Variansanalyse p normalfordelte observationer af Jens Friis Ensidig

Variansanalyse på normalfordelte observationer af Jens Friis

Ensidig variansanalyse Model enkelt normalfordelt observationsrække Lad X 1, X 2, ……Xn er indbyrdes uafhængige N(μ, σ2) - fordelt stokastiske variable. Det tilhørende observationssæt kaldes x 1, x 2, ……xn Estimater Kvadratsumsopspaltning SSD f SSD 1 n-1 SSD 2 1 SSD n

Hypotesen med H 0 : μ = μ 0 H 1 : μ ≠ μ 0 ønskes testet. Teststørrelsen bliver Det ses, at er en stokastisk variabel, og derfor er t ikke normalfordelt. Man kan vise, at er σ2χ2 - fordelt med f=n-1 frihedsgrader. Testoren t følger en såkaldt t-fordeling med f=n-1 frihedsgrader. t-fordelingen konvergere mod N(0, 1) – fordelingen for n gående mod uendelig. t-fordelingens tæthedsfunktion er også symmetrisk om 0. Hypotesen accepteres hvis Tf-1(α/2) ≤ t ≤ Tf-1(1 -α/2) , hvor Tf er fordelingdfunktionen svarende til t-fordelingen med f frihedsgrader.

Eksempel: Ved produktion af piller har man målt nicotamid-indholdet i 20 piller. Indholdet skal være 25 mg. Ved stikprøven på 20 piller fik man følgende resultater: 22, 67 23, 29 23, 40 23, 56 23, 76 23, 83 23, 95 24, 21 24, 50 24, 64 24, 87 25, 05 25, 35 25, 73 25, 79 25, 80 26, 11 26, 97 25, 36 27, 11 Model : Xi N(μ, σ2) for i=1 til 20 er uafhængige stokastiske variable. H 0 : μ = 25 , Parametrene estimeres = 24, 797 H 1 : μ ≠ 25 ; s 2 = 1, 5187 Teststørrelsen bliver Da 2, 5%’s fraktilen er -2, 093 for 19 frihedsgrader, accepters hypotesen.

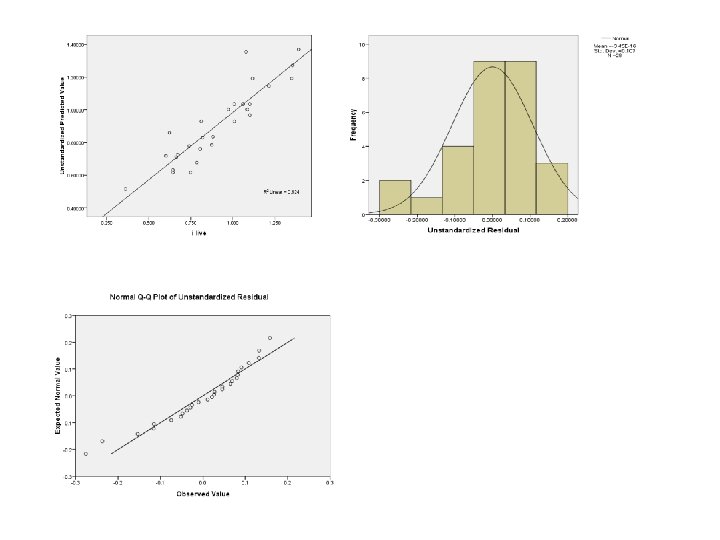
Anvendelse af SPSS til analysen: Først undersøges om observationssættet kan anses for normalfordelt. Man får et såkaldt Q-Q plots Det accepteres at observationssættet er normalfordelt.

Herefter testes hypotesen : klik Analyze → Compare Means → One-Sample T test Vælg Test Value til 25 Hypotesen accepteres

Simpel lineær regression Antag at Yi for i = 1 til k er uafhængige N(μi, σ2) -fordelte således at Man kan vise at estimaterne for parametrene er Bemærk at skæring med y-aksen er Man kan også vise, at estimatoren for β er - fordelt. Man kan derfor teste hypotesen H 0 : β = β 0 med teststørrelsen som er t-fordelt med k-2 frihedsgrader under H 0. Hvis β 0 = 0 tester man uafhængighed af x og y værdierne.

Kvadratsumsopspaltning : SSD f Omkring linje SSD 1 n-2 linje SSD 2 1 total SSD n-1 Som test for H 0 : β = 0 an også anvendes som er F(1, n-2) fordelt.

Eksempel : Man for 28 patienter målt kreatininindholdet i blodet før og efter dødens indtræden. Er der en sammenhæng? Dataene kan ses i en excelfil. Der er en pæn lineær sammenhæng og parametrene estimeres. Man vil gerne teste hypotesen H 0 : β = 1 som er t-fordelt med 26 frihedsgrader. Da 97, 5%’s fraktilen er 2, 056 accepteres hypotesen. Dataene er analyseret vha. SPSS : kreatinin. sav

Analyse vha. SPSS Først undersøges det om der er en lineær sammenhæng: Dette accepteres.

Parametrene estimeres: Klik Analyze →Regrssion→Linear s 2 Skæring med y-aksen og Testet for H 0 : β = 1 bliver Spredningen på , som det blev vist tidligere.

Yderligere modelkontrol : Man bør undersøge residuerne, dvs. afvigelserne fra modellen Klik Analyze→Regression→Linear→Save og flueben som vist Optegn de forventede mod de observerede y-værdier mod hinanden og nogle passende plots af residuerne.

Model flere normalfordelte observationsrækker Lad Xij , i=1, 2…k, j=1, 2…ni være indbyrdes uafhængige N(μi, σ2) - fordelt stokastiske variable. Det tilhørende observationssæt kaldes xij , i=1, 2…k, j=1, 2…ni, og lad Estimater Modelkontrol Det forudsættes at for hver i er observationsrækken normalfordelt, og at der er tale om varianshomogenitet for de k observationsrækker dvs. for , i=1, 2…. k Man kan benytte et Barletts test eller et Levene test ( er tilgængeligt i SPSS).

Følgende hypotese ønskes testet: H 0 : μi = μ , i = 1, 2…k (samme middelværdi i de k observationsrækker) Kvadratsumsopspaltning : SSD f Inden for grupper SSD 0 n-k Mellem grupper SSD 1 k-1 Total SSD n-1 Teststørrelsen for H 0 er , som er F(k-1, n-k) fordelt. Store værdier er kritiske. Hvis H 0 accepteres er estimaterne følgende:

Eksempel To titreringsmetoder anvendes. Det ønskes undersøgt om de giver samme resultat: T 1 T 2 Det skal først undersøges om de to observationsrækker kan 76, 35 76, 23 anses for normalfordelte, og i bekræftende fald om der er 76, 33 76, 30 varianshomogenitet. Dataene organiseres som liste i SPSS: 76, 45 76, 33 nr. Tnr 76, 40 76, 33 Antag at dataene er normalfordelte. 1 76, 35 76, 68 76, 28 Klik Analyze → Compare Means → 1 76, 33 76, 45 One-way Anova : 1 76, 45 76, 40 76, 38 1 76, 40 76, 28 76, 43 osv. 76, 58 76, 45 76, 60 76, 40 77, 03 76, 80 76, 95 74, 83 74, 88 75, 25
 fordelt accepters")
Man får Da teststørrelsen er 0, 014 og den er F(1, 28) fordelt accepters hypotesen om varianshomogenitet. s 12 SSD 1 SSD 0 SSD s 02 Test-størrelsen. H 0 accepters ( ingen forskel på de to titreringsmetoder).

Tosidig variansanalyse Model : ~ i= 1, 2…. r ; j=1, 2…. s ; k=1, 2…. t ; n=rst I første omgang skal man undersøge om der er varianshomogenitet i de rs observationsrækker. Denne hypotese kaldes H 0 (arbejdshypotese). Derefter er der flere hypoteser, som man kan opstille. H 1 : . Dvs. en rækkeeffekt plus en søjleeffekt. H 2 : Dvs. ingen rækkeeffekt. H 2 * : Dvs. ingen søjleeffekt. H 3 : Dvs. samme fordeling i de rs observationsrækker (fuldstændig homogenitet). Der er valgt en normering således at og .

Man kan vise, at estimaterne for middelværdiparametrene under H 1 er : Under H 0 er estimatet for σ2 : SSD 0/f 0 ( se næste side) Under H 1 er estimatet for σ2 : (SSD 0+SSD 1)/(f 0+f 1 )
 Vekselvirkning SSD 1 f")
Kvadratsumsopspaltning: SSD f Inden for grupper SSD 0 f 0=rs(t-1) Vekselvirkning SSD 1 f 1=(r-1)(t-1) Rækkevirkning SSD 2 f 2=r-1 Søjlevirkning SSD 2* f 2*=t-1 Total SSD f=rst-1

Test: H 1 : aditivitet som er fordelt. H 2 : ingen rækkevirkning som er fordelt. H 3 : fuldstændig homogenitet (heller ingen søjlevirkning ) som er fordelt. Man kan også vælge at teste for ingen søjlevirkning først. Der skal så byttes rundt på SSD 2 og SSD 2* og deres frihedsgrader i de to test. Hver gang man har accepteret en hypotese, er ændres estimatet for variansen. Hvis fx H 2 accepteres er Estimatet for variansen (SSD 0+SSD 1+SSD 2)/(f 0+f 1+f 2)

Eks. Man har testet et byggemateriale for vandgennemtrængning, målt i sekunder. Man har derpå taget logaritmen til tiden. Byggematerialet blev produceret på 3 forskellige maskiner 9 forskellige dage med 3 målinger pr. dag: Først skal man lave en modelkontrol. Da der kun er tre observationer pr. dag , er det ikke muligt at lave dag maskine 1 maskine 2 maskine 3 1 1, 404 1, 306 1, 932 en fornuftig kontrol af, om der er tale om normalfordelte 1, 346 1, 628 1, 674 1, 618 1, 410 1, 399 observationer pr. maskine x dag. Derimod kan man 2 1, 447 1, 241 1, 426 1, 569 1, 185 1, 768 estimer variansen pr. maskine x dag, og teste om der er 1, 820 1, 516 1, 859 3 1, 914 1, 506 1, 382 varianshomogenitet. Dette gøres med enten et Bartletts 1, 477 1, 575 1, 690 1, 894 1, 649 1, 361 test eller Levene. I SPSS er det muligt, at foretage et 4 1, 887 1, 673 1, 721 Levene test. For at benytte SPSS skal dataene organiseres 1, 485 1, 372 1, 528 1, 392 1, 114 1, 371 som en lang liste : 5 1, 772 1, 227 1, 320 1, 728 1, 397 1, 489 dag maskine måling 1, 545 1, 531 1, 336 6 1, 665 1, 404 1, 633 1 1 1, 404 1, 539 1, 452 1, 612 1, 680 1, 627 1, 359 1 1 1, 346 7 1, 918 1, 229 1, 328 1, 931 1, 508 1, 802 1 1 1, 618 2, 129 1, 436 1, 385 8 1, 845 1, 583 1, 689 1 2 1, 306 1, 790 1, 627 2, 248 2, 042 1, 282 1, 795 1 2 1, 628 9 1, 540 1, 636 1, 703 1, 428 1, 067 1, 370 1 2 1, 410 1, 704 1, 384 1, 839 1 3 1, 932 1 3 1, 674 1 3 1, 399 osv. 2 1 1, 447

Dette kan gøres samtidigt med den tosidige variansanalyse i SPSS: Klik Analyze → Generel Linear Model → Univariate og udfyld som vist. Teststørrelsen er F(26, 54) fordelt. Testet er dobbeltsidigt og ikke signifikant her. Grafisk modelkontrol for additivitet : Der afsættes punkterne som skal ligge omkring en ret linje med hældningskoefficienten 1.
 og t=3 Er test for")
Herefter selve variansanalysen: Her er r=9 , s=3(antal maskiner) og t=3 Er test for H 2, men s 22/so 2 SSD 1 SSD 0 Test for H 1 accept. SSD

Tosidig variansanalyse med forskelligt antal observationer pr. celle Model : ~ i= 1, 2…. r ; j=1, 2…. s ; k=1, 2…. nij ; n= Alt er stort set som før. Man får følgende kvadratsumopspaltning. SSD f Inden for grupper SSD 0 f 0=n-rs Vekselvirkning SSD 1 f 1=(r-1)(t-1) Rækkevirkning SSD 2 f 2=r-1 Søjlevirkning SSD 2* f 2*=t-1 Total SSD f=n-1

Lineær regression med flere observationer pr. x Antag at Yij for i = 1 til k , j=1 til ni er uafhængige N(μij, σ2) -fordelte således at Man kan vise at estimaterne for parametrene er Bemærk at Bemærk igen at skæring med y-aksen er Man kan også vise, at estimatoren for β er - fordelt. Man kan derfor teste hypotesen H 2 : β = β 0 med teststørrelsen som er t-fordelt med f 0+1 frihedsgrader under H 0. Hvis β 0 = 0 tester man uafhængighed af x og y værdierne. Vedr. s 012 se følgende.

Kvadratsumsopspaltning : SSD f Inden for grupper SSD 0 f 0=n-k Omkring linjen SSD 1 f 1=k-2 Regressionslinjen SSD 2 f 2=1 Total SSD f=n-1 Testet for H 1 : lineær regression er som er F(k-2, n-k) fordelt. Bemærk, at hvis H 1 accepteres er estimatet for variansen s 012=(SSD 0+SSD 1)/(f 0+f 1) Testet for H 2: β = 0 fuldstændig homogenitet er som er F(1, n-2) fordelt. Modelkontrol: Det skal undersøges, at for hvert k kan observarionsrækken yij, j=1, 2. . ni anses for normalfordelt
 og den reciprokke hærdningstid (")
Eksempel: Nedenstående tabel viser logaritmen til trækstyrken (kg/cm 2) og den reciprokke hærdningstid ( dage) for nogle cementstykker: dage måling nr. Træk. styrke log reciprok dag 1 1 13, 00 1, 114 1, 000 1 2 13, 30 1, 124 1, 000 1 3 11, 80 1, 072 1, 000 2 1 21, 90 1, 340 0, 500 2 2 24, 50 1, 389 0, 500 2 3 24, 70 1, 393 0, 500 3 1 29, 80 1, 474 0, 333 3 2 28, 00 1, 447 0, 333 3 3 24, 10 1, 382 0, 333 3 4 24, 20 1, 384 0, 333 3 5 26, 20 1, 418 0, 333 7 1 32, 40 1, 511 0, 143 7 2 30, 40 1, 483 0, 143 7 3 34, 50 1, 538 0, 143 7 4 33, 10 1, 520 0, 143 7 5 35, 70 1, 553 0, 143 28 1 41, 80 1, 621 0, 036 28 2 42, 60 1, 629 0, 036 28 3 40, 30 1, 605 0, 036 28 4 35, 70 1, 553 0, 036 Først en grafisk undersøgelse: 28 5 37, 30 1, 572 0, 036

Som det ses er der tale om en pæn lineær Sammenhæng. Lad yij betegne log(trækstyrke) og xi den reciprokke hærdningstid. n = 21, k = 5 0 Klik Analyze → Compare Means → One-Way Anova →

Accept af varianshomogenitet. SSD 0 Herefter skal der foretages en lineær regression. Tast Analyze → Regression → Linear og man får

SSD 0+SSD 1 Skæring med y-aksen Test for linearitet som accepteres.

Videregående regressionsanalyse : Model: Antag at Yi for i = 1 til k er uafhængige N(μi, σ2) -fordelte således at , hvor xij’erne er kendte værdier og βj’erne ukendte parametre. Dette kan formuleres med matricer: og lad Og lad betegne observationerne. være et underrum. Estimaterne bliver Ofte sættes første søjle i X til 1 -taller således, at β 1 er det generelle niveau.

Eksempel : Indianere i Peru Ændringer i menneskers livsbetingelser kan give sig udslag i fysiologiske ændringer, eksempelvis i ændret blodtryk. En gruppe antropologer undersøgte hvordan blodtrykket ændrer sig hos peruvianske indianere der flyttes fra deres oprindelige primitive samfund i de h øje Andesbjerge til den såkaldte civilisation, dvs. storbyen, der i øvrigt ligger i langt mindre højde over havets overflade end deres oprindelig bopæl (Davin (1975), her citeret e er Ryan et al. (1976)). Antropologerne udvalgte en stikprøve på 39 mænd over 21 år der havde undergået en sådan flytning. På hver af disse måltes blodtrykket (det systoliske og det diastoliske) samt en række baggrundsvariable, heriblandt alder, antal år siden flytningen, højde, vægt og puls. Desuden har man udregnet endnu en baggrundsvariabel, nemlig » brøkdel af livet levet i de nye omgivelser «, dvs. antal år siden flytning divideret med nuværende alder. Man forestillede sig at denne baggrundsvariabel kunne have stor » forklaringsevne «.
")
Her vil vi ikke se på hele talmaterialet, men kun på blodtrykket (det systoliske) der skal optræde som y-variabel, og på de to x-variable brøkdel af livet i de nye omgivelser og vægt. Disse er angivet i tabel 11. 8 (fra Ryan et al. (1976)). 1. Antropologerne mente at x 2, brøkdel levet i de nye omgivelser, var et godt mål for hvor længe personerne havde levet i de civiliserede omgivelser, og at derfor måtte være interessant at se om x 2 kunne forklare variationen i blodtrykket y. F ørste skridt kunne derfor være at estimere en simpel lineær regressionsmodel med x 2 som forklarende variabel. Gør det! 2. Hvis man i et koordinatsystem afsætter y mod x 2, viser det sig imidlertid at det faktisk ikke virker særlig rimeligt at hævde at (middelværdien af) y afhænger lineært af x 2. Derfor må man give sig til at overveje om andre af de målte baggrundsvariable med fordel kan inddrages. Nu ved man at en persons vægt har betydning for den pågældendes blodtryk, så næste modelforslag kunne være en multipel regressionsmodel med både x 2 og x 3 som forklarende variable. I SPSS indtastes dataene således: (hvis man ikke havde 1 -tallene vil SPSS give det samme) y x 1 x 2 x 3 170 1 0, 048 71, 0 120 1 0, 273 56, 5 125 1 0, 208 56, 0 148 1 0, 042 61, 0 140 1 0, 040 65, 0 Tast Analyze → Regression → Linear Osv.
 s 2 test for lig 0")
Eksempel : Indianerne i Peru ( se opgaveark) s 2 test for lig 0 Alle test for βi = 0 er signifikante.

Modelkontrol : Der laves først simple grafer over sammenhæng mellem y’erne og x 2’erne og derpå x 3’erne. Der er ikke overbevisende lineær sammenhæng. Parametrene i den multiple regression estimeres og de forventede værdier og residuerene beregnes : klik yderligere på Save og sæt flueben somvist. Sammenhænget mellem forventet og observeret er ikke overbevisende men acceptabelt. Residuerene undersøges: Det accepteres, at residuerne kan anses for normalfordelte, men det er ikke flot.
- Slides: 36