Welcome to xhzhouustc edu cn yumingcmail ustc edu

 • 助教:程玉明(yumingc@mail. ustc. edu. cn) 夏昊珺(xhjustc@mail. ustc.")


 Microarchitecture Gates/Register-Transfer")





 1992 -97 • HP PA-RISC (v")
 Registers • 指令类型 – Load/Store – Computational")


 – Class of ISA:")




 – ISAs, Iron Law,")










 Compiler Software Hardware Assembler Operating System (Mac OSX)")


 – smart phones, tablet computers – >1 billion sold/year –")

 • 集群/仓储级计算机(Clusters / Warehouse Scale Computers) – – 100, 000’s cores per warehouse")



![Abstraction via Layers of Representation temp = v[k]; v[k] = v[k+1]; v[k+1] = temp;](https://slidetodoc.com/presentation_image_h2/86ac8658451c03817d968c318874b821/image-40.jpg "Abstraction via Layers of Representation temp = v[k]; v[k] = v[k+1]; v[k+1] = temp;")









),芯片集成度不断提高 – Circuits become faster")

 10 -Core Xeon Westmere-EX introduced in 2011 has")


 • • • CDC Wren I, 1983")
 • Performance Milestones • Disk: 3600, 5400, 7200,")
 • Performance Milestones • Memory Module: 16 bit")
 • Performance Milestones • Ethernet: 10 Mb/s, 1000")

 4 -bit → 8")






: 4 -bit processor, 2312 transistors,")




 Emphasis on energy")



 Boeing 747 6. 5 hours")




: 包括完成一个任务所需要的所有时间 • User CPU Time (90. 7) •")

 Op Freq CPIi*Fi ALU 50% 1. 5 Load")
 Compiler X X Inst. Set. X X Organization")







 • Desktop Benchmarks – – – SPEC")





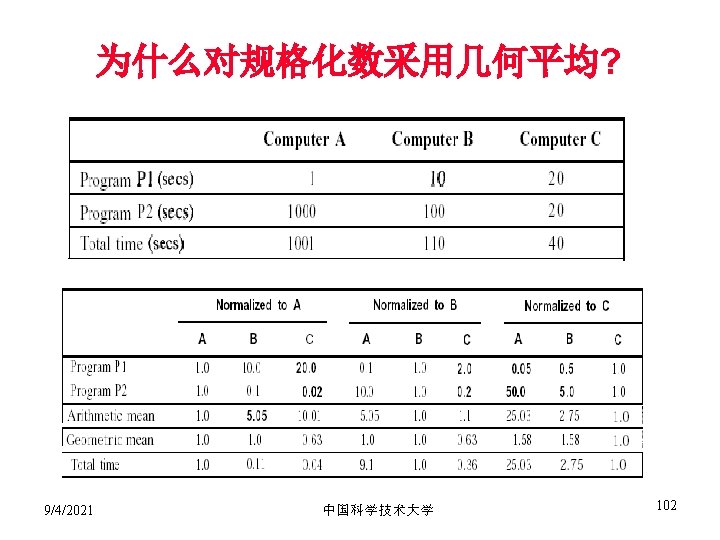


 指单位时间的能耗: 1 Watt = 1 Joule / Second •")







 • 当晶体管处于off状态时, 漏电流的流动产生的功耗称为静 态功耗 • 随着晶体管尺寸的减少漏电流的大小在增加 • Static Power = Static")

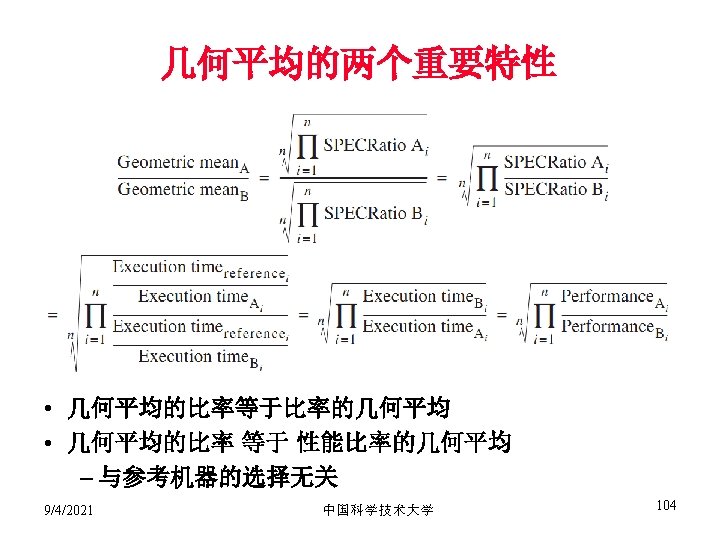
 EDP = Energy ∗ Delay = Power ∗")

 • Amdahl’s 定律: Speedupoverall = Ex. Timeold Ex. Timenew 1 = (1")
")



















- Slides: 138
Welcome to …… • 主讲:周学海(xhzhou@ustc. edu. cn) • 助教:程玉明(yumingc@mail. ustc. edu. cn) 夏昊珺(xhjustc@mail. ustc. edu. cn) 俞天灿(ytc 2013@mail. ustc. edu. cn) • 办公地点: 嵌入式系统实验室 (网络中心西区服务部内) • 办公电话: 0551 -63606864 0551 -63492149 • 课程主页: http: //staff. ustc. edu. cn/~xhzhou/CA-Spring 2018/CA. html 9/4/2021 中国科学技术大学 2
教材与主要参考书 • John L. Hennessy, David A. Patternson, Computer Architecture: A Quantitative Approach. Fifth Edition. 机械 业出版社, 2012 • David A. Patternson, John L. Hennessy, Computer Organization & Design : The Hardware/Software Interface, Third Edition. San Francisco: Morgan Kaufmann Publishers, Inc. 2005 • 张晨曦等,计算机系统结构教程,清华大学 出版社 9/4/2021 中国科学技术大学 3
What is Computer Architecture? Application Gap too large to bridge in one step (but there are exceptions, e. g. magnetic compass) Physics In its broadest definition, computer architecture is the design of the abstraction layers that allow us to implement information processing applications efficiently using available manufacturing technologies. 4 中国科学技术大学 9/4/2021
现代计算机系统的抽象层次 Application Algorithm Programming Language Operating System/Virtual Machine Instruction Set Architecture (ISA) Microarchitecture Gates/Register-Transfer Level (RTL) Circuits Devices Physics 9/4/2021 中国科学技术大学 5
ISA: a Critical Interface software instruction set hardware 9/4/2021 中国科学技术大学 9
ISA需说明的主要内容 • • Memory addressing Addressing modes Types and sizes of operands Operations Control flow instructions Encoding an ISA …… • 优秀的ISA所具有的特征 – 可持续用于很多代机器上(portability) – 可以适用于多个领域 (generality) – 对上层提供方便的功能(convenient functionality) – 可以由下层有效地实现(efficient implementation ) – …… 中国科学技术大学 9/4/2021 10
指令集结构举例 • Digital Alpha (v 1, v 3) 1992 -97 • HP PA-RISC (v 1. 1, v 2. 0) 1986 -96 • Sun Sparc (v 8, v 9) 1987 -95 • SGI MIPS (MIPS I, III, IV, V) 1986 -96 • Intel(8086, 80286, 80386, 80486, Pentium, MMX, . . . ) 1978 -96 9/4/2021 中国科学技术大学 11
MIPS R 3000 Instruction Set Architecture (Summary) Registers • 指令类型 – Load/Store – Computational – Jump and Branch – Floating Point R 0 - R 31 PC HI » coprocessor – Memory Management – Special LO 3 种指令格式: all 32 bits wide R型 OP rs rt I型 OP rs rt J型 OP 9/4/2021 rd sa funct immediate jump target 中国科学技术大学 12
Example Organization • TI Super. SPARCtm TMS 390 Z 50 in Sun SPARCstation 20 MBus Module Super. SPARC Floating-point Unit L 2 $ Integer Unit Inst Cache Ref MMU Data Cache Store Buffer Bus Interface 9/4/2021 CC MBus L 64852 MBus control M-S Adapter SBus DMA SBus Cards 中国科学技术大学 SCSI Ethernet DRAM Controller STDIO serial kbd mouse audio RTC Boot PROM Floppy 14
体系结构 vs. 微结构 • Architecture / Instruction Set Architecture (ISA) – Class of ISA: register-memory or register architectures – Programmer visible state (Register and Memory) – Addressing Modes: how memory addresses are computed – Data types and sizes for integer and floatingpoint operands – Instructions, encoding, and operation – Exception and Interrupt semantics • Microarchitecture / Organization implement the ISA for 中国科学技术大学 9/4/2021 – Tradeoffs on how to speed, energy, cost 15
计算机体系结构设计者的任务 • 设计和实现不同档次的计算机系统 – – Understand software demands Understand technology trends Understand architecture trends Understand economics of computer systems • 最大化性能、可编程性等指标 – 在一定的技术和成本的限制下 • 体系结构现状: – Today’s microprocessors are multiprocessors – Several cores on a single chip – Each core capable of executing multiple threads 9/4/2021 中国科学技术大学 16
计算机体系结构设计过程 体系结构设计是循环渐进的过程: • Search the possible design space • Make selections • Evaluate the selections made Creativity Cost / Performance Analysis Good Ideas Bad Ideas Mediocre Ideas Good measurement tools are required to accurately evaluate the selection. 中国科学技术大学 17 9/4/2021
计算机 程方法学 Evaluate Existing Implementation Systems for Complexity Bottlenecks Implementation Analysis Benchmarks Technology Trends Implement Next Generation System Simulate New Designs and Organizations Workloads Design 9/4/2021 中国科学技术大学 18
本课程的主要内容 • Simple machine design(Chapter 1, Appendix A, Appendix C) – ISAs, Iron Law, simple pipelines • Memory hierarchy (Chapter 2,Appendix B) – DRAM, caches, virtual memory systems • Complex pipelining (Chapter 3) – score-boarding, out-of-order issue • Explicitly parallel processors (Chapter 4) – vector machines, VLIW machines, multithreaded machines • Multiprocessor architectures (Chapter 5, Chapter 6) 9/4/2021 – memory 中国科学技术大学synchronization models, cache coherence, 20
为什么学这门课 深入理解计算机体系结构: • 开展体系结构研究与设计的基础 – There are still many challenges left – Example: the CPU-memory gap – ……. • 更好地设计与实现操作系统、编译器 – Need to re-evaluate the current assumptions and tradeoffs – Example: gigabit networks, Parallel systems, Heterogeneous systems – Modern computers need better optimizing compilers and better programming languages 中国科学技术大学 9/4/2021 • 更好地设计与实现应用程序 21
Computing Devices Then… 9/4/2021 EDSAC, University of Cambridge, UK, 1949 中国科学技术大学 26
Computing Systems Today • The world is a large parallel system – Microprocessors in everything – Vast infrastructure behind them Internet Connectivity Gigabit Ethernet Clusters Scalable, Reliable, Secure Services Databases Information Collection Remote Storage Online Games Commerce … Refrigerators Sensor Nets Massive Cluster Cars MEMS for Sensor Nets 9/4/2021 Routers 中国科学技术大学 Robots 27
体系结构发展的驱动力 Applications suggest how to improve technology, provide revenue to fund development Applications Technology Com pat 9/4/2021 ibil i ty Improved technologies make new applications possible Cost of software development makes compatibility a major force in market 中国科学技术大学 28
Personal Mobile Devices 9/4/2021 New “Great Ideas” 中国科学技术大学 30
Old Machine Structures Application (ex: browser) Compiler Software Hardware Assembler Operating System (Mac OSX) Processor Memory I/O system Instruction Set Architecture Datapath & Control Digital Design Circuit Design transistors 9/4/2021 中国科学技术大学 31
New “Great Ideas” Software Hardware • Parallel Requests Assigned to computer e. g. , Search “Katz” • Parallel Threads Assigned to core e. g. , Lookup, Ads Warehouse Scale Computer Smart Phone Leverage Parallelism & Achieve High Performance • Parallel Instructions >1 instruction @ one time e. g. , 5 pipelined instructions • Parallel Data >1 data item @ one time e. g. , Add of 4 pairs of words • Hardware Descriptions Computer Core Memory Input/Output Instruction Unit(s) All gates functioning in parallel at same time • Programming Languages … Core Functional Unit(s) A 0+B 0 A 1+B 1 A 2+B 2 A 3+B 3 Cache Memory Logic Gates 9/4/2021 中国科学技术大学 32
Warehouse Scale Computer 9/4/2021 中国科学技术大学 33
计算机的分类 • 个人移动设备 (PMD) – smart phones, tablet computers – >1 billion sold/year – Market dominated by ARM-ISA-compatible general-purpose processor in system-on-a-chip (So. C) – Plus sea of custom accelerators (radio, image, video, graphics, audio, motion, location, security, etc. ) – Emphasis on energy efficiency and real-time • 桌面计算(Desktop Computing) – Emphasis on price-performance • 服务器(Servers) – Emphasis on availability, scalability, throughput 9/4/2021 中国科学技术大学 34
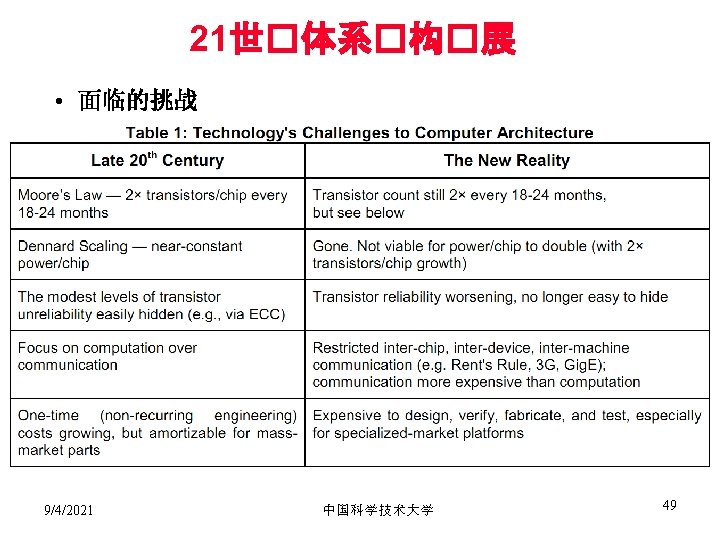
Cost of downtime Figure 1. 3 Costs rounded to nearest $100, 000 of an unavailable system are shown by analyzing the cost of downtime (in terms of immediately lost revenue), assuming three different levels of availability, and that downtime is distributed uniformly. These data are from Landstrom (2014) and were collected analyzed by Contingency Planning Research.
计算机的分类(续) • 集群/仓储级计算机(Clusters / Warehouse Scale Computers) – – 100, 000’s cores per warehouse Market dominated by x 86 -compatible server chips Dedicated apps, plus cloud hosting of virtual machines Starting to see some GPU usage, but mostly generalpurpose CPU code – Used for “Software as a Service (Saa. S)” – Sub-class: Supercomputers, emphasis: floating-point performance and fast internal networks – Emphasis on availability and price-performance • 嵌入式计算机(Embedded Computers) – Wired/wireless network infrastructure, printers – Consumer TV/Music/Games/Automotive/Camera/MP 3 – Emphasis: price 9/4/2021 中国科学技术大学 36
五�主流�算系�特点 Figure 1. 2 A summary of the five mainstream computing classes and their system characteristics. Sales in 2015 included about 1. 6 billion PMDs (90% cell phones), 275 million desktop PCs, and 15 million servers. The total number of embedded processors sold was nearly 19 billion. In total, 14. 8 billion ARM-technology-based chips were shipped in 2015. Note the wide range in system price for servers and embedded systems, which go from USB keys to network routers. For servers, this range arises from the need for very large-scale multiprocessor systems for high-end transaction processing.
Great Ideas in Computer Architecture 1. 2. 3. 4. 5. 6. 9/4/2021 Design for Moore’s Law Abstraction to Simplify Design Make the Common Case Fast Dependability via Redundancy Memory Hierarchy Performance via Parallelism/Pipelining/Prediction 中国科学技术大学 38
Moore’s Law • “Cramming More Components onto Integrated Circuits” – Gordon Moore, Electronics, 1965 • # on transistors on cost-effective integrated circuit double every 18 months 9/4/2021 中国科学技术大学 39 39
Abstraction via Layers of Representation temp = v[k]; v[k] = v[k+1]; v[k+1] = temp; High Level Language Program (e. g. , C) Compiler Assembly Language Program (e. g. , MIPS) lw lw sw sw Assembler Machine Language Program (MIPS) 0000 1010 1100 0101 Machine Interpretation $t 0, 0($2) Anything can be represented $t 1, 4($2) as a number, $t 1, 0($2) i. e. , data or instructions $t 0, 4($2) 1001 1111 0110 1000 1100 0101 1010 0000 0110 1000 1111 1001 1010 0000 0101 1100 1111 1000 0110 0101 1100 0000 1010 1000 0110 1001 1111 Hardware Architecture Description (e. g. , block diagrams) Architecture Implementation Logic Circuit Description (Circuit Schematic Diagrams) 9/4/2021 中国科学技术大学 40
Dependability via Redundancy • 通过冗余使得部分部件失效不影响整个系统的运行 1+1=2 2 of 3 agree 1+1=1 FAIL! Increasing transistor density reduces the cost of redundancy 9/4/2021 中国科学技术大学 42
Memory Hierarchy Fast, Expensive, but Small 9/4/2021 中国科学技术大学 Cheap, Large, 43 but Slow
Parallelism/Pipelining/Prediction 9/4/2021 中国科学技术大学 44
Growth in processor performance over 40 years Slowed down by power and memory latency Almost 10000 x improvement between 1978 and 2005 [ Hennessy & Patterson, 2017 ] 9/4/2021 中国科学技术大学 51
Closer Look at Processor Technology • 特征尺寸不断减小(feature size ( )),芯片集成度不断提高 – Circuits become faster – Die size is growing too – Clock rate also improves (but power dissipation is a problem) – Number of transistors improves like • 性能> 100× per decade – Clock rate is about 10× (no longer the case!) – DRAM size quadruples every 3 years • 如何使用这些晶体管? 9/4/2021 – Parallelism in processing: more functional units » Multiple operations per cycle reduces CPI 中国科学技术大学 Clocks Per Instruction 52
Moore’s Law • “Cramming More Components onto Integrated Circuits” – Gordon Moore, Electronics, 1965 • # on transistors on cost-effective integrated circuit double every 18 months 9/4/2021 中国科学技术大学 53
CPU Transistor Count (1971 – 2008) 10 -Core Xeon Westmere-EX introduced in 2011 has 2. 6 billion transistors and uses a 32 nm process on a die size = 512 mm 2 9/4/2021 中国科学技术大学 54
Storage Trends • 内存的容量和性能的提高差别较大 – Capacity increased by 1000 x from 1980 -95, speed only 2 x – Gigabit DRAM in 2008, but gap with processor speed is widening • 处理器与存储器之间的Gap在增大 – Need to transfer more data in parallel – Need cache hierarchies, but how to organize caches? • 存储系统需关注并行和局部性问题 – Fetch more bits in parallel – Pipelined transfer of data • 采用缓存和并行技术提高磁盘存储器的性能 to improve performance 中国科学技术大学 9/4/2021– Using parallel disks 55
Growth of Capacity per DRAM Chip v DRAM capacity quadrupled almost every 3 years 60% increase per year, for 20 years 9/4/2021 中国科学技术大学 56
Improvements in Disk Storage (1983 - 2003) • • • CDC Wren I, 1983 3600 RPM 0. 03 GBytes capacity Tracks/Inch: 800 Bits/Inch: 9550 Three 5. 25” platters • Bandwidth: 0. 6 MBytes/sec • Latency: 48. 3 ms • Cache: none 9/4/2021 • • • Seagate 373453, 2003 15000 RPM (4 X) 73. 4 GBytes (2500 X) Tracks/Inch: 64000 (80 X) Bits/Inch: 533, 000 (60 X) Four 2. 5” platters (in 3. 5” form factor) • Bandwidth: 86 MBytes/sec (143 X) • Latency: 5. 7 ms (8 X) • Cache: 8 MBytes 中国科学技术大学 57
Disk Latency vs. Bandwidth (~20 years) • Performance Milestones • Disk: 3600, 5400, 7200, 10000, 15000 RPM • Bandwidth improvement = 143 X • Latency Improvement = 8 X 9/4/2021 中国科学技术大学 58
Memory Latency vs Bandwidth (~20 years) • Performance Milestones • Memory Module: 16 bit plain DRAM, Page Mode DRAM, 32 b, 64 b, SDRAM, DDR SDRAM • Bandwidth Improvement = 120 X • Latency Improvement = 4 X 9/4/2021 中国科学技术大学 59
Network Latency vs Bandwidth (~20 years) • Performance Milestones • Ethernet: 10 Mb/s, 1000 Mb/s, 10000 Mb/s • Bandwidth Improvement = 1000 X • Latency Improvement = 16 X 9/4/2021 中国科学技术大学 60
Architectural Trends • 体系结构将技术的进步转化为系统能力和性能 的提升 • 主要解决并行性和局部性的权衡 – Current microprocessor: 1/3 compute, 1/3 cache, 1/3 off-chip connect – Tradeoffs may change with scale and technology advances • 基础元件经历了4代: tube, transistor, IC, VLSI – Here focus only on VLSI generation • VLSI的最大趋势是不断地挖掘并行性 9/4/2021 中国科学技术大学 61
Architecture: Increase in Parallelism • Bit level parallelism (before 1985) 4 -bit → 8 -bit → 16 -bit – Slows after 32 -bit processors – Adoption of 64 -bit in late 90 s, 128 -bit and beyond for vector processing – Great inflection point when 32 -bit processor and cache fit on a chip • Instruction Level Parallelism (ILP): Mid 80 s until late 90 s – Pipelining and simple instruction sets (RISC) + compiler advances – On-chip caches and functional units => superscalar execution – Greater sophistication: out of order execution and hardware speculation • Today: thread level parallelism and chip multiprocessors – Thread level parallelism goes beyond instruction level parallelism – Running multiple threads in parallel inside a processor chip – Fitting multiple processors and their interconnect on a single chip 9/4/2021 中国科学技术大学 62
How far will ILP go? Limited ILP under ideal superscalar execution: infinite resources and fetch bandwidth, perfect branch prediction and renaming, but real cache. At most 4 instruction issue per cycle 90% of the time. 9/4/2021 中国科学技术大学 63
Thread-Level Parallelism “on board” Proc MEM • Microprocessor is a building block for a multiprocessor – Makes it natural to connect many to shared memory • Faster processors saturate bus – Interconnection networks are used in larger scale 64 中国科学技术大学 9/4/2021 systems
Power & Energy 9/4/2021 中国科学技术大学 65
Power • Intel 80386 consumed ~ 2 W • 3. 3 GHz Intel Core i 7 consumes 130 W • Heat must be dissipated from 1. 5 x 1. 5 cm chip • This is the limit of what can be cooled by air 9/4/2021 中国科学技术大学 66
Limiting Force: Power Density 9/4/2021 中国科学技术大学 67
有关体系结构的新旧观念 • Old Conventional Wisdom: Power is free, Transistors expensive • New CW: “Power wall” Power expensive, Transistors free (Can put more on chip than can afford to turn on) • Old CW: 通过编译、体系结构创新来增加指令级并行 (Out-of-order, speculation, VLIW, …) • New CW: “ILP wall” 挖掘指令级并行的收益越来越小 • Old CW: 乘法器速度较慢,访存速度比较快 • New CW: “Memory wall” 乘法器速度提升了,访存成为瓶颈 (200 clock cycles to DRAM memory, 4 clocks for multiply) • Old CW: Uniprocessor performance 2 X / 1. 5 yrs • New CW: Power Wall + ILP Wall + Memory Wall = Brick Wall – Uniprocessor performance now 2 X / 5(? ) yrs Sea change in chip design: multiple “cores” (2 X processors per chip / ~ 2 years) 9/4/2021 » More, simpler processors are more power efficient 中国科学技术大学 68
Sea Change in Chip Design • Intel 4004 (1971): 4 -bit processor, 2312 transistors, 0. 4 MHz, 10 micron PMOS, 11 mm 2 chip • RISC II (1983): 32 -bit, 5 stage pipeline, 40, 760 transistors, 3 MHz, 3 micron NMOS, 60 mm 2 chip • 125 mm 2 chip, 0. 065 micron CMOS = 2312 RISC II+FPU+Icache+Dcache – RISC II shrinks to ~ 0. 02 mm 2 at 65 nm – Caches via DRAM or 1 transistor SRAM? • Processor is the new transistor? 9/4/2021 中国科学技术大学 69
• “We are dedicating all of our future product development to multicore designs. … This is a sea change in computing” Paul Otellini, President, Intel (2004) • Difference is all microprocessor companies have switched to multiprocessors (AMD, Intel, IBM, Sun; all new Apples 2+ CPUs) Procrastination penalized: 2 X sequential perf. / 5 yrs Biggest programming challenge: from 1 to 2 CPUs 9/4/2021 中国科学技术大学 70
Many. Core Chips: The future is here • Intel 80 -core multicore chip (Feb 2007) – – – 80 simple cores Two FP-engines / core Mesh-like network 100 million transistors 65 nm feature size • Intel Single-Chip Cloud Computer (August 2010) – 24 “tiles” with two IA cores per tile – 24 -router mesh network with 256 GB/s bisection bandwidth – 4 integrated DDR 3 memory controllers – Hardware support for message-passing • “Many. Core” refers to many processors/chip – 64? 128? Hard to say exact boundary • How to program these? – Use 2 CPUs for video/audio – Use 1 for word processor, 1 for browser – 76 for virus checking? ? ? 中国科学技术大学 9/4/2021 • Something new is clearly needed here… 71
The End of the Uniprocessor Era Single biggest change in the history of computing systems ——摘自 Berkeyley CS 252 9/4/2021 中国科学技术大学 72
03/05 -review • 计算机体系结构的基本概念 – ISA+Organization+Implementation • 计算机系统 – 个人移动设备 (PMD) Emphasis on energy efficiency and real-time – 桌面计算(Desktop Computing) Emphasis on price-performance – 服务器(Servers) Emphasis on availability, scalability, throughput – 集群/仓储级计算机(Clusters / Warehouse Scale Computers) Emphasis on availability and price-performance – 嵌入式计算机(Embedded Computers) Emphasis: price 9/4/2021 中国科学技术大学 74
03/05 -review • Great Ideas in Computer Architecture 1. Design for Moore’s Law 2. Abstraction to Simplify Design 3. Make the Common Case Fast 4. Dependability via Redundancy 5. Memory Hierarchy 6. Performance via Parallelism/Pipelining/Prediction • 体系结构设计面临的新问题 Power Wall + ILP Wall + Memory Wall = Brick Wall 9/4/2021 中国科学技术大学 75
Defining CPU Performance • X比Y性能高的含义是什么? • Ferrari vs. School Bus? • 2013 Ferrari 599 GTB – 2 passengers, 11. 1 secs in quarter mile • 2013 Type D school bus – 54 passengers, quarter mile time? http: //www. youtube. com/watch? v=Kwy. Co. Quh. UNA • 响应时间: e. g. , time to travel ¼ mile • 吞吐率/带宽: e. g. , passenger-mi in 1 hour 9/4/2021 中国科学技术大学 77
性能的两种含义 Plane DC to Paris Speed Passengers Throughput (pmph) Boeing 747 6. 5 hours 610 mph 470 286, 700 BAD/Sud Concorde 3 hours 1350 mph 132 178, 200 哪个性能高? • Time to do the task (Execution Time) – execution time, response time, latency • Tasks per day, hour, week, sec, ns. . . (Performance) – throughput, bandwidth 这两者经常会有冲突的。 9/4/2021 中国科学技术大学 78
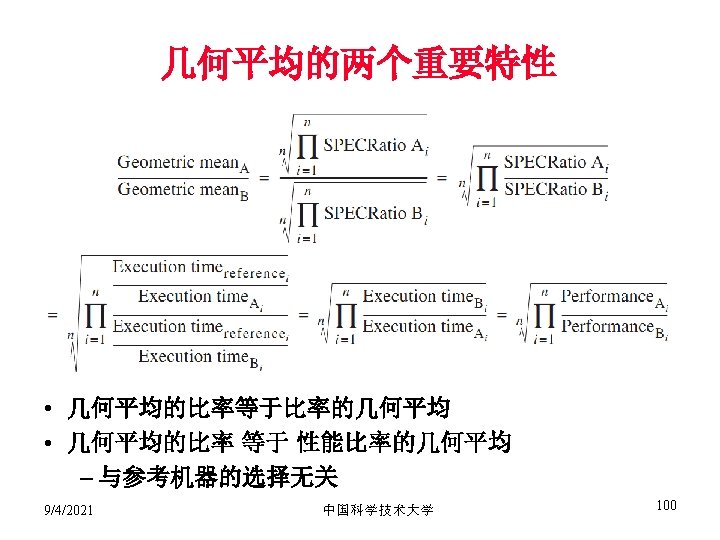
举例 • Time of Concord vs. Boeing 747? • Concord is 1350 mph / 610 mph = 2. 2 times faster = 6. 5 hours / 3 hours • Throughput of Concorde vs. Boeing 747 ? • Concord is 178, 200 pmph / 286, 700 pmph = 0. 62 “times faster” • Boeing is 286, 700 pmph / 178, 200 pmph = 1. 60 “times faster” • Boeing is 1. 6 times (“ 60%”) faster in terms of throughput • Concord is 2. 2 times (“ 120%”) faster in terms of flying time 我们主要关注单个任务的执行时间 程序由一组指令构成,指令的吞吐率(Instruction throughput)非常重要! 9/4/2021 中国科学技术大学 79
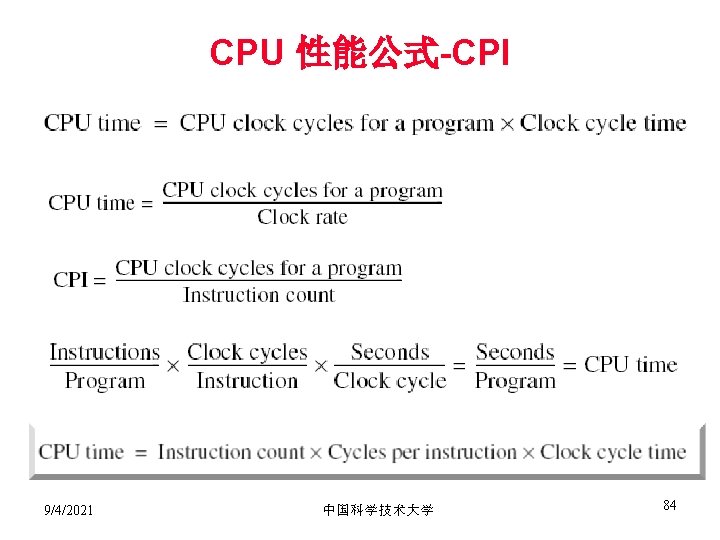
CPU性能度量 • Response time (elapsed time): 包括完成一个任务所需要的所有时间 • User CPU Time (90. 7) • System CPU Time (12. 9) • Elapsed Time (2: 39) 例如:unix 中的time命令 90. 7 s 12. 9 s 2: 39 9/4/2021 65% (90. 7/159) 中国科学技术大学 83
CPI计算举例 Base Machine (Reg / Reg) Op Freq CPIi*Fi ALU 50% 1. 5 Load 20% 2. 4 Store 10% 2. 2 Branch 20% 2. 4 1. 5 9/4/2021 中国科学技术大学 (% Time) (33%) (27%) (13%) (27%) 86
Program Inst Count X CPI (X) Compiler X X Inst. Set. X X Organization X Technology 9/4/2021 Clock Rate (X) X X 中国科学技术大学 87
XBOX One Theoretic vs. Real Performance 9/4/2021 中国科学技术大学 90
Computer Performance Name FLOPS yotta. FLOPS 1024 zetta. FLOPS 1021 exa. FLOPS 1018 peta. FLOPS 1015 tera. FLOPS 1012 giga. FLOPS 109 mega. FLOPS 106 kilo. FLOPS 103 9/4/2021 中国科学技术大学 93
基准测试程序套件 • Embedded Microprocessor Benchmark Consortium (EEMBC) • Desktop Benchmarks – – – SPEC 2017 SPEC 2006 SPEC 2000 SPEC 95 SPEC 92 SPEC 89 • Server Benchmarks – Processor Throughput-oriented benchmarks (基于SPEC CPU benchmarks ->SPECrate – SPECSFS, SPECWeb – Transaction-processing (TP) benchmarks (TPC-A, TPC-C, …) • …. . Standard Performance Evaluation Corporation (www. spec. org) 9/4/2021 中国科学技术大学 95
Figure 1. 17 SPEC 2017 programs and the evolution of the SPEC benchmarks over time, with integer programs above the line and floating-point programs below the line. Of the 10 SPEC 2017 integer programs, 5 are written in C, 4 in C++. , and 1 in Fortran. For the floating-point programs, the split is 3 in Fortran, 2 in C++, 2 in C, and 6 in mixed C, C++, and Fortran. The figure shows all 82 of the programs in the 1989, 1992, 1995, 2000, 2006, and 2017 releases. Gcc is the senior citizen of the group. Only 3 integer programs and 3 floating-point programs survived three or more generations. Although a few are carried over from generation to generation, the version of the program changes and either the input or the size of the benchmark is often expanded to increase its running time and to avoid perturbation in measurement or domination of the execution time by some factor other than CPU time. The benchmark descriptions on the left are for SPEC 2017 only and do not apply to earlier versions. Programs in the same row from different generations of SPEC are generally not related; for example, fpppp is not a CFD code like bwaves.
Figure 1. 18 Active benchmarks from SPEC as of 2017.
SPECfp 2000 Execution Times & SPEC Ratios 9/4/2021 中国科学技术大学 101
Power versus Energy • 功耗(Power) 指单位时间的能耗: 1 Watt = 1 Joule / Second • 一个任务执行的能耗 (energy) = Average Power × Execution Time • Power or Energy? 哪个指标更合适? – 针对给定的任务,能耗是一种更合适的度量指标(joules) – 针对电池供电的设备,我们需要关注能效 • Example: which processor is more energy efficient? – Processor A consumes 20% more power than B on a given task – However, A requires only 70% of the execution time needed by B • Answer: Energy consumption of A = 1. 2 × 0. 7 = 0. 84 of B – Processor A consumes less energy than B (more energy-efficient) 9/4/2021 中国科学技术大学 106
动态能耗和功耗 • 针对CMOS技术, 动态的能量消耗是由于晶体管的on和off 状态的切换引起的 • Dynamic Energy ∝ Capacitive Load × Voltage 2 – the energy of pulse of the logic transition of 0 -1 -0 or 1 -0 -1 – Capacitive Load = Capacitance of output transistors & wires – Voltage has dropped from 5 V to below 1 V in 20 years • Dynamic Power ∝ Capacitive Load × Voltage 2× Frequency Switched • 降低频率可以降低功耗 • 降低频率导致执行时间增加 ->不能降低能耗 • 降低电压可有效降低功耗和能耗 9/4/2021 中国科学技术大学 107
�例:��能耗和功耗 • Some microprocessors today have adjustable voltage and clock frequency. Assume 10% reduction in voltage and 15% reduction in frequency, what is the impact on dynamic energy and dynamic power? • Answer: – 10% reduction in Voltage ->Voltagenew= 0. 90 Voltageold – 15% reduction in Frequency ->Frequencynew= 0. 85 Frequencyold 9/4/2021 中国科学技术大学 108
Trends in Clock frequency • Intel 80386 consumed ~ 2 W • 3. 3 GHz Intel Core i 7 consumes 130 W • Heat must be dissipated from 1. 5 x 1. 5 cm chip • This is the limit of what can be cooled by air 9/4/2021 中国科学技术大学 109
Trends in Power & Clock Frequency 9/4/2021 中国科学技术大学 110
运算与访存部件的能耗及占用面积比较 Figure 1. 13 Comparison of the energy and die area of arithmetic operations and energy cost of accesses to SRAM and DRAM. [Azizi][Dally]. Area is for TSMC 45 nm technology node. 9/4/2021 中国科学技术大学 111
低功耗技� -DVFS Figure 1. 12 Energy savings for a server using an AMD Opteron microprocessor, 8 GB of DRAM, and one ATA disk. At 1. 8 GHz, the server can handle at most up to two-thirds of the workload without causing service-level violations, and at 1 GHz, it can safely handle only one-third of the workload (Figure 5. 11 in Barroso and Hölzle, 2009).
静�功耗( Static Power) • 当晶体管处于off状态时, 漏电流的流动产生的功耗称为静 态功耗 • 随着晶体管尺寸的减少漏电流的大小在增加 • Static Power = Static Current × Voltage – Static power increases with the number of transistors • 静态功耗有时会占到全部功耗的50% – Large SRAM caches need static power to maintain their values • Power Gating: 通过切断供电减少漏电流 – To inactive modules to control the loss of leakage current 9/4/2021 中国科学技术大学 114
与能效相关的其他指� • EDP (Energy Delay Product) EDP = Energy ∗ Delay = Power ∗ Delay 2 • Performance per Power – FLOPS per watt ( Scientific computing) • SWa. P (space, wattage and performance) – Sun Microsystems metric for data centers, incorporating energy and space. – SWa. P = Performance / (Space ∗ Power) 9/4/2021 中国科学技术大学 116
本章小� • 设计发展趋势 Capacity Speed Logic 2 x in 3 years DRAM 4 x in 3 years 2 x in 10 years Disk 4 x in 3 years 2 x in 10 years • 运行任务的时间 – Execution time, response time, latency • 单位时间内完成的任务数 – Throughput, bandwidth • “X性能是Y的n倍 ” : Ex. Time(Y) ----Ex. Time(X) 9/4/2021 = Performance(X) -------Performance(Y) 中国科学技术大学 117
本章小� (�) • Amdahl’s 定律: Speedupoverall = Ex. Timeold Ex. Timenew 1 = (1 - Fractionenhanced) + Fractionenhanced Speedupenhanced • CPI Law: CPU time = Seconds Program = Instructions x Program Cycles x Seconds Instruction Cycle • 执行时间是计算机系统度量的最实际,最可靠的方式 9/4/2021 中国科学技术大学 118
Acknowledgements • These slides contain material developed and copyright by: – John Kubiatowicz (UCB) – Krste Asanovic (UCB) – David Patterson (UCB) – Chenxi Zhang (Tongji) • UCB material derived from course CS 152、 CS 252、CS 61 C • KFUPM material derived from course COE 501、 COE 502 9/4/2021 中国科学技术大学 119
Example • Suppose we have two implementations of the same ISA • For a given program – Machine A has a clock cycle time of 250 ps and a CPI of 2. 0 – Machine B has a clock cycle time of 500 ps and a CPI of 1. 2 • Which machine is faster for this program, and by how much? 9/4/2021 中国科学技术大学 136
• Problem: A compiler designer is trying to decide between two code sequences for a particular machine. Based on the hardware implementation, there are three different classes of instructions: class A, class B, and class C, and they require one, two, and three cycles per instruction, respectively. – The first code sequence has 5 instructions: 2 of A, 1 of B, and 2 of C – The second sequence has 6 instructions: 4 of A, 1 of B, and 1 of C • Compute the CPU cycles for each sequence. Which sequence is faster? • What is the CPI for each sequence 9/4/2021 中国科学技术大学 137