void combine 4vecptr v int dest int i

 { int i;")
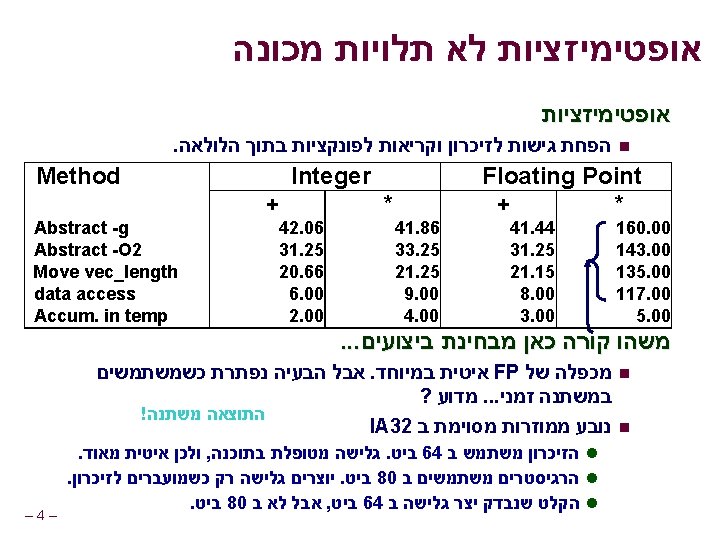
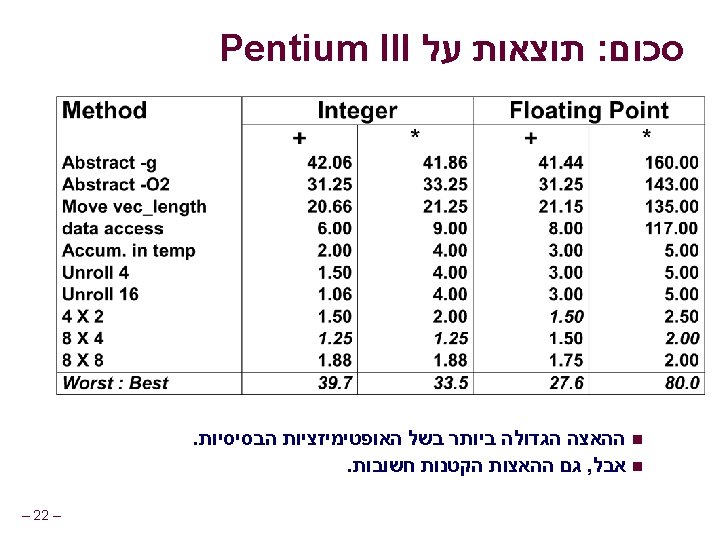
. . . עד עתה void combine 4(vec_ptr v, int *dest) { int i; int length = vec_length(v); int *data = get_vec_start(v); int sum = 0; for (i = 0; i < length; i++) sum += data[i]; *dest = sum; } המטרה חשב את סכום איברי הוקטור n Vector represented by C-style abstract data type Achieved CPE of 2. 00 CPE = Cycles per element l – 2– n n
 { int")
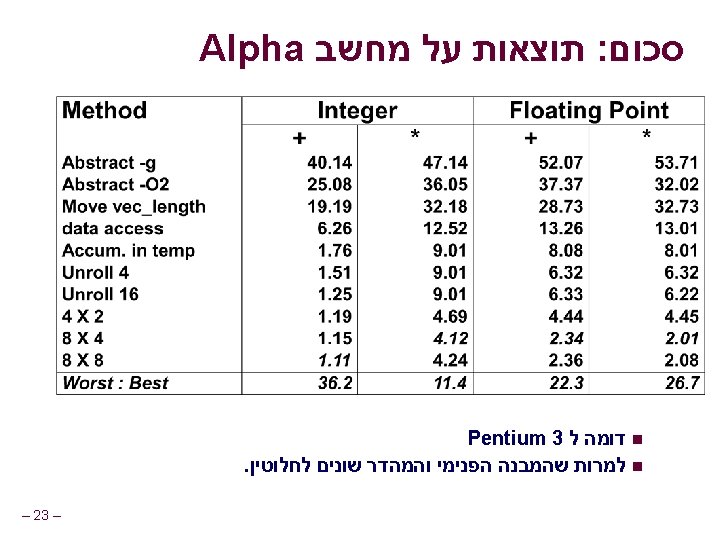
נהפוך את הקוד ליותר כללי void abstract_combine 4(vec_ptr v, data_t *dest) { int i; int length = vec_length(v); data_t *data = get_vec_start(v); data_t t = IDENT; for (i = 0; i < length; i++) t = t OP data[i]; *dest = t; } טיפוסים נשתמש בהגדרות שונות data_t בשביל int l float l double l – 3– n פעולות נשתמש בהגדרות שונות IDENT ו OP בשביל n + / 0 n * / 1 n

 \" מבנה של מעבד \"מודרני Instruction Control Fetch Control Retirement Unit Register")
(Pentium III) " מבנה של מעבד "מודרני Instruction Control Fetch Control Retirement Unit Register File Address Instrs. Instruction Decode Instruction Cache Control Unit (CU) Operations Register Updates Prediction OK? Integer/ Branch General Integer FP Add Operation Results FP Mult/Div Load Addr. Store Addr. Data Cache Execution – 6– Functional Units Data Arithmetic Logic Unit (ALU)

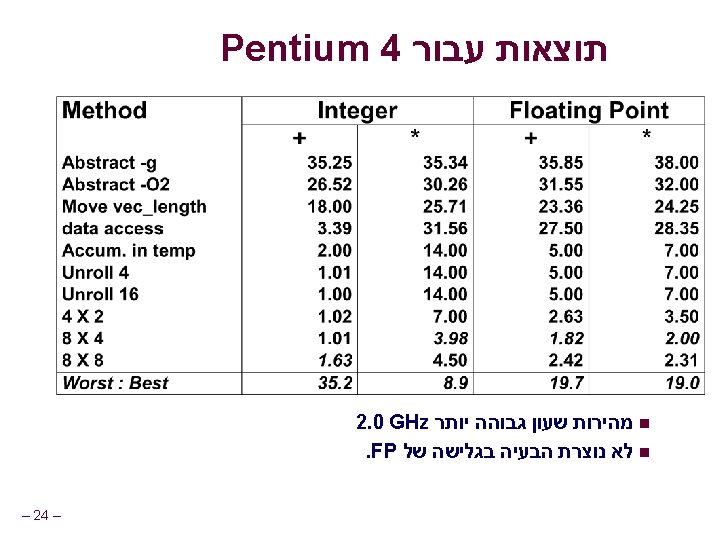
Pentium III היכולות של : ניתן להריץ במקביל n 1 load 1 store n 2 integer (one may be branch) n 1 FP Addition n 1 FP Multiplication or Division n חלקים שונים של אותה פקודה מבוצעים על ידי לכן ניתן. רכיבים שונים לבצע מספר רכיבים של . פקודות שונות בו זמנית Some Instructions take > 1 cycle, but can be pipelined n Instruction n Load / Store Integer add Integer Multiply Integer Divide Double/Single FP Multiply Double/Single FP Add 3 1 4 36 5 3 1 1 1 36 2 1 Double/Single FP Divide 38 38 n n n – 7 –n ( )משך Latency Cycles/Issue

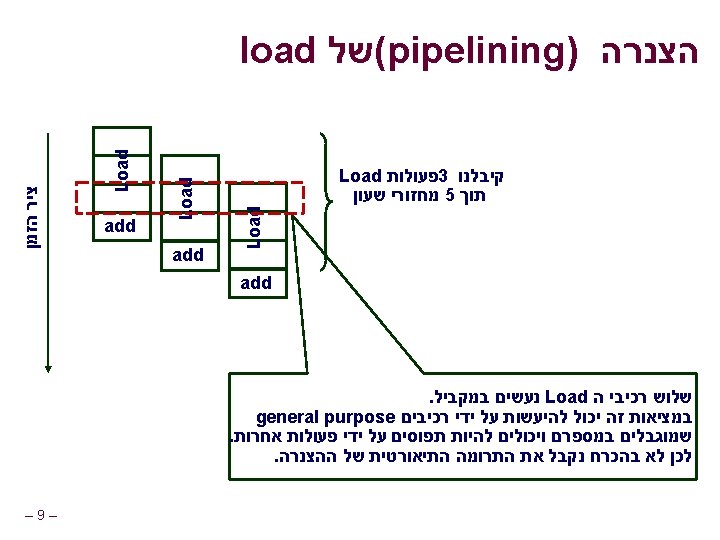
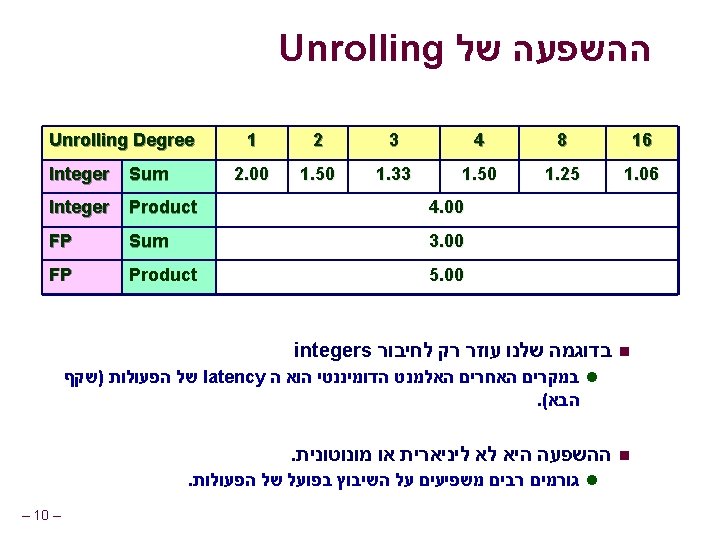
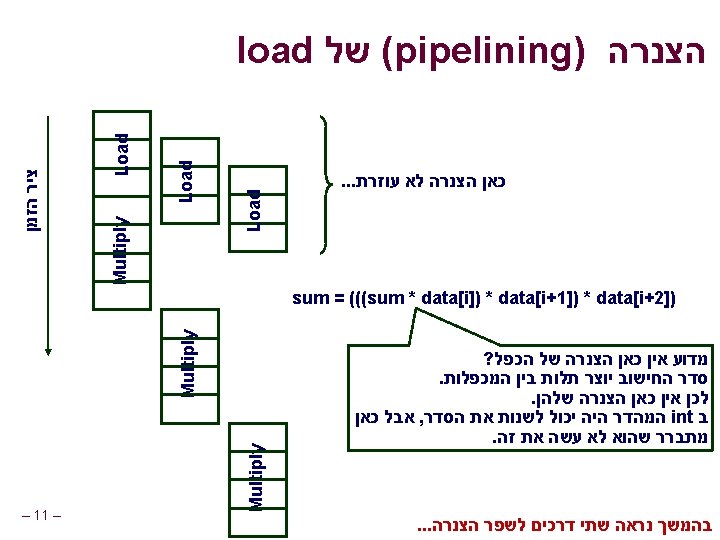
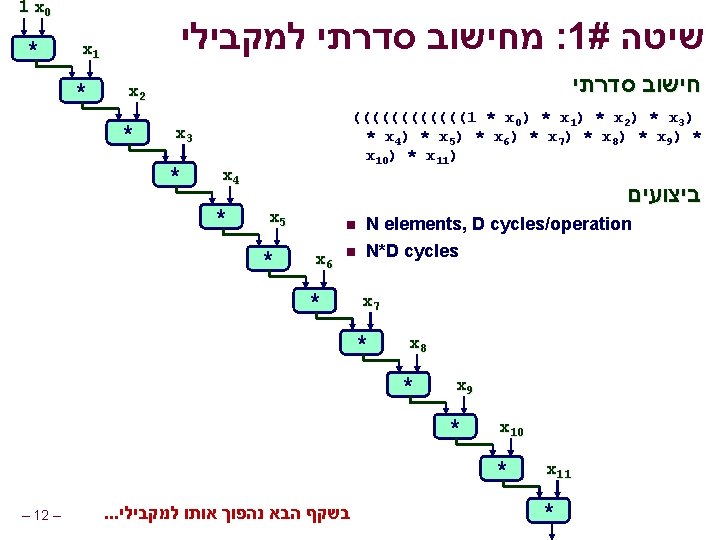

פרישת לולאות מקבילית : אופטימיזציה. 6 Parallel Loop Unrolling void combine 6(vec_ptr v, int *dest) { int length = vec_length(v); int limit = length-1; int *data = get_vec_start(v); int x 0 = 1; int x 1 = 1; int i; /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x 0 *= data[i]; x 1 *= data[i+1]; } /* Finish any remaining elements */ for (; i < length; i++) { x 0 *= data[i]; } *dest = x 0 * x 1; } – 13 – הכפלת שלמים : גרסה : אופטימיזציה סכום בשתי מכפלות בלתי n. תלויות . ניתן לביצוע במקביל l . הכפל אותם בסוף n : ביצועים CPE = 2. 0 המהירות הוכפלה )עבור n (int מכפלת n
 * x 2)")
חישוב שתי מכפלות במקביל : חישוב ((((((1 * x 0) * x 2) * x 4) * x 6) * x 8) * x 10) * ((((((1 * x 1) * x 3) * x 5) * x 7) * x 9) * x 11) : ביצועים 1 x 0 * 1 x 1 * x 2 * n n * x 4 * n x 3 x 5 * x 6 * N elements, D cycles/operation (N/2+1)*D cycles ~2 X performance improvement x 7 * x 8 * x 10 x 9 * * – 14 – x 11



Optimization Results for Combining – 17 –
 { int length")
Parallel Unrolling 2# שיטה void combine 6 aa(vec_ptr v, int *dest) { int length = vec_length(v); int limit = length-1; int *data = get_vec_start(v); int x = 1; int i; /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x *= (data[i] * data[i+1]); } /* Finish any remaining elements */ for (; i < length; i++) { x *= data[i]; } *dest = x; } – 18 – הכפלת שלמים : גירסת קוד אופטימיזציה ואז עדכן , הכפל זוגות n. והשלם תוצאה “Tree height reduction” n Performance n CPE = 2. 5
) * (x 2")
2# שיטה : חישוב ((((((1 * (x 0 * x 1)) * (x 2 * x 3)) * (x 4 * x 5)) * (x 6 * x 7)) * (x 8 * x 9)) * (x 10 * x 11)) x 0 x 1 1 : ביצועים * x 2 x 3 * n n * x 4 x 5 * l CPE = 2. 0 * x 6 x 7 * n Measured CPE worse * x 8 x 9 * * x 10 x 11 * * * – 19 – N elements, D cycles/operation Should be (N/2+1)*D cycles Unrolling 2 CPE (measured) (theoretical) 2. 50 2. 00 3 1. 67 1. 33 4 1. 50 1. 00 6 1. 78 1. 00

מקביליות /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x = (x * data[i]) * data[i+1]; } CPE = 4. 00 מכפלות מבוצעות באופן סדרתי n n /* Combine 2 elements at a time */ for (i = 0; i < limit; i+=2) { x = x * (data[i] * data[i+1]); } CPE = 2. 50 במקביל - חלק מהמכפלות – 20 – n n במקביל ל data[2]*data[3] x * (data[0]*data[1])


![(#1) לעתים ניתן להימנע מהסתעפויות. 7 int sum(int[] a) { int res. M =](http://slidetodoc.com/presentation_image_h/b945fb0932e888f4b33473fe99c4a2cb/image-26.jpg "(#1) לעתים ניתן להימנע מהסתעפויות. 7 int sum(int[] a) { int res. M =")
(#1) לעתים ניתן להימנע מהסתעפויות. 7 int sum(int[] a) { int res. M = 1, res. A = 0; for (int i = 0; i < 1000; ++i) { if (i % 2) res. M *= a[i]; else res. A += a[i]; } return res. M + res. A; } int sum(int[] a) { int res. M = 1, res. A = 0; for (int i = 1; i < 1000; i += 2) res. M *= a[i]; for (int i = 0; i < 1000; i += 2) res. A += a[i]; } – 26 – return res. M + res. A;



- Slides: 29