Web Based Information Retrieval System II Definition of

Web – Based Information Retrieval System

II. Definition of Terms § World Wide Web or Web - a massive collection of web pages stored on the millions of computers across the world that are linked by the internet § Online - refers to a computer or user currently connected to a network or to the Internet. Online is often used to refer to resources available on the Internet

The Web § § § The Web § No design/co-ordination Distributed content creation, linking Content includes truth, lies, obsolete information, contradictions … Structured (databases), semi-structured … Scale larger than previous text corpora … (now, corporate records) Growth – slowed down from initial “volume doubling every few months” Content can be dynamically generated
 § Tim Berners-Lee and")
II. History of the Web § Vannevaar Bush-envisioned Hypertext (1940) § Tim Berners-Lee and his collegues at CERN-created a protocol called HTTP (hyper text transfer protocol) which is a standardized communication between servers and clients

III. Complexities of the Web 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. Distributed nature of the web There is no uniform standard used for the creation and processing of the web information resources Size and growth of the web Deep vs the surface web Type and format of the documents Quality of the information Frequency Ownership Distributed users Multiple Languages Resource requirements

IV. Traditional vs Web IR “Volume of Use”

Web Information: volume and growth Distribution of websites from 1998 to 2002 Growth in the number Distribution of public of websites from website by country of 1998 -2002 origin in 2002 Distribution of public website by language in 2002 1998 1999 2000 2001 2002 1998 -9 1999 2000 2001 2002 English German Japanese Spanish French Italian Dutch Chinese Korean Portuguese Russian Polish 2, 851, 000 4, 882, 000 7, 399, 000 8, 745, 000 9, 040, 000 71% 52% 18% 3% 217% US Germany Japan UK Canada Italy France Netherlands Others Unknown 55% 6% 5% 3% 3% 2% 2% 2% 18% 4% 72% 7% 6% 3% 3% 2% 2% 2% 1% 1%

As of 2003 Google is reported to be as the largest search engines having indexed 3. 8 billion web pages, and until today… In spite of this…

Categories: Information in the web can be categorized into two classes: • • Web Search Tools Activating the appropriate program from a particular web page Deep Web - part of the web that is hidden and cannot be easily accessed Surface Web - can be easily accessed

Web tools for Information Retrieval 1. Web browser - a computer program essential for getting access to the web URL ( Uniform Resource Locator ) or the web address e. g Netscape Navigator, Microsoft Internet Explorer Capabilities: a) knows how to go to a web server on the internet and request a page b) knows how to interpret the set of HTML tags

2. Search engines - allows users to enter search terms such as keywords/ phrases -retrieves from its database web pages that match the search terms entered by the user 3. Web Directories or “Link Directory” - is a directory on the www which specializes in linking to other websites and categorizing links. - not a search engine, does not display lists of webpages based on keywords - often allow site owners to directly submit their site for inclusion RSS directories are similar to web directories, but contain collections of RSS feeds, instead of links to web sites.

Search Engines: How it works § They search or select parts of the internet according to a set of criteria § They keep an index of the words or phrases they find, with specific information such as where they found them, how many times they found them. § They allow users to search for words or phrases or combinations of words or phrases found in that index

Three Main Components § Spider - a program that automatically fetches web pages for search engines; crawls over the web. § Search engine software and interface - information retrieval program that performs two major tasks - searches through millions of terms recorded in the index to find matches to a search and it ranks the retrieved records (web pages) to the most relevant. § Index
 § § § § § Web Crawling A URL")
Crawling and Indexing process (Google) § § § § § Web Crawling A URL server sends lists of URLs to be fetched to the crawlers The web pages that are fetched are sent to the store server which compresses and stores the web pages into a repository Every web page has an associated ID number called a doc. ID which is assigned whenever a new URL is parsed out of a web The indexing function is performed by the indexer and the sorter The indexer reads the repository, uncompresses the documents, and parses them Each document is converted into a set of word occurences called hits. The hits record the word, position the document, an approximation of the font size and capitalization The indexer distributes these hits into a set of barrels, creating a partially sorted forward index The indexer also parses out all the links in every web page and stores important information about them in an anchor file

7 Categories of Search engines A. Major Search Engines B. News search engines C. Speciality search engines D. Kid’s search engines E. Metacrawlers F. Multimedia search engines G. Regional and country search engines

B. News search engines

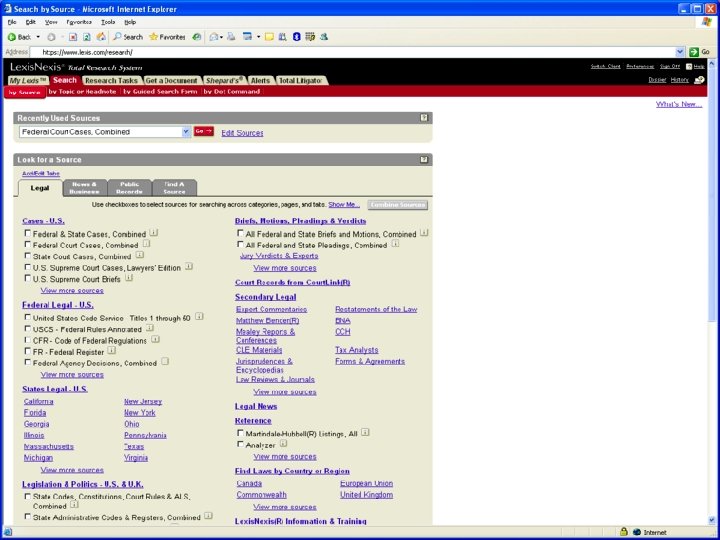
Lexis. Nexis claims to be the "world’s largest collection of public records, unpublished opinions, forms, legal, news, and business information" while offering their products to a wide range of professionals in the legal, risk management, corporate, government, law enforcement, accounting and academic markets.

C. Speciality Search engines

D. Kids’ search engines

E. Metacrawlers

F. Multimedia search engines

G. Regional and Country Search engines
 1. Search engines 2. Meta search engines -tools")
Types of Search Engines (by model) 1. Search engines 2. Meta search engines -tools that allow users to conduct concurrent searches on more than one search engine -Search engines that automatically submit your keyword search to several other search tools, and retrieve results from all their databases. Convenient time-savers for relatively simple keyword searches (one or two keywords or phrases in " "). 3. Open source search engines 4. Social search engines 5. Personal search engines 6. Visual search engines 7. Desktop search engines - the name for the field of search tools which search the contents of a user's own computer files, rather than searching the Internet. These tools are designed to find information on the user's PC, including web browser histories, e-mail archives, text documents, sound files, images and video. 8. Usenet - Bulletinboard-like network featuring thousands of "newsgroups. " Google incorporates the historic file of ``Usenet Newsgroups (back to 1981) into its Google Groups. Yahoo Groups offers a similar service, but does not include the old "Usenet Newsgroups. " Blogs are replacing some of the need for this type of community sharing and information exchange.

Open Source Search engines § Open source search engines allow participants to make changes and contribute to the improvement of the software. § They are generally free and use the GPL or other open source licensing schemes. § In most cases, anyone can use the software on a site or incorporate it in a product, but must share improvements and additional functionality with the other source users. § Note that these search engines generally require all options to be set using command lines or configuration files, rather than interactive browser-based graphic interfaces. Changes are often done on the server, requiring root access and passwords.

Sphinx is a full-text search engine, distributed under GPL version 2. Commercial license is also available for embedded use. Generally, it's a standalone search engine, meant to provide fast, size-efficient and relevant fulltext search functions to other applications. Sphinx was specially designed to integrate well with SQL databases and scripting languages. Currently built-in data sources support fetching data either via direct connection to My. SQL or Postgre. SQL, or using XML pipe mechanism (a pipe to indexer in special XML-based format which Sphinx recognizes). As for the name, Sphinx is an acronym which is officially decoded as SQL Phrase Index. Yes, I know about CMU's Sphinx project.

Social Search engines § Social search or a social search engine is a type of web search method that determines the relevance of search results by considering the interactions or contributions of users. When applied to web search this user-based approach to relevance is in contrast to established algorithmic or machine-based approaches where relevance is determined by analyzing the text of each document or the link structure of the documents. § Social search takes many forms, ranging from simple shared bookmarks or tagging of content with descriptive labels to more sophisticated approaches that combine human intelligence with computer algorithms. § The Search experience revolve around the outcome of collaborative harvesting, collaborative directories, tag engines, social ranking, commenting on bookmarks, news, images, videos, podcasts and other web pages. Example forms of user input include social bookmarking or direct interaction with the search results such as promoting or demoting results the user feels are more or less relevant to their query.

Personal Search Engines

Desktop Search Engines Apple Inc's Spotlight is an example of a desktop search tool.

X 1 Technologies' X 1 Professional Client is an example of a desktop search tool for Windows.

- Slides: 64