WOCMAT SIGIR 79 IRAL SIGIR JASIST NTCIR SIGIR

 音樂檢索 IRAL SIGIR 自動編目與檢索 第二名(瑞士舉辦) 主題檢索 JASIST NTCIR 中國圖書館學會會")












![相關研究: Sanderson and Croft (SIGIR’ 99) • 概念階層的範例:[from Sanderson and Crofts’ paper]](https://slidetodoc.com/presentation_image_h/341e512d7ea8d85677ccfad63891bd39/image-16.jpg "相關研究: Sanderson and Croft (SIGIR’ 99) • 概念階層的範例:[from Sanderson and Crofts’ paper]")








![關鍵詞自動擷取範例 [Tseng 2000]:英文範例 Web Document Clustering: A Feasibility Demonstration Users of Web search engines](https://slidetodoc.com/presentation_image_h/341e512d7ea8d85677ccfad63891bd39/image-25.jpg "關鍵詞自動擷取範例 [Tseng 2000]:英文範例 Web Document Clustering: A Feasibility Demonstration Users of Web search engines")

 was extracted,")
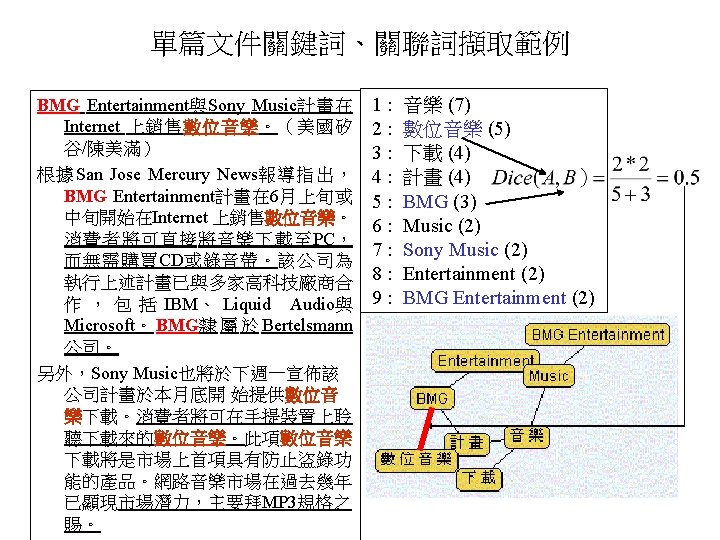



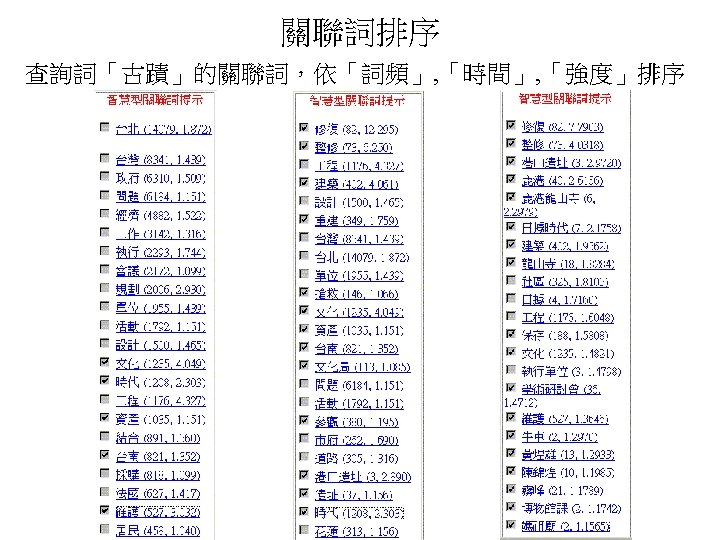

: 4 (即 查詢詞 : 「古蹟」) Total number of documents (terms)")








 of Sun")

- Slides: 52
近年研究主題演進圖 關鍵詞擷取 WOCMAT SIGIR (79) 音樂檢索 IRAL SIGIR 自動編目與檢索 第二名(瑞士舉辦) 主題檢索 JASIST NTCIR 中國圖書館學會會 SIGIR 報(中國時報) SIGIR 關聯詞分析 自動分類 NTCIR 分類不一 致性偵測 NTCIR IEEE ICME 、IACIS 自動摘要 NTCIR AIRS JIS NTCIR 自動歸類 專利、學術文獻 主題趨勢分析 知識探勘 IPM ISSI 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 Sciento metrics STI 2008
相關研究: Sanderson and Croft (SIGIR’ 99) • 概念階層的範例:[from Sanderson and Crofts’ paper]
關鍵詞自動擷取範例 [Tseng 2000]:英文範例 Web Document Clustering: A Feasibility Demonstration Users of Web search engines are often forced to sift through the long ordered list of document returned by the engines. The IR community has explored document clustering as an alternative method of organizing retrieval results, but clustering has yet to be deployed on the major search engines. The paper articulates the unique requirements of Web document clustering and reports on the first evaluation of clustering methods in this domain. A key requirement is that the methods create their clusters based on the short snippets returned by Web search engines. Surprisingly, we find that clusters based on snippets are almost as good as clusters created using the full text of Web documents. To satisfy the stringent requirements of the Web domain, we introduce an incremental, linear time (in the document collection size) algorithm called Suffix Tree Clustering (STC), which creates clusters based on phrases shared between documents. We show that STC is faster than standard clustering methods in this domain, and argue that Web document clustering via STC is both feasible and potentially beneficial. ? Terms extracted before filtering Terms extracted after filtering 1. clusters based on : 3 2. document clustering : 3 3. of Web : 3 4. on the : 3 5. search engines : 3 6. STC is : 2 7. Web document clustering : 2 8. Web search engines : 2 9. clustering methods in this domain : 2 10. requirements of : 2 11. returned by : 2 1. clusters based : 3 2. document clustering : 3 3. Web : 3 4. 5. search engines : 3 6. STC : 2 7. Web document clustering : 2 8. Web search engines : 2 9. clustering methods in this domain : 2 10. requirements : 2 11. returned : 2
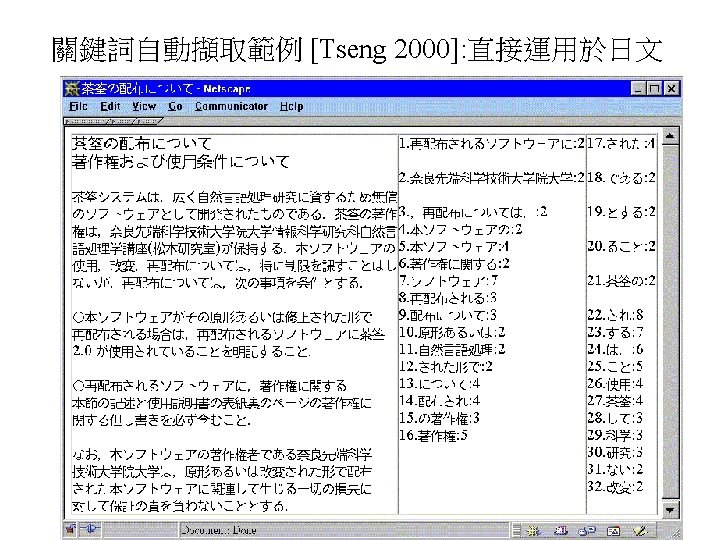
Key-phrase Extraction: Example The term “committee” in various erroneous forms (from OCR) was extracted, showing that the algorithm really can extract lexical terms without knowing their semantics (which is both an advantage and a disadvantage)
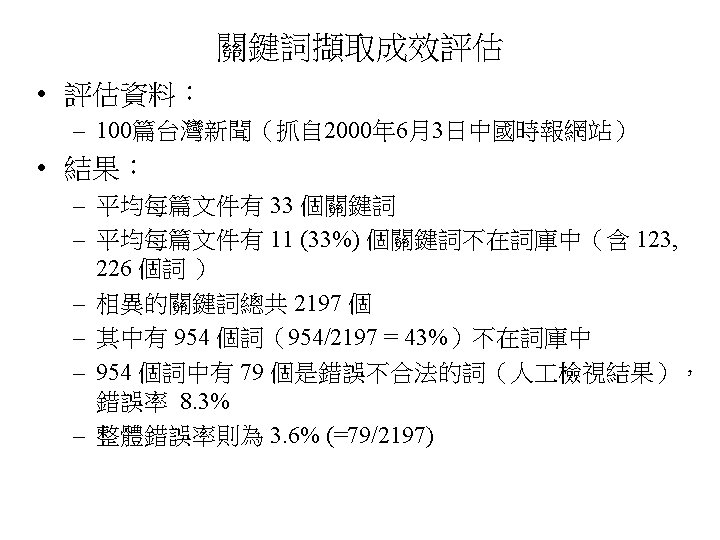
trec_eval 的部分輸出 Queryid (Num): 4 (即 查詢詞 : 「古蹟」) Total number of documents (terms) (for 「古蹟」) Retrieved: 50 Relevant: 43 Rel_ret: 35(即 找到且被判斷為相關者) Interpolated Recall - Precision Averages: at 0. 00 1. 0000 at 0. 10 1. 0000 at 0. 20 1. 0000 at 0. 30 0. 9412 at 0. 40 0. 9130 at 0. 50 0. 8800 at 0. 60 0. 8438 at 0. 70 0. 7949 at 0. 80 0. 7447 at 0. 90 0. 0000 at 1. 00 0. 0000 Average precision (non-interpolated) for all rel. terms 0. 7315 (單一查詢的平均精確率) Precision: At 5 terms: At 10 terms: At 15 terms: At 20 terms: At 30 terms: 1. 0000 0. 9333 0. 9000 0. 8333 R-Precision (precision after R (= num_rel for a query) docs retrieved): Exact: 0. 7442
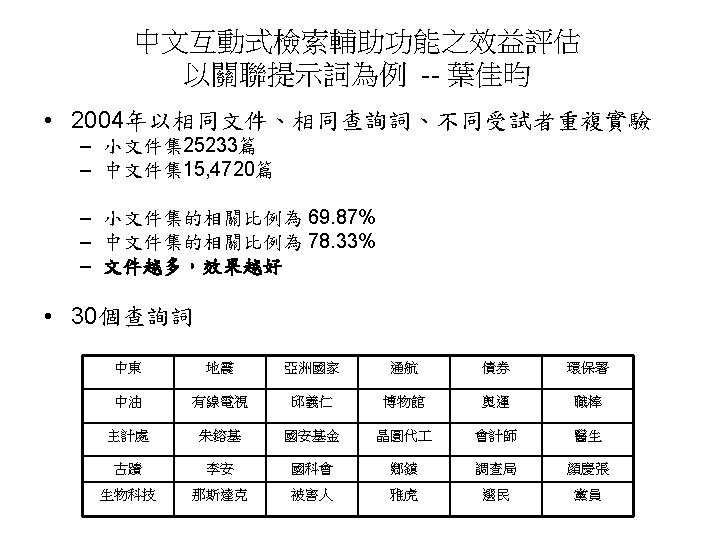
計劃成果 • 相關論文 – Yuen-Hsien Tseng, "Automatic Thesaurus Generation for Chinese Documents", Journal of the American Society for Information Science and Technology, Vol. 53, No. 13, Nov. 2002, pp. 1130 -1138. – Yuen-Hsien Tseng, "Fast Co-occurrence Thesaurus Construction for Chinese News, " Proceedings of the 2001 IEEE Systems, Man, and Cybernetics Conference, Tucson, Arizona, USA, October 7 -10, 2001, pp. 853 -858. • 相關專利 – 曾元顯, 數位文件關鍵特徵之自動擷取方法, 中華民國發明專利第 153789 – 曾元顯, 漸進式關聯詞庫之建構方法, 中華民國發明專利,專利號: I 290684. • 後續論文 – Yuen-Hsien Tseng, Da-Wei Juang and, Shiu-Han Chen "Global and Local Term Expansion for Text Retrieval, " Proceedings of the Fourth NTCIR Workshop on Evaluation of Information Retrieval, Automatic Text Summarization and Question Answering, June 2 -4, 2004, Tokyo, Japan. – 中文互動式檢索輔助功能之效益評估 -以關聯提示詞為例, 2004年 • 後續應用 – 促進國內檢索技術提昇
NTCIR 中文主題檢索成效 • • 012: : 導演,黑澤明 012: : 查詢日本導演黑澤明的生平大事 Run. ID Rigid MAP Relax % imp - MAP 0. 3217 % imp C-C-T+AT 0. 2119 - C-C-T+MT 0. 4094 93. 20 0. 5442 69. 16 C-C-T+BRF 0. 2881 35. 96 0. 3912 21. 60 C-C-T+MT+BRF 0. 4795 126. 29 0. 5962 85. 33 C-C-T+AT(p) 0. 2472 16. 66 0. 3892 20. 98 C-C-T+MT(p) 0. 4174 96. 98 0. 5918 83. 96 C-C-T+BRF(p) 0. 3602 69. 99 0. 5576 73. 33 C-C-T+MT+BRF(p) 0. 6707 216. 52 0. 6779 110. 72 Max of C-C-T 0. 7145 0. 7492 Avg of C-C-T 0. 5083 0. 5954 Min of C-C-T 0. 2119 0. 3217
在教育資料方面的應用 檢索試驗平台 http: //140. 122. 85. 108: 8080/ ksp/search. jsp Ed. Share知識關聯檢索 http: //edshare. edu. tw/erportal/display. jsp? definition_page=relative. Search. Page
Term Association • Goal – To mine topic relations from massive texts • Problem to be solved – Massive terms in digital collections – Possible term-pairs are even more • Achievement: – 380, 000 docs. (470 MB texts) in 50 minutes on desktop PC – 78% related terms are judged relevant
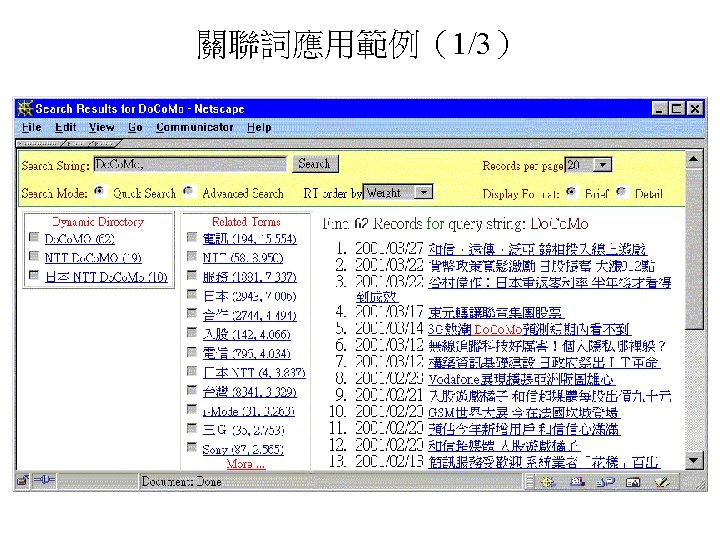
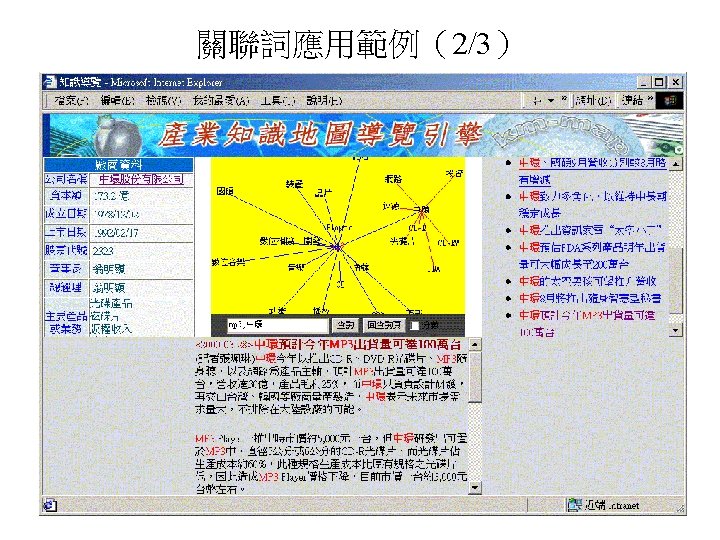
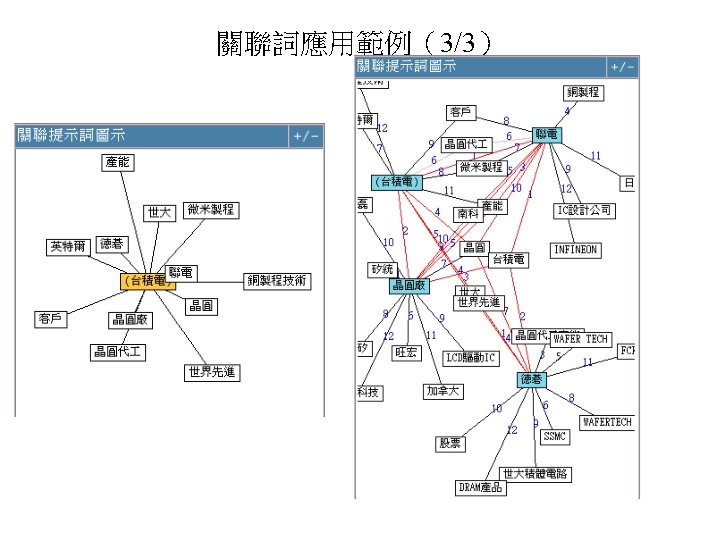
Examples: Term Suggestion
Applications • Reduce vocabulary mismatch – which causes major search failures • Reduce load on searchers – Information is found only when it is seen, sometimes • Increase retrieval effectiveness [NTCIR 4 and 5] • Increase understanding of the collections – A visual way to summarize the search results • Provide expert-level knowledge for novices – Example • Co-word analysis for clustering, and more app. – Example: Sun and HP
Co-word Analysis based on CRTs • Compaq、伺服器、方案 are common related terms (CRTs) of Sun and HP. Hence Sun and HP are clustered in a closer way (in the context that they are both computer companies).
Examples for Co-word Analysis Near-synonym term extraction: 2347: 0. 320898 (玩 具: 0. 8156, 大 人: 0. 7547, 幼 稚 園: 0. 4816, 腸 病 毒: 0. 4038) • 94: 0. 565582 (小 孩 子: 0. 6314, 玩 具: 0. 5761, 嬰 兒: 0. 5331, 大 人: 0. 5331) • 185 : 孩子 (sonny) • 325 : 小孩 (kid) • 705: 0. 419554 (玩 具: 0. 5761, 暑 假: 0. 5761, 大 人: 0. 5331, 卡 通: 0. 5331) • 363 : 兒童 (child) • 546 : 小朋友 (little friend) Useful association (previously unknown) for novice: 13028: 0. 193109 (安 非 他 命: 0. 5935, 計 程 車: 0. 5388, 轎 車: 0. 4959, 子 彈: 0. 4708) • 2733: 0. 307512 (安 非 他 命: 0. 6649, 子 彈: 0. 5276, 計 程 車: 0. 4816, 毒 品: 0. 4711) • 654: 0. 425316 (子 彈: 0. 6107, 安 非 他 命: 0. 5755, 警 力: 0. 4778, 警 員: 0. 4299) • 21: 0. 662110 (刑 事: 0. 4984, 子 彈: 0. 4984, 安 非 他 命: 0. 4696, 警 局: 0. 4453) • 686 : 員警 (policeman) • 822 : 派出所 (police office) • 74 : 警方 (police) • 297 : 少年 (juvenile) • 684 : 清晨 (early morning)