VLIW l ILP InstructionLevel Parallelism l Superscalar Oo

")




")





















")


- Slides: 43
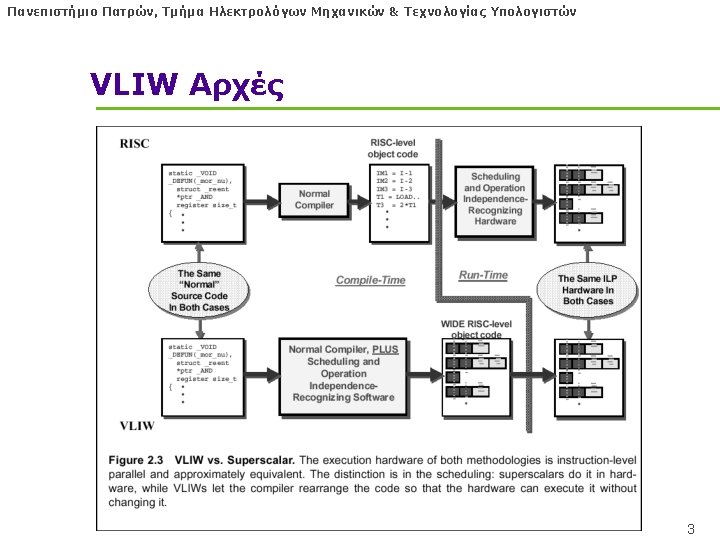
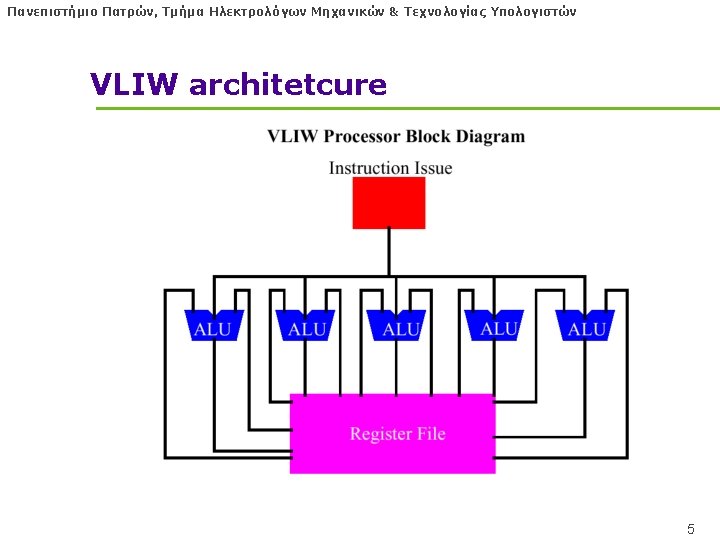
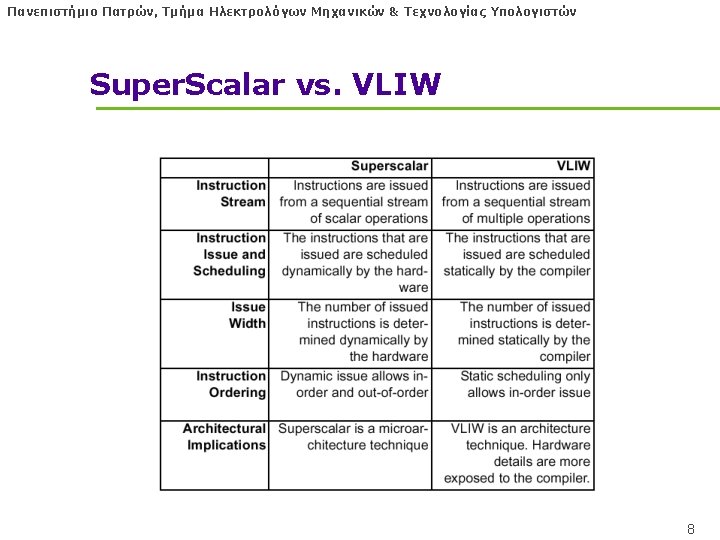
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών VLIW Αρχές l ILP (Instruction-Level Parallelism) l Superscalar, Oo. O: hardware finds it l VLIW: let the Software, COMPILER, find it! • No need for DYNAMIC EXECUTION — Register renaming out — Reservation Stations out — Reorder Buffer out — Out-of-order issue out 2
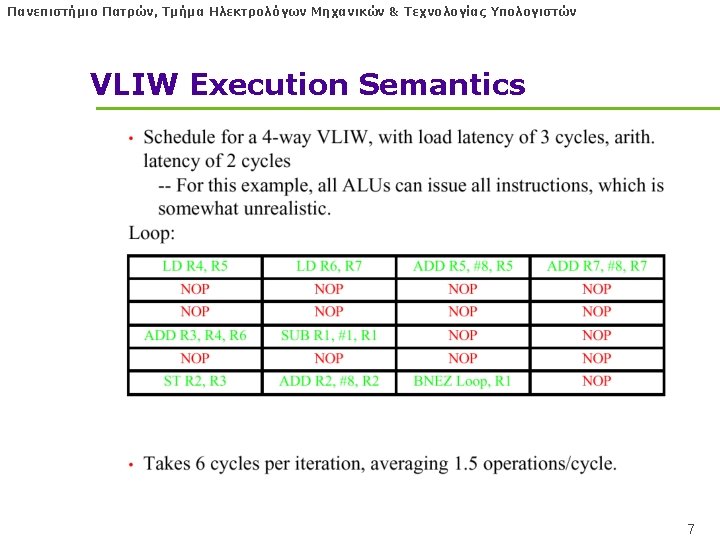
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών VLIW execution semantics l UAL: Unit-assumed Latencies • All latencies eq. • New instr. issues after previous completes — Always finds results ready l NUAL: Non-Uniform Assumed Latencies • Latencies of operations non-unit • New instr. issues immediately, but ops may still be in progress • Instructions must be scheduled when their results are ready (no interlocks)! 9
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών VLIW execution semantics l NUAL: Non-Uniform Assumed Latencies l Two models: • Equals (EQ) Model: Each operation takes exactly its specified latency. Register values don’t change until operation completes. Example: TI C 6 x • Less-Than-or-Equals (LEQ): Operations may take up to their specified latency 10
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών VLIW execution semantics l Equals (EQ) Model • Reduces register pressure because source operands stay around longer. • Can’t reduce operation latencies and maintain source code compatibility. l Less-Than-or-Equals (LEQ): • Destination register contents become unreliable immediately • Can reduce operation latencies and maintain source code compatibility 11
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Προβλήματα VLIW l Compiler δεμένος με implementation l Scheduler must know operation latencies l Cannot run binaries in another implementation l Dynamically scheduled VLIW • Αποσύνδεση operation latencies από τον compiler 12
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Dynamically Scheduled VLIW l Compatibility problem: compiler must know latencies l Schedule with assumed latencies l Delay buffer inserted between FUs and register file, holds register updates and presents to the code the “assumed” latencies not the real latencies (similar to LEQ) l Scoreboard dynamically schedules VLIW instructions according to dependencies l VERY SIMILAR to Oo. O but simpler 13
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Role of COMPILER in VLIW l Find parallelism -- schedule independent instructions • Find independent operations to create VLIW • Many available registers to reduce false data dependencies l INCREASE ILP (create parallelism) • Loop unrolling • Software Pipelining • Trace scheduling • Predication 14
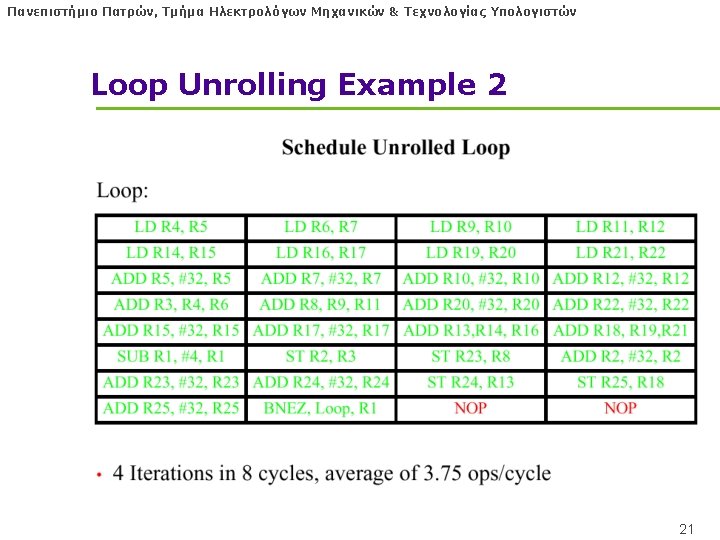
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Loop Unrolling l Basic Idea: Unroll loops to get loop with fewer but longer iterations l Pros: • Creates parallelism -- instructions from different original iterations can be issued in parallel • Latency Tolerance -- can issue instructions from one iteration while waiting for instructions from another to complete • Reduces overhead -- fewer iterations means fewer compares and branches 15
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Loop Unrolling l Cons: • Register pressure -- combining multiple iterations means more • live values, potential for register overflow. l REQUIRES MANY ARCHITECTURAL REGISTERS • INTEL’s EPIC (ITANIUM) Arch has 128 registers!!! 16
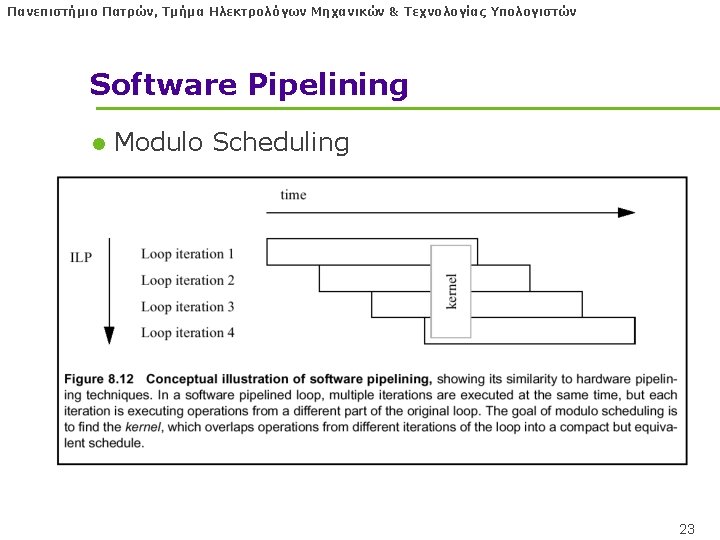
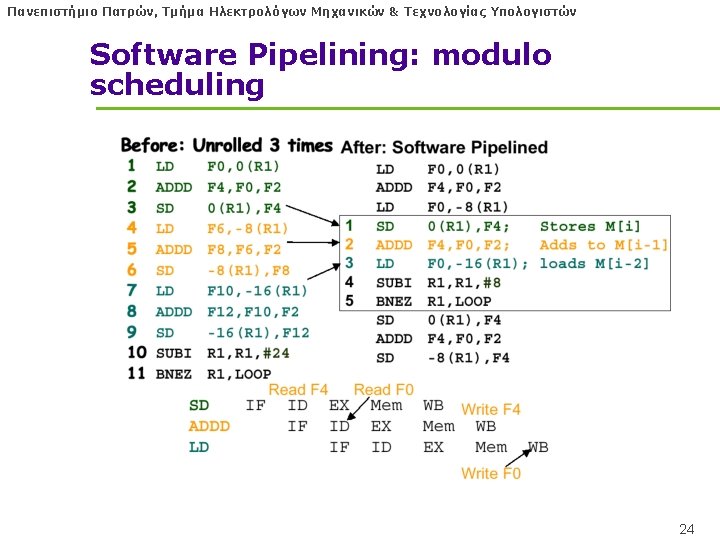
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Software pipelining l Idea: Transform loop which performs one iteration at a time into loop which performs pipelined steps of different iterations. • Scheduling: Increase time between dependent instructions l Combines well with loop unrolling 22
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Comparison to Superscalar l Loop Unrolling + Software pipelining = Register Renaming + Multiple branch prediction (loop branch) + Dynamic Scheduling 25
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών COMPILER: Reduce CONTROL dependencies l 1 in 5 instructions is a branch l 5 -op VLIW ? Each VLI contains a branch! — Unacceptable. . . l INCREASE STRAIGHT LINE CODE • code without branches l 2 Techniques in addition to loop unrolling: • TRACE SCHEDULING • PREDICATION 26
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών TRACE SCHEDULING l Parallelism across IF branches vs. LOOP branches l Compiler Support - Two steps: l Trace Selection • Find likely sequence of basic blocks (trace) of (statically predicted) long sequence of straight-line code l Trace Compaction • Squeeze trace into few VLIW instructions • Need bookkeeping code in case prediction is wrong 27
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Trace Scheduling • Similar to branch prediction in Super. Scalar Oo. O • When things go wrong: execute fix-up code (undo wrong path). Compiler inserts all necessary code. 28
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών PREDICATION l Avoid branch prediction by turning branches into conditionally executed instructions: l if (x) then A = B op C else NOP • If false, then neither store result nor cause exception • Expanded ISA of Alpha, MIPS, Power. PC, SPARC have conditional move; PA-RISC can annul any following instruction. l Drawbacks to conditional instructions • Complex conditions reduce effectiveness; • Cannot predicate very large blocks 29
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Intel/HP EPIC l Intel/HP IA-64 “Explicitly Parallel Instruction Computer (EPIC)” l IA-64: instruction set architecture; EPIC is type l EPIC = 2 nd generation VLIW? l Itanium™ is name of first implementation (2001) 31
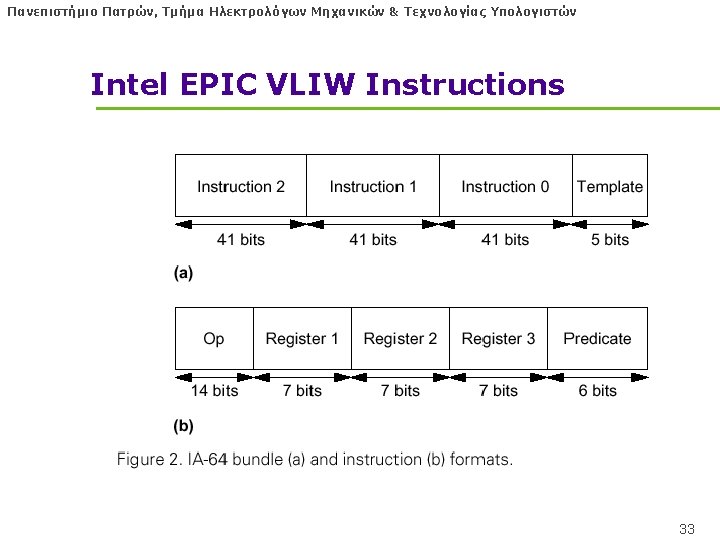
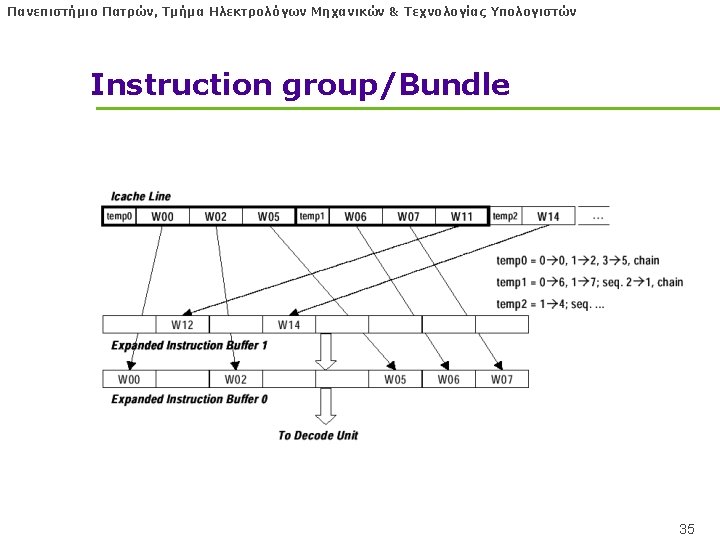
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Intel EPIC VLIW Instructions l IA-64 instructions are encoded in bundles, which are 128 bits wide. • Each bundle consists of a 5 -bit template field and 3 instructions, each 41 bits in length l 3 Instructions in 128 bit “groups”; field determines if instructions dependent or independent • Smaller code size than old VLIW, larger than x 86/RISC • Groups can be linked to show independence > 3 instr 32
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Intel IA-64 VLIW Instruction groups l Instruction group: a sequence of consecutive instructions with no register data dependences • All the instructions in a group could be executed in parallel, if sufficient hardware resources existed and if any dependencies through memory were preserved • An instruction group can be arbitrarily long, but the compiler must explicitly indicate the boundary between one instruction group and another by placing a stop between 2 instructions that belong to different groups 36
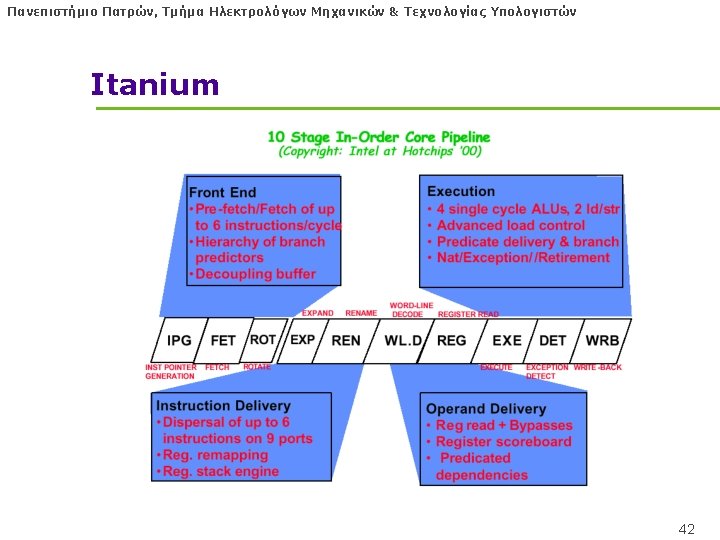
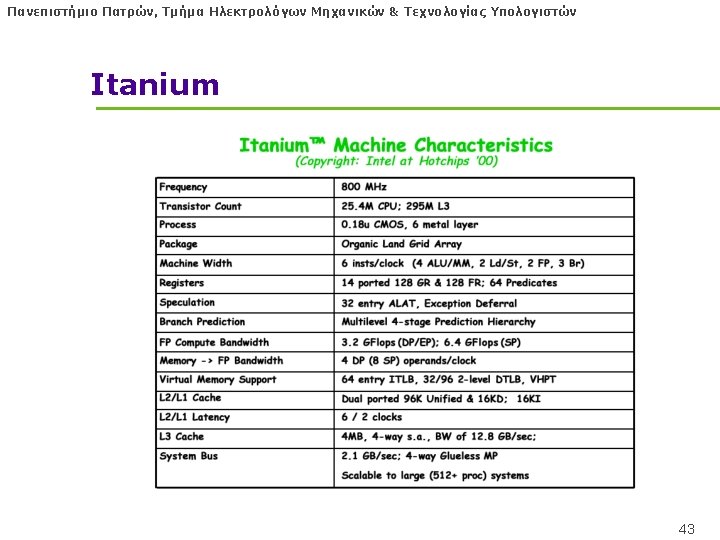
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Itanium (or Itanic as in Titanic) l Highly parallel and deeply pipelined hardware at 800 Mhz (2000) l 6 -wide, 10 -stage pipeline at 800 Mhz on 0. 18 µ process l Hardware checks dependencies (interlocks => binary compatibility over time) l DYNAMICALLY SCHEDULED VLIW l Predicated execution (select 1 out of 64 1 -bit flags) => 40% fewer mispredictions? 38
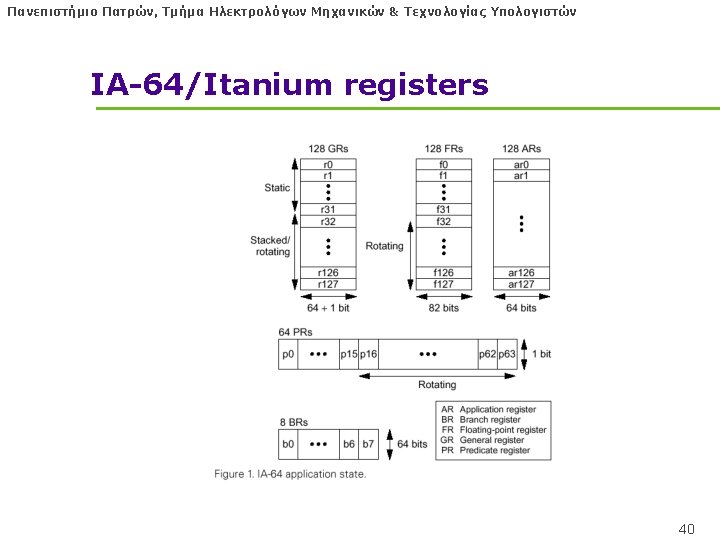
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Itanium l IA-64 Registers l The integer registers are configured to help accelerate procedure calls using a register stack l 8 64 -bit Branch registers used to hold branch destination addresses for indirect branches l 64 1 -bit predication registers 39
Πανεπιστήμιο Πατρών, Τμήμα Ηλεκτρολόγων Μηχανικών & Τεχνολογίας Υπολογιστών Itanium l Both the integer and floating point registers support register rotation for registers 32 -128. l Register rotation is designed to ease the task of allocating of registers in software pipelined loops l When combined with predication, possible to avoid the need for unrolling and for separate prologue and epilogue code for a software pipelined loop l Makes the SW-pipelining usable for loops with smaller numbers of iterations 41