Whats up in Business Intelligence A Contextual and

What’s up in Business Intelligence: A Contextual and Knowledge-Based Perspective Keynote @ ER’ 2013 Marie-Aude AUFAURE Head of the academic chair in Business Intelligence 15/09/2020 ER conference 2013 1

Agenda • Evolution of business intelligence – Semantic Business Intelligence – Real-Time Business Intelligence • Challenges and opportunities: – Ease of use – Personalization – Semantic technologies – Collaboration 15/09/2020 ER conference 2013 2
 refers to a set of tools and methods")
Business Intelligence • Business Intelligence (BI) refers to a set of tools and methods dedicated to collecting, representing and analyzing data to support decision-making in enterprises. • BI is defined as the ability for an organization to take all input data and convert them into knowledge, ultimately, providing the right information to the right people at the right time via the right channel. 15/09/2020 ER conference 2013 3

Evolution of Business Intelligence 15/09/2020 ER conference 2013 4

Change factors • Data heterogeneity 15/09/2020 ER conference 2013 5

Change factors • The way we interact together and with data/information 15/09/2020 ER conference 2013 6

BI needs to focus on: • Being simple to use • Turning any data into information/actionable knowledge • Empowering collaboration • Being integrated with the business processes 15/09/2020 ER conference 2013 7

Being simple to use Ease of use • Dynamic dashboards – Context-aware annotations • Storytelling – Collections of visual representations do not speak for themselves, Story do. • Visual analytics: – the science of analytical reasoning supported by highly interactive visual interfaces. 15/09/2020 ER conference 2013 8

Turning any data into information Semantic processing • helping to make sense of large or complex sets of data without being supplied with any knowledge about the data • Turning any data into information/actionable knowledge • Some examples: – NLP technologies – Data Mining – Artificial Intelligence – Classification – Semantic Search 15/09/2020 ER conference 2013 9

Turning any data into information Semantic technologies / Semantic Web • "The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation. “ (Tim Berners-Lee, 2001) • Standards include: – a flexible data model (RDF) – schema and ontology languages for describing concepts and relationships (RDFS and OWL) – a query language (SPARQL) • Use of semantic technologies in semantic processing (e. g. semantic search) • Use of semantic technologies for storing and querying data (triple store and SPARQL) 15/09/2020 ER conference 2013 10

Empowering collaboration Social web – Social Networks • The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2. 0. • Web 2. 0 allows users to express their opinion on products and services • Understanding “what people think” can support decision-making, both for consumers and producers 15/09/2020 ER conference 2013 11

Evolution of Business Intelligence 15/09/2020 ER conference 2013 12

And now? Big Data Open Data /Linked Data Connected objects 15/09/2020 ER conference 2013 13

BIG DATA Challenges: • Master the data • Master the system 15/09/2020 ER conference 2013 14

BIG DATA: SOCIETAL CHALLENGES • Big Data for Society: can we expect a positive impact on society? • Generate actionable information that can be used to identify needs, provide services, and predict and prevent crisis for the benefit of populations. • Health and well-being, environment, energy, climate change, etc. 15/09/2020 ER conference 2013 15

BIG DATA: TECHNOLOGICAL CHALLENGES • Data storage : data centers, cloud infrastructures, no. SQL databases, in-memory databases • Data processing : supercomputers, distributed or massively parallel-computing 15/09/2020 ER conference 2013 16

BIG DATA: ENERGY CHALLENGE • supercomputeurs 15/09/2020 ER conference 2013 17

BIG DATA: USE CASES 15/09/2020 ER conference 2013 18

Big Data opportunities Source: Big Data opportunities survey, Unisphere / SAP, May 2013. 15/09/2020 ER conference 2013 19

Predictive analytics: flu trends United states Flu Activity United States Data Google Flu Trends estimate 15/09/2020 ER conference 2013 20

360 -degree view of the customer 15/09/2020 ER conference 2013 21

Types of data used in Big Data initiatives Internal data Traditional sources « New data » Source: Big Data opportunities survey, Unisphere / SAP, May 2013. 22

Evolution of Business Intelligence 15/09/2020 ER conference 2013 23

Coming back to challenges and opportunities • Opportunities induced by Big Data for the following BI challenges: – Ease of use and recommendation/personalization – Turning any data into information/actionable knowledge – Collaboration • Combining a set of techniques for generating value: – Statistics, predictive models, semantic technologies, Natural Language processing, visual analytics 15/09/2020 ER conference 2013 24

15/09/2020 ER conference 2013 25

Ease of use Visual Analytics Inference of user preferences For personalization, recommendation and exploration 15/09/2020 ER conference 2013 26

CUBIST: Combining and Uniting Business Intelligence with Semantic Technologies

Formal Concept Analysis • Formal Concept Analysis is a method used for investigating and processing explicitely given information – An analysis of data – Structures of formal abstractions of concepts of human thought – Formal emphasizes that the concepts are mathematical objects, rather than concepts of mind – Formal Concept Analysis help to draw inferences, to group objects, and hence to create concepts • Visual representation by a Hasse Diagram 15/09/2020 ER conference 2013 28

Skill Charts, Graphs, FCA for BI: A Toy Example Persons with that Skill IE Anja, Ben, Ernst, Fred, Ken ETL Chris, Fred, Mark BI Ben, Chris, Fred, Lemmy, Mark, Naomi ST Anja, Diana, Ernst, Fred, Gerald, Harriet, Ken, Owen FCA Anja, Diana, Gerald, Harriet, Ian, John, Ken, Owen VIZ Anja, Diana, Ian Possible Information Needs: 1) Show me the count of people for a given skill 2) Show me the skills and how many people share some skills, in order to get an idea on how strongly skills are related 3) Show me the skills and people such that I get an idea of the distribution of skills among people and dependencies between skills 15/09/2020 ER conference 2013 29
 30")
Converting the data 15/09/2020 ER conference 2013 (analytic model) 30

Visualizing the data

Some Information which can be read off

Comparison

Which visualization should I choose? Remember the information needs from the beginning Show me the count of people for a given skill Show me the skills and how many people share some skills, in order to get an idea on how strongly skills are related Show me the skills and people such that I get an idea of the distribution of skills among people and dependencies between skills Conclusion § § Each visualization has its own strengths and weaknesses Each type of visualization is suited for a specific type of information needs Thus the visualizations are complementing Thus future BI tools should provide all types of visualizations 15/09/2020 ER conference 2013 34

Can you understand this? Traffic accidents dataset: 34 attributes, 150 objects, 344 concepts – minimal edge crossing layout 15/09/2020 ER conference 2013 35

FCA-based Visual Analytics • Idea: Create visual analytics for large contexts – – 15/09/2020 Context reduction Allow visual queries through selection and filtering Dynamic visualization Visual exploration becomes a navigation problem ER conference 2013 36

Cubix: A Visual Analytics tool for FCA • Combines interactive features to overcome drawbacks of single techniques Publication: ICDM 2012 [Melo et al. ] live: cubix. alwaysdata. com • Features – – – Visualisations Dashboard Metrics Filtering & Search Clustering Tree-Extraction 15/09/2020 ER conference 2013 37

Summary of Visualisations Analysis Task Data Visualisation Co-occurence analysis Concept Lattice Enhanced Hasse diagram Exploratory Tree from the Hierarchical analysis concept lattice Sunburst Frequent itemsets analysis Attributes and objects matrix Concept stacking (matrix) Simulation parameters analysis Multi-valued attributes Heatmap lattice Implication analysis Association Rules Radial/Matrix visualisation for Association Rules 15/09/2020 ER conference 2013 38

Coming back to ease of use • Cubix was experimented on three use cases – The workflow (data selection, scaling, filtering and analysis) needed to be simplified • User creation of Analytics – Leading to « BI as a service » • Automatic recommendation of Visualization and gadgets: – Decision tree • Based on the data type and volume – Collaborative filtering • Based on other user’s preferences for similar datasets – Supervised Learning methods • Based on users profile and history 15/09/2020 ER conference 2013 39
 •")
Coping with big data for FCA • Reduction techniques – Filtering (support, stability) • Distributed computing of concepts • Mining Formal Concepts over data streams • Visual Analytics – New metaphors for large data – Data overview: dashboards • Filtering 15/09/2020 ER conference 2013 40

Personalization Recommendation Inference of ontology-based user preferences from a history of spoken dialogues 15/09/2020 ER conference 2013 41

Context: the PARLANCE EU project • PARLANCE: Probabilistic Adaptive Real-Time Learning And Natural Conversational Engine • Goal: design and build mobile applications that approach human performance in conversational interaction • Develop dialogue system that is: – Incremental: dialogue act units – Personalized: adapt to different users with different goals in different contexts – Dynamic and evolving: possible to incorporate new concepts – Interactive hyper-local: take into account the location and surroundings of the user 15/09/2020 ER conference 2013 42

Motivating scenario • U 1: Right, I’m looking for a house with three bedrooms, . . 2 bathrooms with a garden. • S 1: . . . . . uhuh. . . [System starts search]. . . There are 4 houses and 2 flats in a 3 mile radius from your current location that match your search. 2 are by the river and 4 are in the centre of town. One near the river has been reduced in price. [NLG learns to Hyperlocal provide a summary then recommendation. Search gets latest news that house has been reduced. ] • U 2: Is it near a school? • S 2: Yes it’s near St Thomas school. [School name is added to the dynamic vocabulary. ] [User Model contains preferences for primary schools so only returns those schools. ] • S 3: Oh by the way there’s an open house this afternoon. • U 3: Right I’ll try that one. What’s the address? • S 4: 26 Waldorf drive. • U 4: Oh I don’t like that street. [User Model updates so that properties on that street are dispreferred by the user in the future. ] • U 5: Are there any other properties near St Thomas School. [System now recognises and understands “St Personalised Thomas School’. ] • S 5: Yes, there is the other one I mentioned near the river. It is on Cambridge Road. [System learns and adapts so that it presents the street as it now knows this is important to the user] • U 6: Oh that’s a lovely street. • S 6: Great, it has an open viewing this afternoon or I can give you the estate agent’s phone number. • U 7: Okay, I’ll go to the viewing. Incremental Dynamic

Context • Search personalization – Each user: distinct background and goal – Tailor search results to particular user based on interests and preferences – Decrease search ambiguity • Contextual retrieval: combine search technologies and knowledge about query and user context into single framework to provide most appropriate answer for a user’s information needs • Users formulate imprecise queries, and do not want to specify underlying intent and goals • 2 basic possibilities to personalize search – Query enrichment: related keyword suggestion – Re-ranking of results: personalized ranking criteria • Short and long term profiles 15/09/2020 ER conference 2013 44

Ontology-based user profiles

User’s interests • Attribute type scores – Initialized to 0, updated by 1 each time user requests instance with corresponding type value • Attribute value scores – Sum up to 1, initialized to 1/m – Smoothing method for updating: – Give more importance to recent dialogues in the history – Learning rate alpha: differ between long and short-term interests • Complementary negative model – To express disinterests 15/09/2020 ER conference 2013 46
 I am looking for a restaurant {inform(type = restaurant)} I’ll eat")
Interests Hello. hello() I am looking for a restaurant {inform(type = restaurant)} I’ll eat anything except Russian. { inform(food!="Russian") } I do not care what is the area. {inform(area=dontcare)} There is the restaurant “Cesars”. {inform(type=restaurant), inform(name=”cesars”) } Count frequencies of attribute What’s the price? Is it cheap? { request(price), values accross dialogues confirm(price=cheap) } No, it is expensive. negate(price=expensive) I would like some Italian food. { inform(food="Italian") } In the centre of town. <=> {inform(area="central") } There is a restaurant Luigi’s. {inform(type=restaurant), inform(name=”Luigi’s”)} Giving more weight to final choice What is the address? { request(addr) } within one dialogue The address is Oxford Street. {inform(address=”Oxford Street”)} What kind of music do they play? { request(music) } They play jazz music. {inform(music= ‘’jazz’’)} Thanks. thankyou() Bye. bye()
")
Interests Dialogue History Modular Ontology User Interests (JSON)

Interests: use of scores • Final score S: aggregation of weights • Wt: attribute type • Wv: Attribute value • Wi: Instance • Which instances to recommend? • Ranking of instances by scores S • What information to include in the system responses? • Proactively informing the user • E. g. mention food type but not Wifi (based on Wt) • E. g. only propose restaurants with dress code « formal » (based on Wv) 15/09/2020 ER conference 2013 49

Advantages of the approach • Natural fit with the ontological approach • Dynamic: interests evolve in time by analyzing logged dialogue history • Ambiguities of interests in same information type are resolved – E. g. user likes High Street for its restaurants, but does not want to live there • 2 different ontology modules 2 different interest scores for High Street according to domain of interest • Long-term and short-term uniformly modeled 15/09/2020 ER conference 2013 50

Extension: detection of user critiques • Preference-enabled query mechanism • The systems can interpret user preferences as hard constraints, (e. g. , price < 35 euro) and soft constraints (e. g. , preferring French food to Italian food). • The systems should provide optimal answers by exploring multiattribute tradeoffs (e. g. , price ↓; location ↓; service ↑). • The systems can improve the accuracy of answers according to user’s critiques (e. g. , cheaper and nearer). • Provide more relevant answers by contextual recommendation: – Querying knowledge base (persistent knowledge) – Considering ratings of user’s friends • Streaming data from social networks (Twitter) – C-SPARQL • Two-step process: – Refine queries based on user feedback – Assess relevance of items based on re-ranking 15/09/2020 ER conference 2013 51

Example Scenario Consider a female student Maria who is searching a restaurant for having her birthday dinner. An example of interaction between the Maria (U) and the system (S) can be shown as follow: 1)U: Where can I have my birthday dinner with 5 to 6 friends tonight? User request 2)S: Well, I suggest the medium size restaurants near to your place. I have found some French, Preference Chinese and also Italy restaurants. Which cuisine do you prefer? enrichment 3)U: I prefer French food, otherwise Italian food is also fine. Soft Constraint 4)S: I have found 10 French restaurants. The closest one is ‘Le Bon Plat’, next to the Secaux station. The price is medium, costing 35 euro person. Do you like it? 5)U: Sounds good, but is there any cheaper one? critique 6)S: Yes, a cheaper French restaurant ‘Le Gourmet’ costing 25 euro person is at the Antony Preference center. But you need to take the bus for 3 stops. Adjustment 7)U: Oh, no. I want to go by foot. critique 8)S: In this case, there is no suitable French restaurant. How about an Italian restaurant? ‘Bel Cibo’ is on St. Velpeau, one kilometer far from your place. It costs 28 euro person. 9)U: nice, l will choose this one. Locate the target choice 52
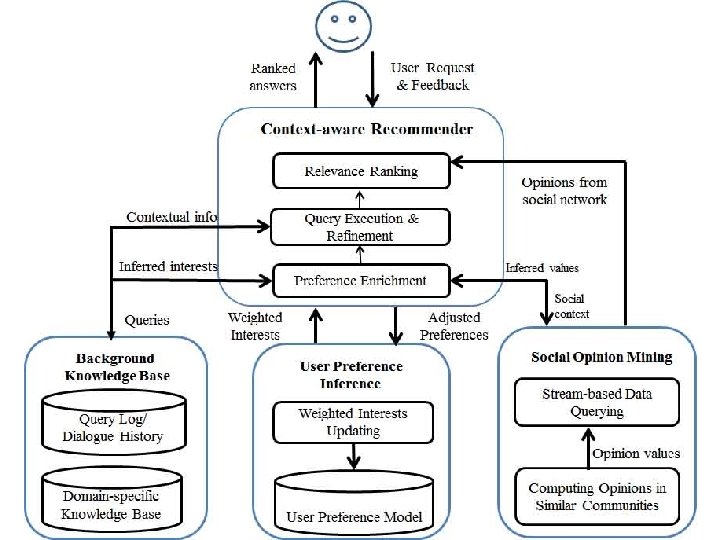

Social search • Collaborative filtering – Users in the neighborhood sharing similar interests – E. g. user wants Italian restaurant { inform(type=restaurant), inform(food="Italian") } • System recommends instances based on Italian restaurants other users like (weights of instances in ontology module) { confirm(type=restaurant), confirm(name=Al Trento) } Similar users with similar preferences: Users that like italian restaurants also like restaurants with a terrace • System proactively mentions the restaurant has a terrace { confirm(type=restaurant), confirm(terrace=yes) } 15/09/2020 ER conference 2013 54

Lattice-based social search • Inference of shared interests – User interests expressed as weighted modular ontologies Name Foodtype Restaurant Italian Wv(italian) = 0. 8 French Wv(french) = 0. 5 Location … Dresscode Decide on user’s interests with threshold T 15/09/2020 ER conference 2013 55
 > 0. 7 CONCEPT LATTICE 15/09/2020 ER conference")
Lattice-based social search FORMAL CONTEXT Wv(italian) > 0. 7 CONCEPT LATTICE 15/09/2020 ER conference 2013 56
![Lattice-based social search • Association rules 1 < 7 > DC: formal =[86 %]=>](http://slidetodoc.com/presentation_image/230b089a2afd9619b3e64dc426a7af8a/image-57.jpg "Lattice-based social search • Association rules 1 < 7 > DC: formal =[86 %]=>")
Lattice-based social search • Association rules 1 < 7 > DC: formal =[86 %]=> < 6 > FT: French; 2 < 7 > FT: Indian =[86 %]=> < 6 > loc: Paris; 3 < 5 > loc: Paris DC: formal =[100 %]=> < 5 > FT: French; Support: proportion of users that have interest in set of attributes 4 < 6 > FT: French DC: formal =[83 %]=> < 5 > loc: Paris; 5 < 6 > loc: Paris FT: French =[83 %]=> < 5 > DC: formal; 6 < 6 > FT: Italian =[83 %]=> < 5 > FT: French; 7 < 6 > FT: Italian =[83 %]=> < 5 > loc: Paris; 8 < 4 > loc: Paris FT: Italian FT: French =[100 %]=> < 4 > DC: formal; Confidence: proportion of users interested in rules’ consequent, given being interested in antecedent 9 < 4 > FT: Italian DC: formal =[100 %]=> < 4 > loc: Paris FT: French; In case no italian restaurant in neighborhood: ask if the user is 11 < 4 > FT: French with. Terrace =[100 %]=> < 4 > DC: formal; interested in french as alternative 12 < 4 > DC: formal with. Terrace =[100 %]=> < 4 > FT: French; 10 < 4 > FT: Indian FT: French =[100 %]=> < 4 > loc: Paris; 13 < 5 > conn: wifi =[80 %]=> < 4 > FT: Indian; 14 < 5 > loc: Paris FT: French DC: formal =[80 %]=> < 4 > FT: Italian; Minimal support and confidence to select sets of interests 15 < 5 > FT: Italian FT: French =[80 %]=> < 4 > loc: Paris DC: formal; 16 < 3 > loc: Paris FT: Indian FT: French DC: formal =[100 %]=> < 3 > FT: Italian; 57

Value of Personalization • Personalization in spoken dialogue search systems can be applied to call centers, retail • Critical for user’s perceived quality of experience and adoption by consumers – Spoken interaction: not feasible to give list of possible answers to search – Limited number of items are returned, tailored to the user’s interests, similar users and the situation • Opportunities: – Distributed and evolutive representation of user profiles as weighted concepts of ontologies linked to data streams – Data streams and alerts recommendation according to: • The user profile • Her social activity on the web (blogs, social newtorks) • A multi-criteria query • The spatio-temporal context (e. g. detection of anomalous traffic) 15/09/2020 ER conference 2013 58

Turning any data into information/actionable Knowledge Linked Data Open Data Semantic Technologies 15/09/2020 ER conference 2013 59
")
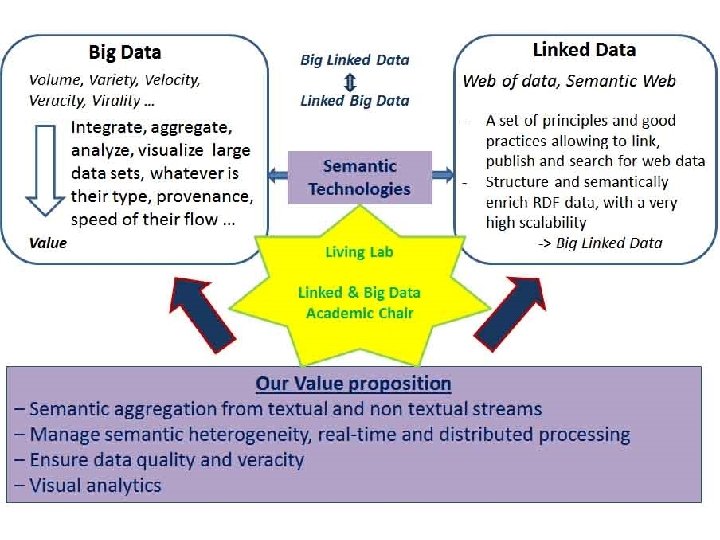
Semantic Technologies for Big Data • Data-driven approaches (structure learning, data mining, statistical approaches) are not always sufficient to find all correlations among parameters • Semantic approaches can provide complementary information: – Simplify the information integration process – Provide a unified metadata layer – Discover and enrich information – Provide a unified access to information 15/09/2020 ER conference 2013 60

Semantic Data Aggregation and Linking for Big Data • Transforming unstructured content into a structured format for later analysis is a major challenge. • The value of data explodes when it can be linked with other data, thus data integration is a major creator of value • Data aggregation from various sources can establish the veracity • Semantic technologies are a way of addressing variety 15/09/2020 ER conference 2013 61

Linked Data / Web of Data • Linked Data is a set of principles that allows publishing, querying and consumption of RDF data, distributed across different servers • Not necessarily free / open data • Exponential growth -> a Big Data approach: enriching Big Data with metadata & semantics, interlinking Big Data sets • Pricewaterhouse. Coopers, 2009: « You’ll be able to find pieces of data sets from different places, aggregate them without warehousing, and analyse them in a more straightforward, powerful way » 15/09/2020 ER conference 2013 62
 • Ontology Engineering techniques")
Semantic Technologies for Big Data • Natural Language Processing (NLP) • Ontology Engineering techniques • Semantic enrichment: – – – 15/09/2020 Addition of contextual information Semantic annotation Data categorization / classification Improved information retrieval Reasoning ER conference 2013 63

Semantic Data Aggregating and Linking for Big Data

LOD-Based Semantic Enrichment 15/09/2020 ER conference 2013 65

Pattern-based Technique 15/09/2020 ER conference 2013 66

Semantic Enrichment 15/09/2020 ER conference 2013 67

Value of Semantic Technologies • Semantic Technologies provide opportunities for reducing the cost and complexity of data integration • Common metadata layer • Powerful solutions to find and explore information • Semantic Technologies are a good fit for Big Data’s Variety • Velocity and Volume: challenging issues for Semantic Technologies • Linked Data will grow into Big Linked Data, but Big Data will also benefit from evolving into Linked Big Data 15/09/2020 ER conference 2013 68

Conclusion • Many models should be combined: – Ontologies, graphs, formal concepts, predictive models • Many techniques should be combined: – Natural language processing – Machine learning and statistics – Ontology engineering, Linked Data Management – Graphs processing – Visualization – Crowdsourcing, scrapping • For Semantic Enrichment 15/09/2020 ER conference 2013 69

Challenges • Semantic Information aggregation – Pattern extraction from streams and cross-analysis – Information extraction from Linked Open Data: concepts and relations linked to the streams patterns – Opinion aggregation from social media and web – Social aspects for collaboration – Information aggregation: “too much data to assimilate but not enough knowledge to act” • Distributed and real-time processing – Design of real-time and distributed algorithms for stream processing and information aggregation – Storage and indexation of a knowledge base – Integration of business processes with aggregated information – Distribution and parallelization of data mining algorithms • visual analytics and user modeling – Dynamic user model – Novel visualizations for very large datasets 15/09/2020 ER conference 2013 70

Opportunities: big data use cases

QUESTIONS?

Many thanks to: - SAP and the European Commission for their financial support - The ER committees and the University of Hong Kong - All members of my team

• Links: – CUBIST: http: //www. cubist-project. eu/ – PARLANCE: https: //sites. google. com/site/parlanceprojectofficial – CUBIX (open source tool): https: //github. com/ksiomelo/cubix/ • Further readings: • • • M. Cataldi, A. Ballatore, I. Tiddi, M-A. Aufaure (2013) Good Location, Terrible Food: Detecting Feature Sentiment in User -Generated Reviews, International Journal of Social Network Analysis and Mining (SNAM), 2013. Ben Mustapha N. , Aufaure M-A. , Baazaoui-Zghal H. , Ben-Ghézala H. (2013) Query-driven approach of contextual ontology module learning using web snippets, special issue on Database Management and Information Retrieval, Journal of Intelligent Information Systems JIIS, 2013. Cassio Melo, Bénédicte Le Grand Marie-Aude Aufaure, Browsing Large Concept Lattices through Tree Extraction and Reduction Methods, special CUBIST edition of the International Journal of Intelligent Information Technologies (IJIIT), 2013. Etienne Cuvelier and Marie-Aude Aufaure. Graph Mining and Community Detection. Springer LNBIP 96 (Lecture Notes in Business Intelligence Processing), pp. 117 -138, ISSN: 1865 -1348, 2012. Marie-Aude Aufaure, Nicolas Kuchmann Beauger, Patrick Marcel, Stefano Rizzi, Yves Vanrompay, Predicting your next OLAP query based on recent analytical sessions, Proceedings of the 15 th International conference on data warehousing and knowledge discovery (Da. Wa. K 2013), pp. 134 -145, Springer LNCS. Hu, B. , Vanrompay, Y, Aufaure, M. A. (2013). PQMPMS: A Preference-enabled Querying Mechanism for Personalized Mobile Search. Web Reasoning and Rules (RR'13 ), pp. 235 -240. Elias M. , Aufaure M. -A. , Bezerianos A. Storytelling in Visual Analytics tools for Business Intelligence. INTERACT 2013 - 14 th IFIP TC 13 Conference on Human-Computer Interaction, pp. 280 -297, South Africa (2013) Cassio Melo, Alexander Mikheev, Bénédicte Le Grand Marie-Aude Aufaure (2012) Cubix: A Visual Analytics Tool for Conceptual and Semantic Data, IEEE International Conference on Data Mining (ICDM 2012), Brussels, December 10 -13, 2012. Claudio Schifanella, Luigi Di Caro, Mario Cataldi, Marie-Aude Aufaure "D-INDEX: a Web Environment for Analyzing Dependencies among Scientific Collaborators", 18 th ACM SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2012), pp. 1520 -1523, Beijing, August 12 -16 2012.
- Slides: 75