What is a P 2 P system Node




 (File sharing) Distributed application data get (key) Distributed")
 and get(key) value • Simple")

![Recent DHT-based projects • • File sharing [CFS, Ocean. Store, PAST, Ivy, …] Web](https://slidetodoc.com/presentation_image/239557727fb91fc414dbdeed09b00f79/image-8.jpg "Recent DHT-based projects • • File sharing [CFS, Ocean. Store, PAST, Ivy, …] Web")

 Distributed hash tables put (key, block)")

 431=SHA-1")

 3. Handling failures")
, Value=data…) Publisher N 2 Internet N")
 N 1 N 2 Set. Loc(“title”, N 4) Publisher@N 4 Key=“title”")
 N 2 N 1 Publisher@N 4 Key=“title” Value=MP 3 data… N")


) hops N 5 N 10 K 19 N 20 N 110")


 nodes have fingers pointing")



 hops If system is stable But,")
![Half-life [Liben-Nowell 2002] N new nodes join N nodes N/2 old nodes leave •](https://slidetodoc.com/presentation_image/239557727fb91fc414dbdeed09b00f79/image-31.jpg "Half-life [Liben-Nowell 2002] N new nodes join N nodes N/2 old nodes leave •")




![Sybil attack [Douceur 02] N 5 N 10 N 110 N 20 N 99](https://slidetodoc.com/presentation_image/239557727fb91fc414dbdeed09b00f79/image-36.jpg "Sybil attack [Douceur 02] N 5 N 10 N 110 N 20 N 99")


")


- Slides: 41
What is a P 2 P system? Node Internet Node • A distributed system architecture: • No centralized control • Nodes are symmetric in function • Large number of unreliable nodes • Enabled by technology improvements
How to build critical services? • Many critical services use Internet • Hospitals, government agencies, etc. • These services need to be robust • Node and communication failures • Load fluctuations (e. g. , flash crowds) • Attacks (including DDo. S)
The promise of P 2 P computing • Reliability: no central point of failure • Many replicas • Geographic distribution • High capacity through parallelism: • Many disks • Many network connections • Many CPUs • Automatic configuration • Useful in public and proprietary settings
Traditional distributed computing: client/server Server Client Internet Client • Successful architecture, and will continue to be so • Tremendous engineering necessary to make server farms scalable and robust
The abstraction: Distributed hash table (DHT) (File sharing) Distributed application data get (key) Distributed hash table lookup(key) node IP address Lookup service put(key, data) node …. (DHash) (Chord) node • Application may be distributed over many nodes • DHT distributes data storage over many nodes
A DHT has a good interface • Put(key, value) and get(key) value • Simple interface! • API supports a wide range of applications • DHT imposes no structure/meaning on keys • Key/value pairs are persistent and global • Can store keys in other DHT values • And thus build complex data structures
A DHT makes a good shared infrastructure • Many applications can share one DHT service • Much as applications share the Internet • Eases deployment of new applications • Pools resources from many participants • Efficient due to statistical multiplexing • Fault-tolerant due to geographic distribution
Recent DHT-based projects • • File sharing [CFS, Ocean. Store, PAST, Ivy, …] Web cache [Squirrel, . . ] Archival/Backup store [Hive. Net, Mojo, Pastiche] Censor-resistant stores [Eternity, Free. Net, . . ] DB query and indexing [PIER, …] Event notification [Scribe] Naming systems [Chord. DNS, Twine, . . ] Communication primitives [I 3, …] Common thread: data is location-independent
Roadmap • One application: CFS/DHash • One structured overlay: Chord • Alternatives: • Other solutions • Geometry and performance • The interface • Applications
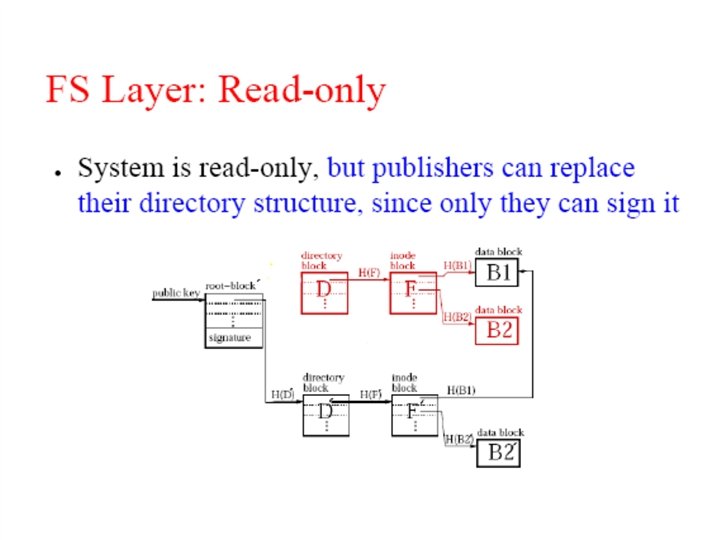
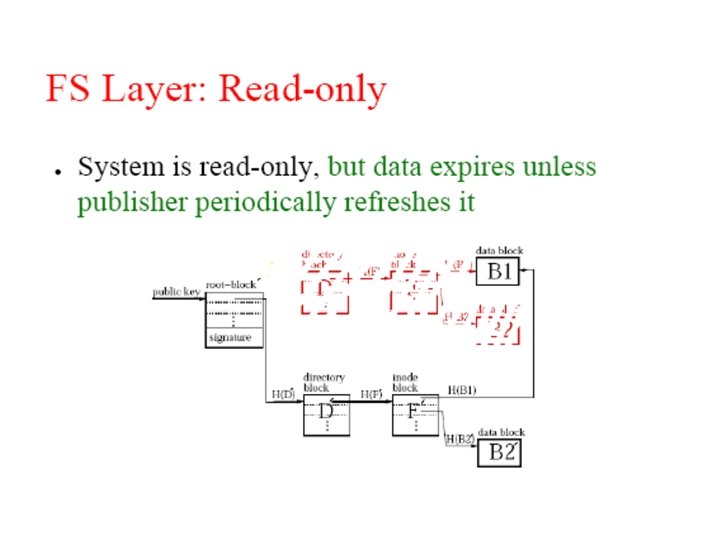
CFS: Cooperative file sharing File system get (key) Distributed hash tables put (key, block) node • • node DHT used as a robust block store Client of DHT implements file system • • Read-only: CFS, PAST Read-write: Ocean. Store, Ivy …. block node
CFS Design
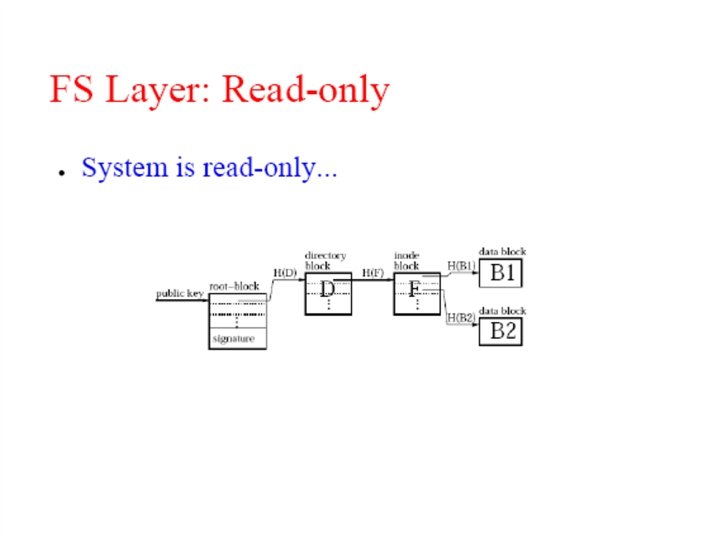
File representation: self-authenticating data File System key=995 995: key=901 key=732 Signature (root block) 431=SHA-1 144 = SHA-1 … 901= SHA-1 key=431 “a. txt” ID=144 key=795 … (i-node block) … (data) … (directory blocks) Signed blocks: – Root blocks; Chord ID = H(publisher's public key) Unsigned blocks – Directory blocks, inode blocks, data blocks; – Chord ID = H(block contents)
DHT distributes blocks by hashing IDs Block 732 995: key=901 key=732 Signature Block 407 Block 705 Node B Node A Internet Node C 247: key=407 key=992 key=705 Signature Node D Block 901 Block 992 • DHT replicates blocks for fault tolerance • DHT caches popular blocks for load balance
DHT implementation challenges 1. Scalable lookup 2. Balance load (flash crowds) 3. Handling failures 4. Coping with systems in flux 5. Network-awareness for performance 6. Robustness with untrusted participants 7. Programming abstraction 8. Heterogeneity 9. Anonymity 10. Indexing Goal: simple, provably-good algorithms
1. The lookup problem N 1 Put (Key=sha-1(data), Value=data…) Publisher N 2 Internet N 4 N 5 N 3 ? Client Get(key=sha-1(data)) N 6 • Get() is a lookup followed by check • Put() is a lookup followed by a store
Centralized lookup (Napster) N 1 N 2 Set. Loc(“title”, N 4) Publisher@N 4 Key=“title” Value=file data… N 3 DB N 9 N 6 N 7 Client Lookup(“title”) N 8 Simple, but O(N) state and a single point of failure
Flooded queries (Gnutella) N 2 N 1 Publisher@N 4 Key=“title” Value=MP 3 data… N 6 N 7 N 3 Lookup(“title”) Client N 8 N 9 Robust, but worst case O(N) messages per lookup
Algorithms based on routing • Map keys to nodes in a load-balanced way • Hash keys and nodes into a string of digit • Assign key to “closest” node • Forward a lookup for a key to a closer node K 5 K 20 N 105 Circular ID space N 90 K 80 N 60 • Join: insert node in ring Examples: CAN, Chord, Kademlia, Pastry, Tapestry, Viceroy, …. N 32
Chord’s routing table: fingers ¼ 1/8 1/16 1/32 1/64 1/128 N 80 ½
Lookups take O(log(N)) hops N 5 N 10 K 19 N 20 N 110 N 99 N 32 Lookup(K 19) N 80 N 60 • Lookup: route to closest predecessor
Can we do better? • Caching • Exploit flexibility at the geometry level • Iterative vs. recursive lookups
2. Balance load N 5 K 19 N 10 K 19 N 20 N 110 N 99 N 32 Lookup(K 19) N 80 N 60 • Hash function balances keys over nodes • For popular keys, cache along the path
Why Caching Works Well N 20 • Only O(log N) nodes have fingers pointing to N 20 • This limits the single-block load on N 20
3. Handling failures: redundancy N 5 N 10 N 110 K 19 N 20 N 99 N 32 N 40 K 19 N 80 N 60 • Each node knows IP addresses of next r nodes • Each key is replicated at next r nodes
Lookups find replicas N 5 N 10 N 110 1. N 99 RPCs: 1. Lookup step 2. Get successor list 3. Failed block fetch 4. Block fetch 2. N 20 3. 4. N 40 N 50 N 80 N 68 N 60 Lookup(Block. ID=17) Block 17
First Live Successor Manages Replicas N 5 N 10 N 110 N 20 N 99 Copy of 17 N 40 Block 17 N 50 N 80 N 68 N 60 • Node can locally determine that it is the first live successor
4. Systems in flux • Lookup takes log(N) hops If system is stable But, system is never stable! • What we desire are theorems of the type: 1. In the almost-ideal state, …. log(N)… 2. System maintains almost-ideal state as nodes join and fail
Half-life [Liben-Nowell 2002] N new nodes join N nodes N/2 old nodes leave • Doubling time: time for N joins • Halfing time: time for N/2 old nodes to fail • Half life: MIN(doubling-time, halfing-time)
Applying half life • For any node u in any P 2 P network: If u wishes to stay connected with high probability, then, on average, u must be notified about (log N) new nodes per half life • And so on, …
5. Optimize routing to reduce latency N 20 N 40 N 80 N 41 • Nodes close on ring, but far away in Internet • Goal: put nodes in routing table that result in few hops and low latency
“close” metric impacts choice of nearby nodes USA Far east N 105 N 06 USA K 104 N 103 N 32 Europe N 60 USA • Chord’s numerical close and (original) routing table restrict choice • Should new nodes be able to choose their own ID • Other allows for more choice (e. g. , prefix based, XOR)
6. Malicious participants • Attacker denies service • Flood DHT with data • Attacker returns incorrect data [detectable] • Self-authenticating data • Attacker denies data exists [liveness] • Bad node is responsible, but says no • Bad node supplies incorrect routing info • Bad nodes make a bad ring, and good node joins it Basic approach: use redundancy
Sybil attack [Douceur 02] N 5 N 10 N 110 N 20 N 99 N 32 N 40 • Attacker creates multiple identities • Attacker controls enough nodes to foil the redundancy N 80 N 60 Ø Need a way to control creation of node IDs
One solution: secure node IDs • Every node has a public key • Certificate authority signs public key of good nodes • Every node signs and verifies messages • Quotas per publisher
Another solution: exploit practical byzantine protocols N 105 N 103 N 06 N N 32 N N 60 • A core set of servers is pre-configured with keys and perform admission control [Ocean. Store] • The servers achieve consensus with a practical byzantine recovery protocol [Castro and Liskov ’ 99 and ’ 00] • The servers serialize updates [Ocean. Store] or assign secure node Ids [Configuration service]
A more decentralized solution: weak secure node IDs • ID = SHA-1 (IP-address node) • Assumption: attacker controls limited IP addresses • Before using a node, challenge it to verify its ID
Using weak secure node IDS • Detect malicious nodes • Define verifiable system properties • Each node has a successor • Data is stored at its successor • Allow querier to observe lookup progress • Each hop should bring the query closer • Cross check routing tables with random queries • Recovery: assume limited number of bad nodes • Quota per node ID
Summary http: //project-iris. net