We go Way Back Libraries Community Web Archiving

We go Way Back: Libraries & Community Web Archiving Presenters: Jacquelyn Oshman - New Brunswick Free Public Library Diana Bowers-Smith - Brooklyn Public Library

Jacquelyn Oshman ● ● Senior Librarian at New Brunswick Free Public Library Started in 2005 Specialize in Local History and Genealogy / Interlibrary Loan No prior experience with Web Archiving

Diana Bowers-Smith ● Archivist at Brooklyn Public Library since 2015 ● Primarily works with the Brooklyn Collection, BPL’s local history division ● No prior web archiving experience

What is Web Archiving? Web Archiving is the process of Evaluating, selecting, collecting, cataloging, providing access to, and preserving digital materials for researchers today and in the future. Source: Library of Congress https: //www. loc. gov/webarchiving/

Why should we save websites? How much room do you have for your vertical file or clipping collection? How old is the most recent article in those collections? How thin is your local daily newspaper getting? Do you find most of your local Reference answers on the computer? How many community churches/organizations/non-profits have a website but not a newsletter? Do you have a large foreign-language speaking population that you would like to reach out to?



Community Webs Grant ● 2 year IMLS and Internet Archive funded program to provide education, applied training, cohort support, and web archiving services for public librarians to develop expertise in web archiving. ● 10 Libraries were originally funded by IMLS and 17 more were added with Kahle/Austin Foundation and Internet Archive funds ● Together, the group will save 35 terabytes of web based community heritage materials for longterm access ● New Brunswick Free Public Library is the only New Jersey library in the cohort, but not the smallest!

Cohort Members Athens Regional Library System, GA; Birmingham Public Library, AL; Brooklyn Public Library – Brooklyn Collection, NY; Buffalo & Erie County Public Library, NY; Cleveland Public Library, OH; Columbus Metropolitan Library, OH; County of Los Angeles Public Library, CA. ; DC Public Library Washington, DC; Denver Public Library, CO; East Baton Rouge Parish Library, LA. ; Forbes Library, MA. ; Grand Rapids Public Library, MI. ; Henderson District Public Libraries, NV. ; Kansas City Public Library, MO. ; Lawrence Public Library, KS. ; Marshall Lyon County Library, MN. ; New Brunswick Free Public Library, NJ. ; Schomburg Center for Research in Black Culture (NYPL), NY. ; Patagonia Library, AZ. ; Pollard Memorial Library, MA. ; Queens Library, NY. ; San Diego Public Library, CA. ; San Francisco Public Library, CA. ; Sonoma County Public Library, CA. ; The Urbana Free Library, IL. ; West Hartford Public Library, CT. ; Westborough Public Library, MA. (bold denotes “lead libraries”)

Challenges to Web Archiving

Terminology used on a daily basis Seed - The starting point URL for a crawler and access point to archived collections. Crawl - A web archiving (or "capture") operation that is conducted by an automated agent, called a crawler, a robot, or a spider. Scope - What the crawler will capture and what it won’t - can be expanded or limited Robots. txt - Files that a site owner can add to their site to keep crawlers from accessing all or parts of it. Collection - A group of Seed URLs curated around a common theme, topic, or domain. Patch Crawl - A crawl to capture and patch in documents that may have been missing from your original crawl. https: //support. archive-it. org/hc/en-us/articles/208111686 -Glossary-of-Archive-It-and-Web-Archiving-Terms

Getting Administration on board ● Convincing your board and director that Web Archiving is worth using ● Should you create an entirely new policy or add to your Collection Development policy? ● Creating guidelines for what you will be saving and how it fits with your policy ● Teaching administrators the difference between digital born content and email ● Getting good publicity so the community is aware of the project and onboard to suggest sites

Permissions ● Include asking for permission in policy? ● Do you think it is necessary to ask permission for open websites? ● Ethical Implications? ● Intellectual Property Rights? All this can be negated by a “Take Down Policy’ ● Favored by most Librarians in cohort ● Add the content, and when asked, be willing to remove it (at least publicly)

Learning to Crawl…. ● Be Patient ● Very few will succeed on their first try, or maybe even their second ● Pay attention to details ● The results may be disappointing ● Get help from the experts

Problems we have encountered with crawls ● Forgetting to “Test Crawl” first can result in incomplete pages and a waste of space ● Files are too large ● Test Crawls “Not in Archive” because of robots. txt, Scoping problems, time limits, not waiting the required 24 hours before trying to view results, Browsers showing incomplete pages
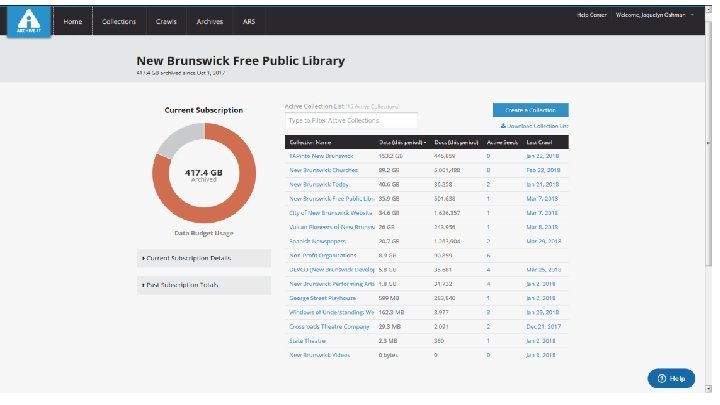
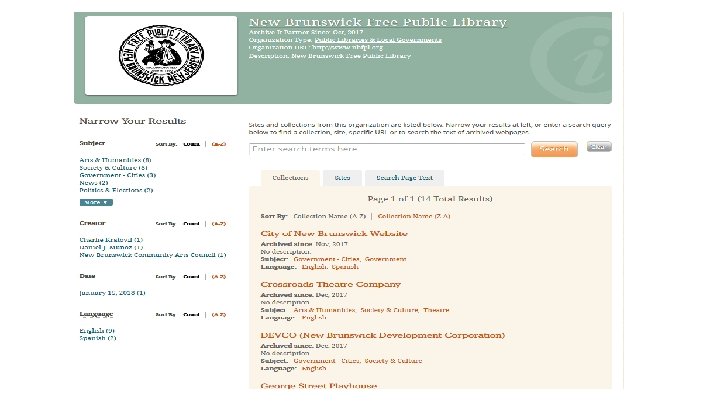
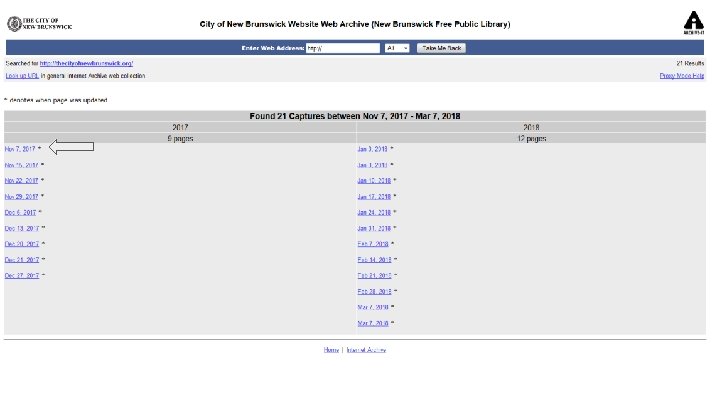
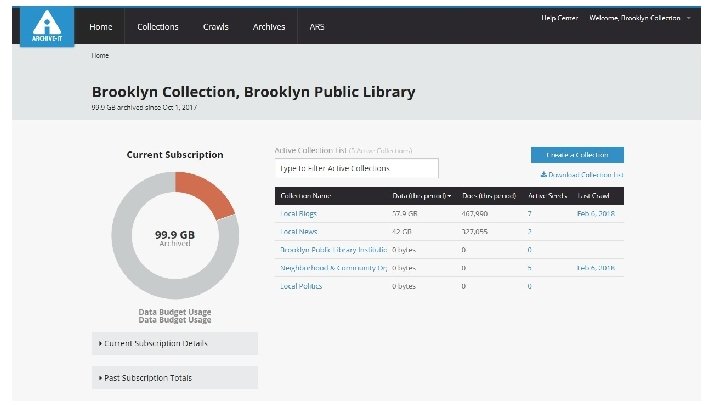
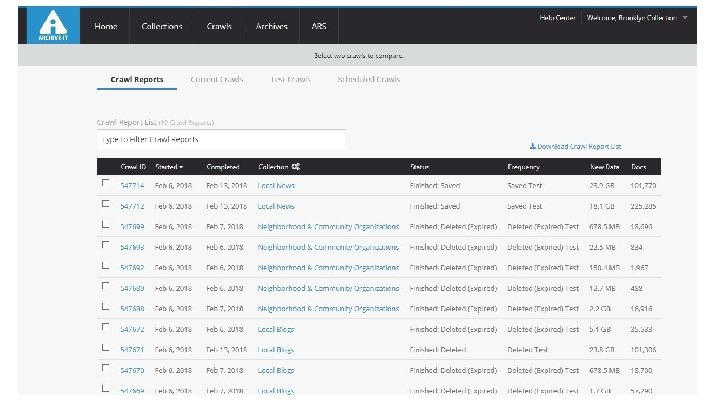

How do I get involved with Web Archiving? ● “Archive-It is a subscription service of the Internet Archive. Subscriptions to AIT are paid annually and amounts vary depending on scope of collecting a new partner is looking to do. Our smallest account level is 3 K/year, however we are somewhat flexible with pricing for smaller institutions who want to start WA programs so anyone interested should reach out!” - Maria Praetzellis ● Manually add URLs to the Wayback Machine ● Web Recorder

Thank you! Any Questions?
- Slides: 25