WLCG Worldwide LHC Computing Grid WLCG Service Status








 Rank Definition Max. Downtime Comments 11 CMS Stops Operating")
 Tier Service Criticality Consequences of service interuption 0 Oracle")
 Service Criticality CERN VO boxes 10=critical=0. 5")
 l l l FTS")








")
- Slides: 22
WLCG – Worldwide LHC Computing Grid WLCG Service Status LCG Comprehensive Review, November 20 th 2007 Jamie Shiers WLCG Service Coordination
Agenda • State of Readiness of WLCG Service – In particular, progress since LHCC Open Session in September (not a repeat…) – And in the context of CCRC’ 08 / data-taking preparation • Status of Services in terms of Reliability – Benchmarks: WLCG Mo. U targets & Experiment lists of “Critical Services” and their criticality • Outlook & Conclusions
WLCG Commissioning Schedule September 2006 Note emphasis: n n n LHCC Comprehensive Review – September 2006 Residual Services, Increased reliability, Performance, Capacity, Monitoring, Operation 3
LCG Component Service Readiness - Update Service Comments SL 4 BDII, CE, WN, UI delivered. Other components being ported… LFC Stable & in production. Additional bulk methods (ATLAS) delivered and being tested. Issues with R/O LFC development (done & certified); deployment at phase I Tier 1 s < February CCRC’ 08; all < May CCRC’ 08 FTS Service runs at CERN and (most) T 1 s. (Clients also at T 2 s). Still some issues related to CMs to be worked out. (“Clouds”) VOMS Server and management interfaces work. Still issues over how proxies, roles, groups, attributes will be used – being analysed WLM Well performing g. Lite WMS, including g. Lite 3. 1 for SL 4 (32 bit mode); 3 D Tier 0 and Tier 1 database infrastructure in place and streams replication used by ATLAS, CMS (T 0 online-offline) and LHCb; 3 D monitoring integrated with experiment dashboards SRM v 2. 2 Extensive testing since ~1 year. Production deployment in progress. (CERN + major T 1 s < end 2007; rest < end Feb 2008. ) Experiment adaption planned & in progress. CHEP 2007
SRM v 2. 2 Production Deployment • SRM v 2. 2 production deployment at CERN now underway. – – • One ‘endpoint’ per LHC experiment, plus a public one (as for CASTOR 2). LHCb endpoint already configured & ready for production; Others well advanced – available shortly Tier 1 sites running CASTOR 2 at least one month after CERN (experience) SRM v 2. 2 is being deployed at Tier 1 sites running d. Cache according to agreed plan: steady progress – Remaining sites – including those that source d. Cache through OSG – by end-Feb 2008. • DPM is already available for Tier 2 s (and deployed); STORM also for INFN(+) sites • CCRC’ 08 (described later) is foreseen to run on SRM v 2. 2 (Feb + May) Common Computing Readiness Challenge • Adaption of experiment frameworks & use of SRM v 2. 2 features planned – Need to agree concrete details of site setup for January testing prior to February’s CCRC’ 08 run Ø Details of transition period and site configuration still require work
Explicit Requirements – CCRC’ 08 Service Experiments Comments SRM v 2. 2 ATLAS, CMS, LHCb Roll-out schedule defined and now in progress. Expect to be at ~all Tier 1 s < end 2007, ~1/2 Tier 2 s by end January 2008, ~all Tier 2 s by end March 2008. xrootd i/f ALICE Draft document on support for this being discussed. R/O LFC LHCb Developments for R/O replicas done - patch through certification but new code path needs to be validated in R/O mode, e. g. at CNAF, then other Tier 1 s. Generic agents (aka “pilot jobs”) LHCb See discussions at MB & GDB – glexec security audited; experiments’ pilot job frameworks to follow Commissioned links CMS According to CMS definition & measurement (DDT programme – underway, reports regularly) Conditions DB ATLAS, LHCb In production. To be tested at CCRC’ 08 scale… Target: services deployed in production 2 months prior to start of challenge Neither all services nor all resources will be available in February – “integration challenge” – helping us understand problem areas prior to May’s “full challenge”.
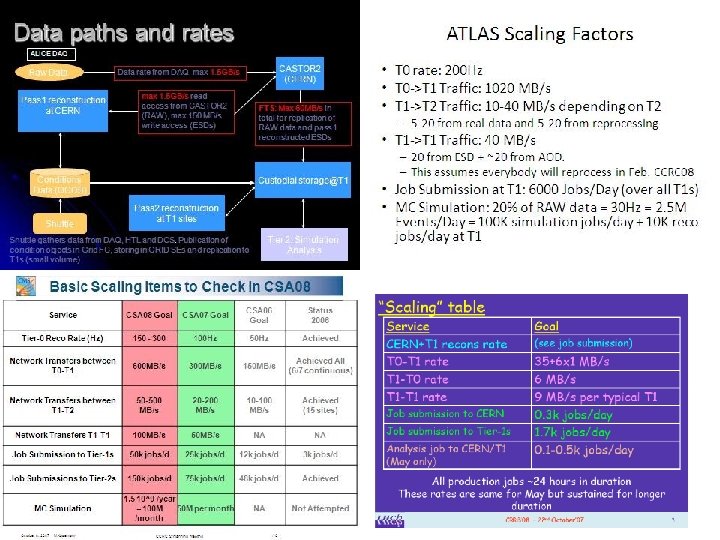
CCRC’ 08 – Proposed Schedule Recent CSA 07 experience ‘suggests’ doing these things concurrently is indeed Phase 1 - February 2008: harder than separately, e. g. load on storage due to transfers + production – Possible scenario: blocks of functional tests, • Try to reach 2008 scale for tests at… 1. CERN: data recording, processing, CAF, data export 2. Tier-1’s: data handling (import, mass-storage, export), processing, analysis 3. Tier-2’s: Data Analysis, Monte Carlo, data import and export Ø Experiments have been asked to present these ‘blocks’ in detail at December CCRC’ 08 planning meeting, including services (WLCG, experiment) involved as well as corresponding ‘scaling factors’ Ø Resource availability at sites expected to limit scope / scale of challenge (e. g. not all sites will have full 2008 resources in production by then – no / reduced re-processing pass at these – e. g. read each event in the file including a conditions DB lookup? ) • Phase 2: Duration of challenge: 1 week setup, 4 weeks challenge Ideas: • Use January (pre-)GDB to review metric, tools to drive tests and monitoring tools – Ø Ø This means that we must preview the metric etc already in December meeting – more later! Use March GDB to analysis CCRC phase 1 Launch the challenge at the WLCG workshop (April 21 -25, 2008) Schedule a mini-workshop after the challenge to summarize and extract lessons learned (June 12/13 in IT amphitheatre or Council Chamber) Document performance and lessons learned within 4 weeks. October 9, 2007 M. Kasemann CCRC f 2 f planning meeting 12/10
LCG WLCG Service Concerns for 2008 Scalability: § 5 -6 X needed for resource capacity, number of jobs § 2 -3 X needed for data transfer Live for now with the functionality we have Need to understand better how analysis will be done Reliability: § Not yet good enough § Data Transfer is still the most worrying - despite many years of planning and testing § Many errors complicated recovery procedures § Many sources of error – storage systems, site operations, experiment data management systems, databases, grid middleware and services, networks, . . Hard to get to the roots of the problems CHEP 2007
LCG CMS Critical Services (wiki) Rank Definition Max. Downtime Comments 11 CMS Stops Operating 0. 5 hours Not covered yet 10 CMS stops transferring data from Cessy output buffer time 9 T 0 Production stops min(T 0 input buffer/Cessy output buffer) or defined time to catch up 8 T 1/T 2 Production/analysis stops 7 Services critical when needed but not needed all the time (currently includes documentation) 0. 5 6 A service monitoring or documenting a critical service 8 5 CMS development stops if service unavailable 24 4 CMS development at CERN stops if service unavailable … more … CHEP 2007
LCG ATLAS Critical Services (PDF) Tier Service Criticality Consequences of service interuption 0 Oracle database RAC (online, ATONR) Very high Possible loss of DCS, Run Control, and Luminosity Block data while running. Run start needs configuration data from the online database. Buffering possibilities being investigated. 0 DDM central services Very high No access to data catalogues for production or analysis. All activities stops. 0 Data transfer High from Point 1 to Castor Short (<1 day): events buffered in SFO disks, backlog transferred as connection is resumed. Long (>1 day): loss of data. 3 D streaming No export of database data. Backlog can be transferred as [ soon as ] connections are resumed. … 0 -1 Moderate … more … CHEP 2007
LCG LHCb Critical Services (CCRC 08 wiki) Service Criticality CERN VO boxes 10=critical=0. 5 h max downtime CERN LFC service 10 VOMS proxy service 10 T 0 SE 7=serious=8 h max downtime T 1 VO boxes 7 SE access from WN 7 FTS channel 7 WN misconfig 7 CE access 7 Conditions DB access 7 LHCb Bookkeeping service 7 Oracle streaming from CERN 7 … more … CHEP 2007
ALICE critical services list l WLCG WMS (hybrid mode OK) l l l FTS for T 0 ->T 1 data replications l l LCG RB g. Lite WMS (g. Lite VO-box suite a must) SRM v. 2. 2 @ T 0+T 1 s CASTOR 2 + xrootd @ T 0 MSS with xrootd (d. Cache, CASTOR 2) @ T 1 PROOF@CAF @ T 0 20
LCG § § § CHEP 2007 Some First Observations Largely speaking, requirements on services are more stringent for Tier 0 than for Tier 1 s than for Tier 2 s… § Some lower priority services also at Tier 0… Maximum downtimes of 30’ can only be met by robust services, extensive automation and carefully managed services § Humans cannot intervene on these timescales if anything beyond restart of daemons / reboot needed (automate…) Small number of discrepancies (1? ): § ATLAS streaming to Tier 1 s classified as “Moderate” – backlog can be cleared when back online, whereas LHCb classify this as “Serious” – max 8 hours interruption § Also, ATLAS AMI database is hosted (exclusively? ) at LPSC Grenoble and is rated as “high” Now need to work through all services and understand if “standards” are being followed and if necessary monitoring and alarms are setup… Do we have measurable criteria by which to judge all of these services? Do we have the tools? (Again < CCRC’ 08…)
Robust Services • Services deployed at CERN with a view to robustness: – h/w, m/w, operational procedures, alarms, redundancy (power, network, middle-tier, DB b/e etc. ) • This was done using a ‘service dashboard’ & checklist at the time of SC 3 & re-visited recently – Extensive documentation on robustness to specific failure modes – highlights where to improve (FTS 2. 0) • Some degree of ‘rot’ – needs to be followed regularly • Some middleware improvements still required… • Sharing of experience / training would be valuable
Main Techniques Ø Understanding of implications of service downtime / degradation • Database clusters – not a non-stop solution; requires significant (but understood) work on behalf of application developer & close cooperation with DBAs • Load-balanced middle Tier – well proven; simple(!) • H/A Linux as a stop-gap (VOM(R)S); limitations • Follow-up: workshop at CERN in November following recent re-analysis with Tier 1 s and m/w developers • m/w & DB developers will share knowledge
Running the Services • Daily operations meeting as a central point for following service problems & interventions • Excellent progress in integrating grid services into standard operations • Consistent follow up – monitoring, logging, alarming – efficient problem dispatching MStill some holes – not everyone is convinced of the necessity of this… • Despite what experience tells us…
Cross-Site Services MThis is an area that is still not resolved • Excellent exposé of the issues involved at WLCG Collaboration Workshop in Victoria • But not presented due to time! • Will follow-up at WLCG Service Reliability workshop at CERN in November (26+) • Emphasizes the need for consistent (available) logging and good communication between teams • “UTC” – the Time of the Grid!
Guess-timates • Network cut between pit & B 513 ~1 per decade, fixed in ~4 hours (redundant) • Oracle cluster-ware “crash” ~1 per year (per RAC? ) – recovery < 1 hour • Logical data corruption – database level ~1 per decade, painful recovery (consistency checks) MScripts run directly against the (LFC) DB – much higher • Data corruption – file level Being addressed – otherwise a certainty! • Power & cooling – Will we get to (<) ~1 per site per year? Soon? • Critical service interruption – 1 per year per VO? – Most likely higher in 2008…
In a Nutshell… Services ALL WLCG / “Grid” standards KEY PRODUCTION SERVICES + Expert call-out by operator CASTOR/Physics DBs/Grid Data Management + 24 x 7 on-call (if agreed) • Several papers on this work exist (see CERN Document Server), covering various aspects of the subject (often limited by page count for conference in question). • Foresee a single paper summarizing the techniques and experience – deliverable of the WLCG Service Reliability workshop
Summary – We Know How to Do It! • Well-proven technologies & procedures can have a significant impact on service reliability and even permit transparent interventions • We have established a well-tested checklist for setting up and running such services • These services must then be run together with – and in the same manner as – the ‘IT (GRID) ones’ • These techniques are both applicable and available to other sites (T 1, T 2, …) • Follow-up: WLCG Service Reliability w/s: Nov 26+ • Report back to next OB: Dec 4
Conclusions • The “Residual Services” identified at last year’s LHCC Comprehensive Review have (largely) been delivered – or are in the final stages of preparation & deployment • We are now in a much better position wrt monitoring, accounting and reporting – running the service – No time to discuss these aspects! • Data taking with cosmics, Dress Rehearsals and CCRC’ 08 will further shake-down the service Ø Ramping up in reliability, throughput and capacity are key priorities • We are on target – but not ahead – for first pp collisions Ø A busy – but rewarding – year ahead!