Unsupervised learning Clustering Ata Kaban The University of

Unsupervised learning: Clustering Ata Kaban The University of Birmingham http: //www. cs. bham. ac. uk/~axk
 Unsupervi sed Learning ‘Interesting structure’ (output) -Should contain essential")
The Clustering Problem Data (input) Unsupervi sed Learning ‘Interesting structure’ (output) -Should contain essential traits -discard unessential details Objective function that expresses our notion of interestingness for this data -provide a compact summary the data -interpretable for humans -…

Here is some data…






Formalising • Data points xn n=1, 2, … N • Assume K clusters • Binary indicator variables zkn associated with each data point and cluster: 1 if xn is in cluster k and 0 otherwise • Define a measure of cluster compactness as the total distance from the cluster mean:
: • Two sets of parameters")
• Cluster quality objective (the smaller the better): • Two sets of parameters - the cluster mean values mk and the cluster allocation indicator variables zkn • Minimise the above objective over each set of variables while holding one set fixed This is exactly what the K-means algorithm is doing! (can you prove it? )
 do")
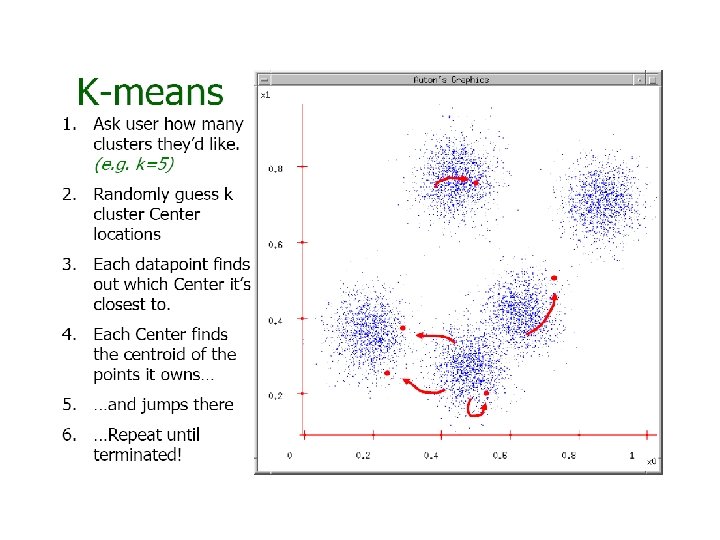
– Pseudo-code of K-means algorithm: Begin initialize 1, 2, …, K (randomly selected) do classify n samples according to nearest i recompute i until no change in i return 1, 2, …, K End




Other forms of clustering • Many times, clusters are not disjoint, but a cluster may have subclusters, in turn having subsubclusters. Hierarchical clustering

• Given any two samples x and x’, they will be grouped together at some level, and if they are grouped a level k, they remain grouped for all higher levels • Hierarchical clustering tree representation called dendrogram

• The similarity values may help to determine if the grouping are natural or forced, but if they are evenly distributed no information can be gained • Another representation is based on set, e. g. , on the Venn diagrams

• Hierarchical clustering can be divided in agglomerative and divisive. • Agglomerative (bottom up, clumping): start with n singleton cluster and form the sequence by merging clusters • Divisive (top down, splitting): start with all of the samples in one cluster and form the sequence by successively splitting clusters

Agglomerative hierarchical clustering • The procedure terminates when the specified number of cluster has been obtained, and returns the cluster as sets of points, rather than the mean or a representative vector for each cluster

Application to image segmentation

Application to clustering face images Cluster centres = face prototypes

The problem of the number of clusters • Typically, the number of clusters is known. • When it’s not, that is a hard problem called model selection. There are several ways of proceed. • A common approach is to repeat the clustering with K=1, K=2, K=3, etc.

What did we learn today? • Data clustering • K-means algorithm in detail • How K-means can get stuck and how to take care of that • The outline of Hierarchical clustering methods
- Slides: 24