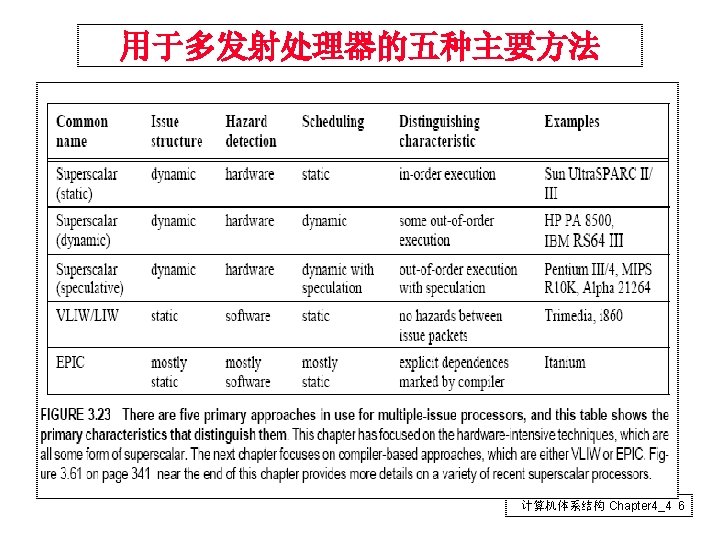
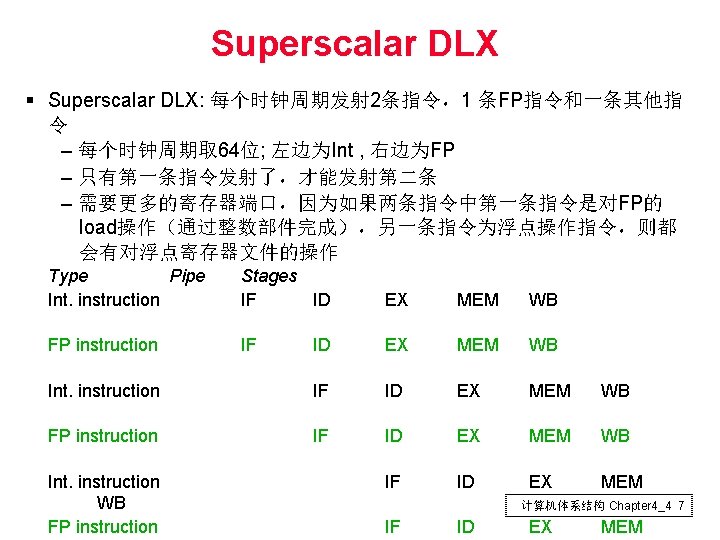
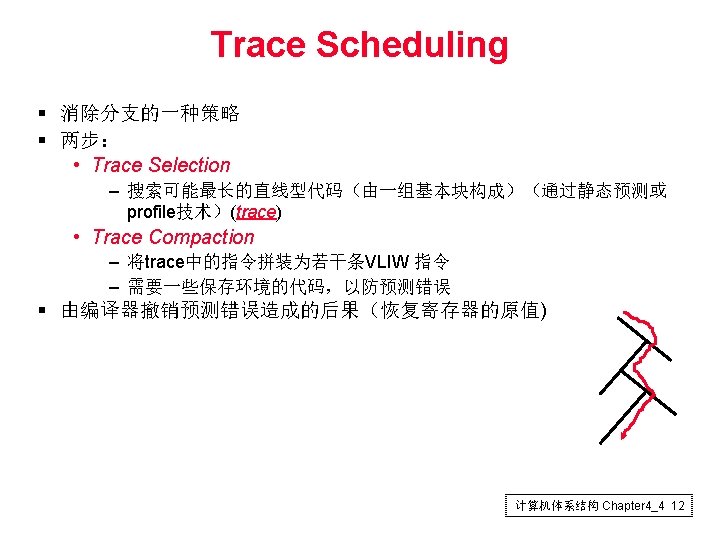
VLIW Superscalar xhzhouustc edu cn Chapter 44 1






 LD F 6, -8(R 1)")

 LD")









- Slides: 22
多指令流出技术: VLIW 和Superscalar简介 周学海 xhzhou@ustc. edu. cn 计算机体系结构 Chapter 4_4 1
Review #1/2 § Reservations stations: 寄存器重命名,缓冲源操作数 • 避免寄存器成为瓶颈 • 避免了Scoreboard中无法解决的 WAR, WAW hazards • 允许硬件做循环展开 • 不限于基本块(IU先行,解决控制相关) § 贡献 • Dynamic scheduling • Register renaming • Load/store disambiguation § 360/91 后 Pentium II; Power. PC 604; MIPS R 10000; HP-PA 8000; Alpha 21264使用这种技术 计算机体系结构 Chapter 4_4 2
Review: 具有最小stalls数的循环展开优化 1 Loop: 2 3 4 5 6 7 8 9 10 11 12 13 14 LD LD ADDD SD SD SUBI SD BNEZ SD F 0, 0(R 1) F 6, -8(R 1) F 10, -16(R 1) F 14, -24(R 1) F 4, F 0, F 2 F 8, F 6, F 2 F 12, F 10, F 2 F 16, F 14, F 2 0(R 1), F 4 -8(R 1), F 8 R 1, #32 16(R 1), F 12 R 1, LOOP 8(R 1), F 16 LD to ADDD: 1 Cycle ADDD to SD: 2 Cycles ; 8 -32 = -24 14 clock cycles, or 3. 5 per iteration 计算机体系结构 Chapter 4_4 8
采用Superscalar技术的循环展开 Loop: Integer instruction LD F 0, 0(R 1) LD F 6, -8(R 1) LD F 10, -16(R 1) LD F 14, -24(R 1) LD F 18, -32(R 1) SD 0(R 1), F 4 SD -8(R 1), F 8 SD -16(R 1), F 12 SD -24(R 1), F 16 SUBI R 1, #40 BNEZ R 1, LOOP SD +8(R 1), F 20 FP instruction 1 2 ADDD F 4, F 0, F 2 ADDD F 8, F 6, F 2 ADDD F 12, F 10, F 2 ADDD F 16, F 14, F 2 ADDD F 20, F 18, F 2 8 9 10 11 12 Clock cycle 3 4 5 6 7 § 循环展开5次以消除延时 (+1 due to SS) § 12 clocks, or 2. 4 clocks per iteration (1. 5 X) 计算机体系结构 Chapter 4_4 9
基于VLIW的循环展开 Memory FP FP reference 1 reference 2 LD F 0, 0(R 1) LD F 10, -16(R 1) LD F 18, -32(R 1) 3 LD F 26, -48(R 1) SD 0(R 1), F 4 SD -16(R 1), F 12 SD 16(R 1), F 20 SD -0(R 1), F 28 LD F 6, -8(R 1) LD F 14, -24(R 1) LD F 22, -40(R 1) Int. op/ Clock operation 1 ADDD F 4, F 0, F 2 op. 2 branch 1 2 ADDD F 8, F 6, F 2 ADDD F 12, F 10, F 2 ADDD F 16, F 14, F 2 4 ADDD F 20, F 18, F 2 ADDD F 24, F 22, F 2 5 SD -8(R 1), F 8 ADDD F 28, F 26, F 2 SD -24(R 1), F 16 SUBI R 1, #48 SD 8(R 1), F 24 8 BNEZ R 1, LOOP 9 6 7 Unrolled 7 times to avoid delays 7 results in 9 clocks, or 1. 3 clocks per iteration (1. 8 X) Average: 2. 5 ops per clock, 50% efficiency 注: 在VLIW中,一条超长指令有更多的读写寄存器操作(15 vs. 6 in SS) 计算机体系结构 Chapter 4_4 11
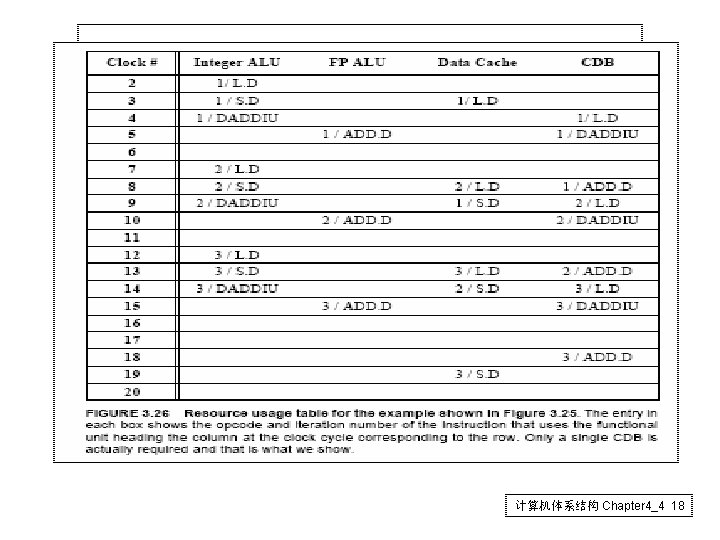
Performance of Dynamic SS 计算机体系结构 Chapter 4_4 17