing XML trees • The tradeoff: – Usually easier to combine results computed in children to obtain the result at the parent • So bottom-up traversal is usually easier to design – On the other hand, some of the computation is redundant since we don’t know if it will become relevant • So top-down traversal may be more efficient
Linear-time fragment • Core Xpath includes only navigation – and \ • Core Xpath can be evaluated in O(|D|*|Q|) • Observtion: no need to consider the entire triple, only current context node • Top-down or bottom-up evaluation with essentially the same algorithm • But smaller tables (for every query node, all document nodes and values of evaluation) are maintained.
Types are helpful • Can direct the search – In some parts of the tree there is no hope to get a match to a given sub-expression of the query – As a result we may have tables with less entries. • Whiteboard discussion
Type Checking and Inference • Type checking a single document: straightforward – Polynomial combined complexity if automaton representing type is deterministic, exponential in automaton size but polynomial in document size otherwise • Type checking the results of a (Xpath) query • Inferring the results of a query
Type Inference • An (incomplete) algorithm for type inference can work its way to the top of the query parse tree to infer a type in a bottom-up fashion – Start by inferring a type for the leaves (simple queries), then use it for their parents • Type Inference is inherently incomplete. • Can be performed for some languages that are “regular” in a sense.
Restricted language allowing for type inference • Axes: child, descendant, parent, ancestor, following-sibling, etc. • variables can be bound to nodes in the input tree= then passed as parameters • An equality test can be performed between node ID's, but not between node values.
Type Checking • In addition to inferring a type we need to verify containment in another type. • Type Inference can be used as a tool for Type Checking. • Type Checking was shown to be decidable for the same language fragment, but with high complexity.
Intuitive connection to text • Queries => regular expressions • Types (tree automata) => context free languages • Type Inference => intersection of context free and regular languages, resulting in a context free one • Type checking => Type Inference + inclusion of context free languages (with some restrictions to guarantee decidability)