What is Serialization Serialization is the process of














- Slides: 20
What is Serialization? • Serialization is the process of turning structured objects into a byte stream for transmission over a network or for writing to persistent storage. • Deserialization is the reverse process of turning a byte stream back into a series of structured objects.
Advantages of Serialization • Compact - A compact format makes the best use of network bandwidth, which is the most scarce resource in a data center. • Fast - Interprocess communication forms the backbone for a distributed system, so it is essential that there is as little performance overhead as possible for the serialization and deserialization process. • Extensible - Protocols change over time to meet new requirements, so it should be straightforward to evolve the protocol in a controlled manner for clients and servers. • Interoperable - For some systems, it is desirable to be able to support clients that are written in different languages to the server, so the format needs to be designed to make this possible.
What is Writable? • Hadoop defines its own ‘box classes’ for strings, integers and so on – Int. Writable for ints – Long. Writable for longs – Float. Writable for floats – Double. Writable for doubles – Text for strings – Etc. • The Writable interface makes serialization quick and easy for Hadoop • Any value’s type must implement the Writable interface
What is Writable. Comparable? • A Writable. Comparable is a Writable which is also Comparable – Two Writable. Comparables can be compared against each other to determine their ‘order’ – Keys must be Writable. Comparables because they are passed to the Reducer in sorted order • Note that despite their names, all Hadoop box classes implement both Writable and Writable. Comparable – For example, Int. Writable is actually a Writable. Comparable
Instruction
• Extract and upload the file in one step • gunzip -c access_log. gz | hadoop fs -put - weblog/access_log • tar zxvf shakespeare. tar. gz | hadoop fs -put shakespeare input • Hadoop 구동 방법 1. 2. Input 파일을 HDFS상에 올린다. Java 코드를 eclipse상에서 import한 후에 jar파일로 expor한다. • 터미널 명령어로 컴파일 후 jar파일 만드는 법(주어진 vm에서는 안됨) • javac -classpath `hadoop classpath` *. java • jar cvf wc. jar *. class 3. 터미널에서 Hadoop 명령어를 사용하여 실행 • Hadoop jar [jar file] [Driver Class name] [hdfs-inputpath] [hdfsoutputpath] • hadoop jar wc. jar Word. Count shakespeare wordcounts
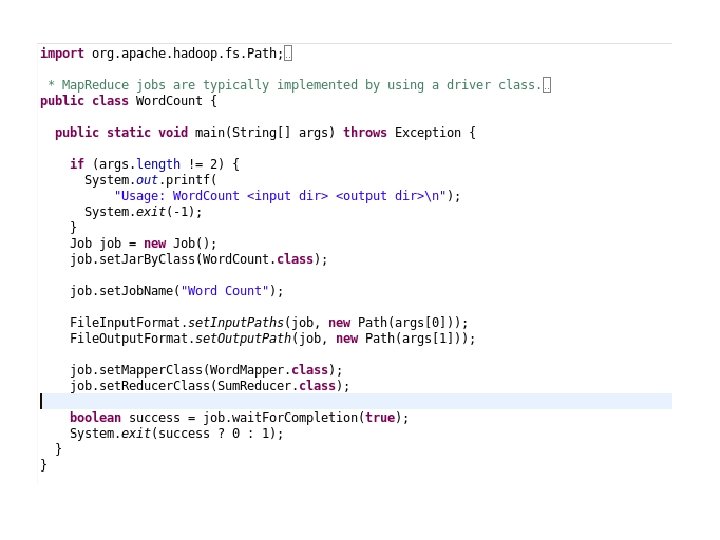
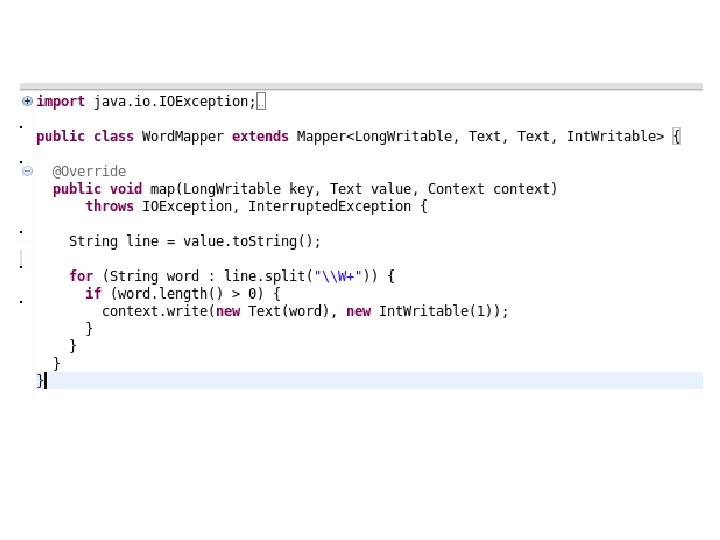
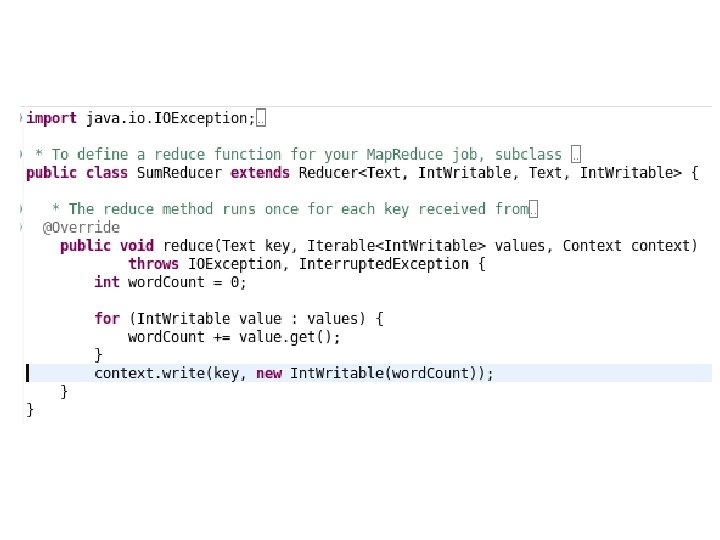
Word. Count
Goal Input Output
데이터 업로드와 실행 $ cd ~/training_materials/developer/data $ tar zxvf shakespeare. tar. gz | hadoop fs -put shakespeare input $ hadoop jar Word. Count input/shakespeare/* /user/shakes. Output
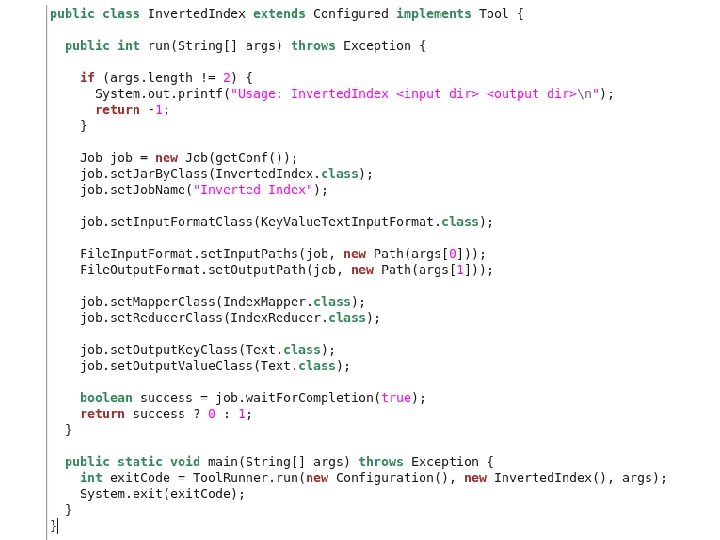
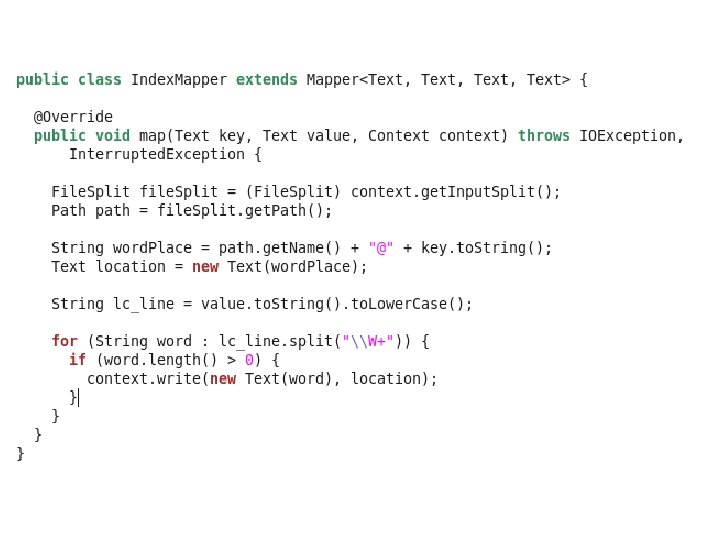
Inverted Index
Goal Input Output abominably hamlet@2787 abomination rapeoflucrece@876, rapeoflucrece@1124 abominations rapeoflucrece@2167, antonyandcleopatra@3028 abortive loveslabourslost@197, 2 kinghenryvi@3108, kingrichardiii@1067, kingrichardiii@386 abortives kingjohn@2037
데이터 업로드와 실행 $ cd ~/training_materials/developer/data $ tar zxvf inverted. Index. Input. tgz $ hadoop fs –put inverted. Index. Input $ hadoop jar Inverted. Index inverted. Index. Input output Output