UNITIV Syntax Directed Translation Semantic Analysis Sementic analysis







 • The value of an attribute of a grammar")



















: create a node labeled by")
 p 2=mkleaf(num, 4)")



+(b-c)*d • Nodes are implemented as records stored")









 is a type expression. Ex:")






 Semantic Actions")

- Slides: 59
UNIT-IV Syntax Directed Translation
Semantic Analysis • Sementic analysis judges whether the syntax structure constructed in the source program derives any meaning • Semantic Analysis computes additional information related to the meaning of the program once the syntactic structure is known. • The task of sementic analysis – Scope resolution – Type checking – Array bound checking • Sementic Error: – – – Type Mismatch Undeclared Variable Reserved identifier misuse Multiple declaration of variable Actual and formal argument mismatch Accessing out of scope variable.
Semantics • Semantics of the language provide the meaning to its constructs like token and syntax structure. • Semantics help intrepret symbols, their types and their relations with each other. • Semantic analysis judges whether syntax structure constructed in the source program provides meaning or not CFG+Semantic rules=Syntax directed Transalation (SDT)
Syntax Directed Translation • SDT is nothing but adding some information to the grammar symbols. • Information is nothing but attributes i. e value, type, code… • Values for the attributes are computed by semantic rules associated by grammar symbols. • This can be done by two notations: – Syntax directed Definition – Translation Rules
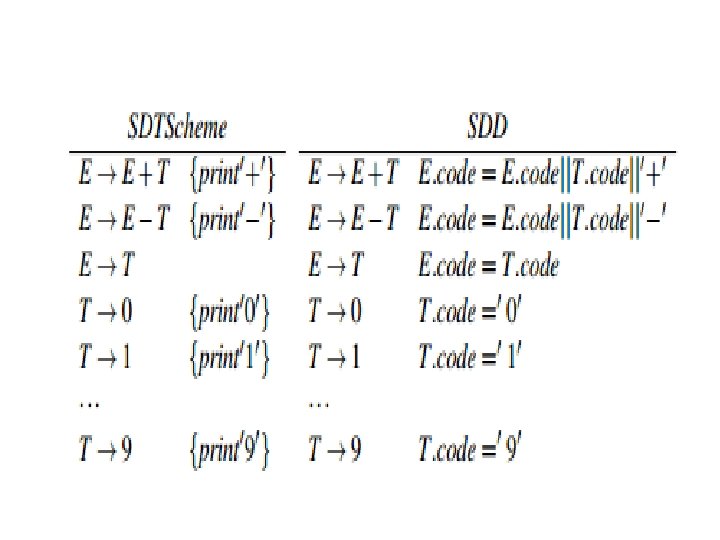
Syntax Directed Translation schemes • Translation scheme indicates the order in which the semantic rules are to be evaluated. E E+ T {Print(+)}; Syntax Directed Definition: • A syntax-directed definition (SDD) is a contextfree grammar with attributes attached to grammar symbols and semantic rules attached to the productions. • The semantic rules define values for attributes associated with the symbols of the productions. • SDDs are useful for specifying translations.
• In both scheme – We parse the input token – creating a parse tree for the input – sequence of passes over the parse tree – evaluating some or all of the rules on each pass.
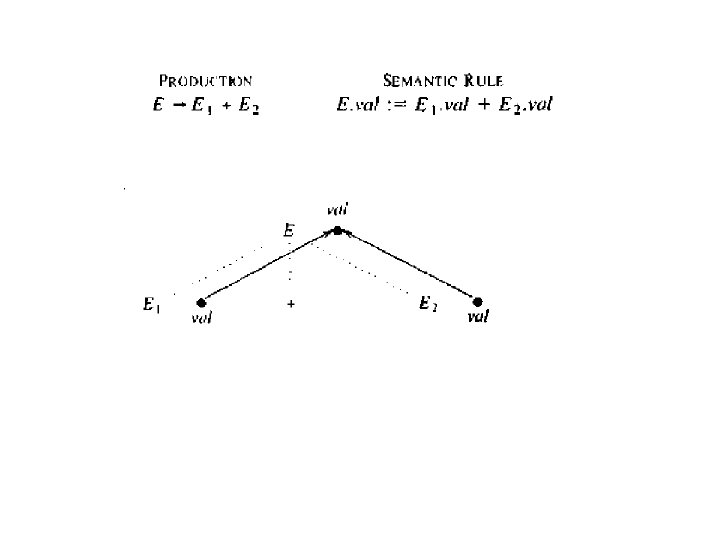
Example Attributes: E E. Code : It represents the code for the expression E. val: It represents the value for the expression Production Semantic Rules E E+ T E. val : = E 1. val + T. val
Syntax Directed Definitions (Cont. ) • The value of an attribute of a grammar symbol at a given parse-tree node is defined by a semantic rule associated with the production used at that node. We distinguish between two kinds of attributes: 1. Synthesized Attributes. They are computed from the values of the attributes of the children nodes. 2. Inherited Attributes. They are computed from the values of the attributes of both the siblings and the parent nodes.
• A Parse tree showing the values of the attributes at each node is called annotated parse tree. • The process of computing the attribute values at the nodes is called annotating or decorating the parse tree.
Form of Syntax Directed Definitions Each production, A ᾳ , is associated with a set of semantic rules of the form b : = f(c 1, c 2, …ck), where f is a function and either 1. b is a synthesized attribute of A, and c 1, c 2, …ck are attributes of the grammar symbols of the production, or 2. b is an inherited attribute of a grammar symbol in, and c 1, c 2, …ck are attributes of grammar symbols in or attributes of A.
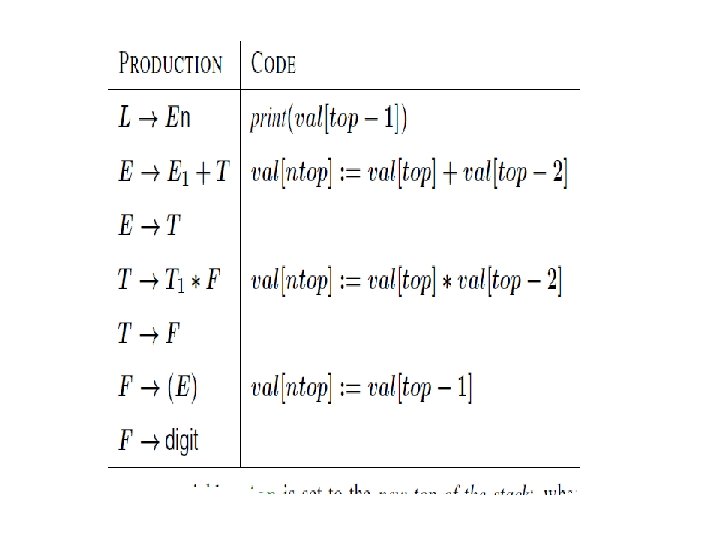
Syntax Directed Definitions: An Example. Let us consider the Grammar for arithmetic expressions. The Syntax Directed Definition associates to each non terminal a synthesized attribute called val. PRODUCTION SEMANTIC RULE L En print(E. val) E E 1 + T E. val : = E 1. val + T. val E T E. val : = T. val T T 1 *F T. val : = T 1. val F. val T F T. val : = F. val F (E) F. val : = E. val F digit F. val : =digit. lexval
S-Attributed Definitions • Definition. An S-Attributed Definition is a Syntax Directed Definition that uses only synthesized attributes. • Evaluation Order. Semantic rules in a SAttributed Definition can be evaluated by a bottom-up, or Post. Order, traversal of the parse-tree.
Example. The above arithmetic grammar is an example of an S-Attributed Definition. The annotated parse-tree for the input 3*5+4 n is:
Inherited Attributes • An inherited attribute is one whose value of the node in a parse tree is defined in terms of attributes at the parent or the siblings of the node. • Inherited Attributes are useful for expressing the dependence of a construct on the context in which it appears. • For eg: inherited attributes to keep track of whether an identifier appears on the left or right side of an assignment in order to decide whether the address or the value is needed
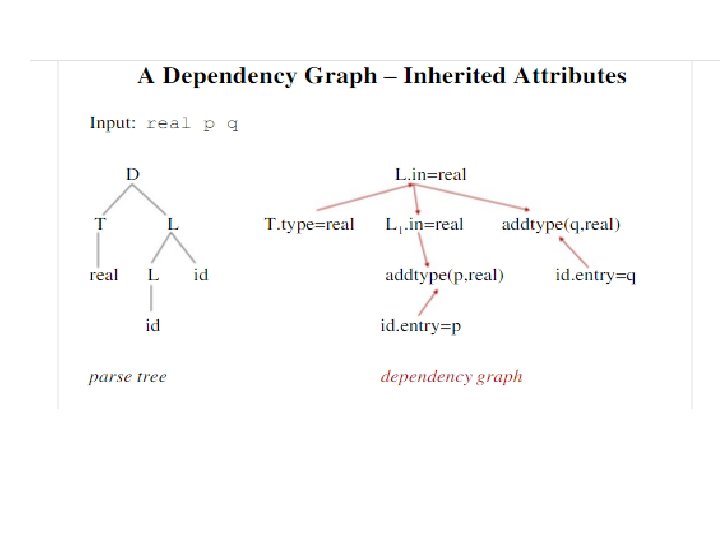
Example. Let us consider the syntax directed definition with both inherited and synthesized attributes for the grammar for “type declarations”
• The non terminal T has a synthesized attribute, type, determined by the tokens int/real in the corresponding production. • The production. D T L is associated with the semantic rule L: in : = T: type which set the inherited attribute L: in.
Dependency Graph • The interdependency among the synthesized and inherited attributes at the node in the parse tree is depicted by the directed graph called as dependency graph. • Example: – If an attribute b at a node in a parse tree depends on the attribute c, then the semantic rule for b in that node must be evaluated after the semantic rule that define c. (b c) • Dependency Rule: If an attribute b depends from an attribute c, then we need to fire the semantic rule for c first and then the semantic rule for b.
Before constructing the dependency graph for a parse tree, we put each sementic rule into the form of b: =f(c 1, c 2…ck), by introducing the dummy synthesized variable b for each semantic rule that consists of procedure call. Example: A XY A. a=f(X. x, Y. y) is a semantic rule The rule defines the synthesized attributes A. a that depends on the attributes X. x and Y. y. There will the three node A. a, X. x and Y. y in the dependency graph with an edge to A. a from X. x(since A. a depends on X. x) and edge to A. a from Y. y(since A. a is depends on Y. y)
Dependency Graph-synthesized attribute
Evaluation Order • The evaluation order of semantic rules depends from a Topological Sort derived from the dependency graph. • Topological Sort: Any orderingm 1, m 2, …mk such that if mi mj is a link in the dependency graph then mi < mj. • Any topological sort of a dependency graph gives a valid order to evaluate the semantic rules.
• Attributes can be evaluated by building a dependency graph at compile-time and then finding a topological sort. Disavantages 1. This method fails if the dependency graph has a cycle: We need a test for non-circularity; 2. This method is time consuming due to the construction of the dependency graph.
Evaluation Order • Methods for evaluating the semantic rule: – Parse tree methods: At compile time , these methods obtain an evaluation order from the topologic sort of the dependency graph constructed from the parse tree for each input. These method will fail to find an evaluation order only if the dependency graph for the particular parse tree under consideration has a cycle.
– Rule Based Method: • At compiler construction time, the semantic rule associated with production are analyzed, either by hand, or by a specialized tool. • For each production, the order in which the attributes associated with the production are evaluated in predetermined at compiler construction time. – Oblivious Method: • A evaluation order is chosen without considering the semantic rules. • It restricts the class of SDT that can be implemented.
Construction of Syntax Tree • We can represent intermediate language in syntax tree that allows translation to be decoupled from parsing. • Translation routine that are invoked during parsing must live with two kinds of restriction. – First a grammar is suitable for parsing may not reflect the natural hierarchical structure of the construct in the language. – Second the parsing method constraints the order in which nodes in the parse tree are considered
Syntax tree • An syntax tree is the condensed form of parse tree that is useful for Language Constructs. • In syntax tree operator and keywords does not appear in the Leaves, but rather are associated with the interior node that would be the parent of those leaves in the Parse tree
Constructing syntax tree for Expression • Similar to translation of post fix notation • Creating node for operator and operand • The children of the operator node are the root of the node representing the sub expression constituting the operators and operands. • Each node in the syntax tree is represented as records – Operator – Pointer to the node of the operands
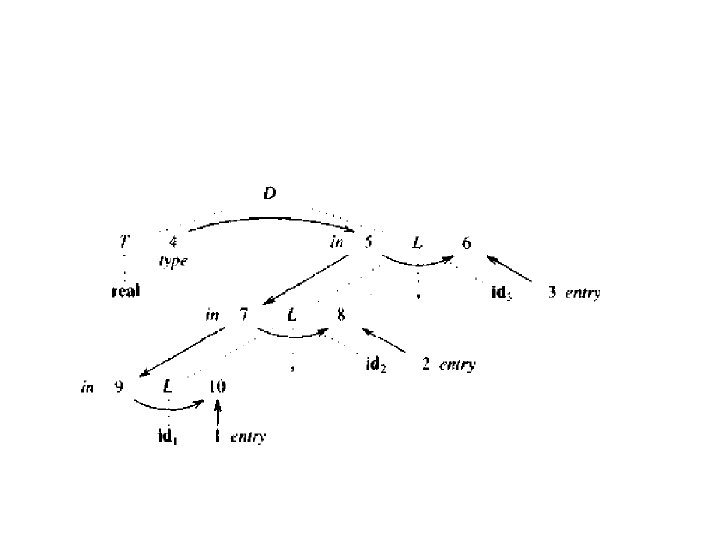
Node creation in syntax tree – mknode(op, left, right): create a node labeled by op and two fields containing left and right – mkleaf(id, entry): create a node labeled by op and field containing the entry for symbol table. – mkleaf(num, leaf): create a node labeled by num and a field containing val, the val of the num. – mkunode(op, left): create a unary node labelled by op and one field containing the operands.
Create a syntax tree for the expression a-4+c. P 1=mkleaf(a, entrya) p 2=mkleaf(num, 4) P 3=mknode(-, p 1, p 2) P 4=mkleaf(c, entryc) P 5=mknode(+p 3, p 4)
SDT for Constructing Syntax Tree
Annotated Parse tree
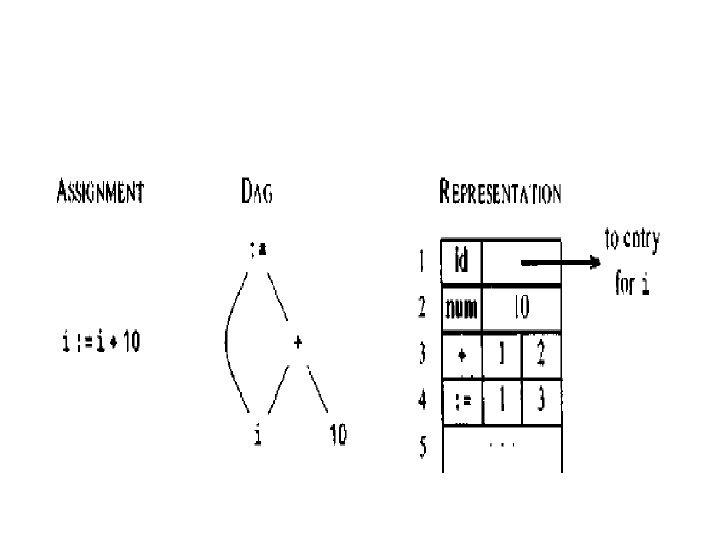
DAG for Expression • It identifies the Common sub expression. • It contains the node for every sub expression of the expression. • Interior node represents the operator • Children represents the Operand • The main difference is node in a DAG representing the Common sub expression has more than on parent.
• DAG for the Expression a+a*(b-c)+(b-c)*d • Nodes are implemented as records stored in an Array • Each record has the Label field that determines the nature of the node • We can refer the node by its index or position in the array • The integer index of a node is often called as value number.
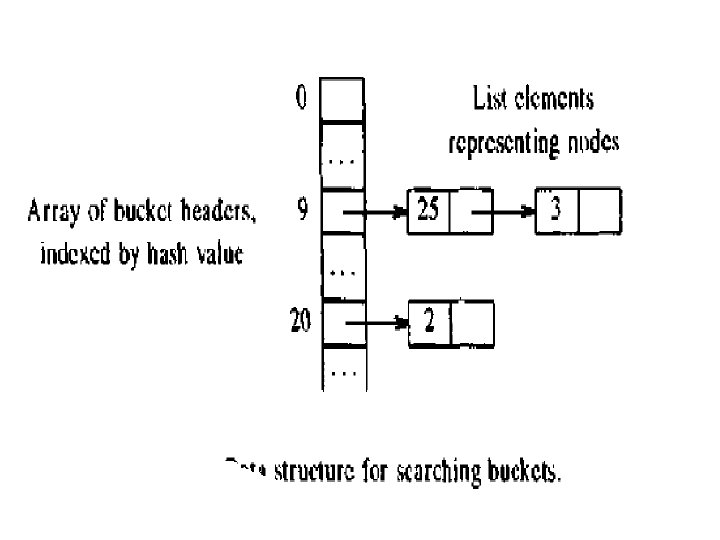
Value number method • Algorithm: – Search the array for a node m with label op, left l, right r. if there is such a node , return m; – otherwise, create a new node n with label op, right r, left land return n. – An obvious way to identified the node in a array can be efficiently done by k lists called as buckets and using the hash function h to determine which bucket to search.
• The hash function computes the number of a bucket from the value of op, left, right. It will always return the same bucket number when same argument is passed. • If the node m is not in the bucket, then new node is created and added to the bucket.
Bottom Up Evaluation of S-Attribute Definitions • S-Attribute refer to synthesized Attributes • Synthesized Attribute are evaluated by bottom up parser as input is being parsed • Parser can keep track the values of synthesized attributes associated with grammar symbol on its stack. • When ever the reduction is made, the values of the synthesized attributes are computed from the attributes appearing on the stack for the grammar symbols on the right side of the reducing production.
Synthesized attributes on the parser stack • Implemented with a help of LR parser generator. • The parser generator can construct a translator that evaluates attributes as it parses the input. • A bottom parser using the stack to hold the symbols. • Parser stack is used to hold extra information of synthesized attributes. • In the simple case of just one attribute per grammar symbol the stack has two fields: state and val • The current top of the stack is indicated by the pointer variable top. • Synthesized attributes are computed just before each reduction: • Before the reduction A XY Z is made, the attribute for A is • computed: A: a : = f(val[top], val[top -1], val[top -2]).
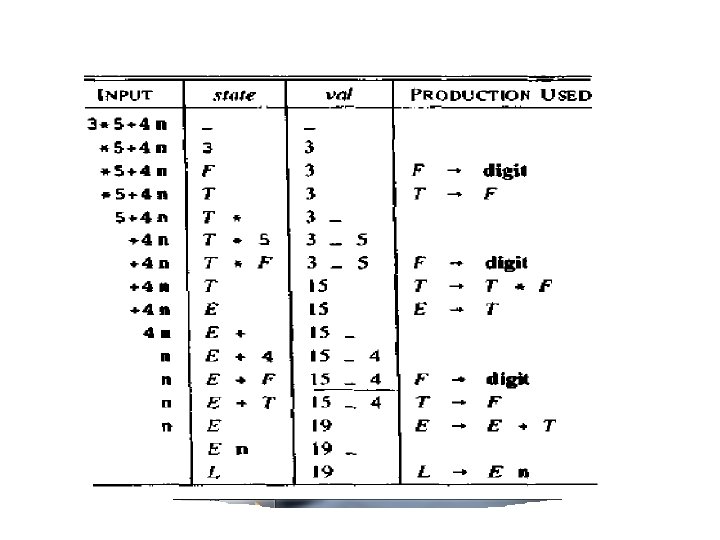
Input Stack Val Production Used Action id*id+id$ 3*5+4 n 0 - - - Shift *id+id$ Id+id$ *5+4 n +4 n 0 id 5 0 F 3 0 T 2*7 id 5 3 F T T* T*5 3 3_ 3_5 +id$ +4 n 0 T 2*7 F 10 T*F 3_5 F digit Reduce. T F +id$ $ $ +4 n n n 0 T 2 0 E 1+6 id 5 T E E+ E+4 15 15 15_4 T T*F E T Reduct E T Reduce F T Shift $ n 0 E 1+6 F 3 E+F 15_4 F digit Reduct F id $ n 0 E 1+6 T 9 E+T 15_4 T F Reduce T F 0 E 1 E 19 E E+T Reduce E E+T En L 19_ 19 $ F digit T F Reduct F id Reduce F T Shift Reduct F id accept L E n
Type Checking Compiler must check that the source program follows both the syntactic and semantic conventions of the source language. Static checks - reported during the compilation phase. Dynamic checks - occur during the execution of the program. Examples of Static Checks: Type checks: A compiler should report an error if an operator is applied to an incompatible operand. Flow of control checks: Places for flow of control should be specified. Uniqueness checks: An object must be defined exactly (like the type of an identifier, statements inside a case/switch statement. ) Name Related checks: Same name must appear two or more times. (a loop or Block may have a name appear at beginning and end of the construct.
• A Type Checker verifies that the type of a construct matches that expected by context. • Type information gathered by a type checker may be needed when code is generated. • The design of a type checker for a language is based on the information about the – Syntactic constructs in the language. – Notion of Types – Rules for assigning type to language construct.
• Type Expression – The type of a language construct is denoted by a type expression. • A type expression can be: – A basic type • a primitive data type such as integer, real, char, boolean, … • type-error to signal a type error • void : no type – A type name • a name can be used to denote a type expression.
A type constructor applies to other type expressions. • arrays: If T is a type expression, then array(I, T) is a type expression where I denotes index range. Ex: array(0. . 99, int) • products: If T 1 and T 2 are type expressions, then their cartesian product T 1 x T 2 is a type expression. Ex: int x int • Records. The difference between a record and a product is that the fields of a record have names. The record type constructor will be applied to a tuple formed from field names and field types For example, the Pascal program fragment type row = record address: integer; lexeme: array [1… 15] of char end; var table: array [1…. 101] of row; declares the type name row representing the type expression record ((address integer) (lexeme array (1… 15, char))) and the variable to be an array of records of this type.
pointers: If T is a type expression, then pointer(T) is a type expression. Ex: pointer(int) functions: We may treat functions in a programming language as mapping from a domain type D to a range type R. So, the type of a function can be denoted by the type expression D→R where D are R type expressions. Ex: int→int represents the type of a function which takes an int value as parameter, and its return type is also int.
• Sound type Systems: – A sound type system eliminates the need for dynamic checking for type errors. A language is strongly typed if its compiler can guarantee that the programs it accepts will execute without type errors. – E. g. array bound checking. • Error Recovery: – Since type checking has the potential for catching errors in the programs, it is important for a type checker to do something reasonable when an error is discovered. At the very least, the compiler must report the nature and location of the error. It is desirable for the type checker to recover from the errors, so it can check the rest of the input. Since error handling affects the type checking rules, it has to be designed into the system right from the start; the rules must be prepared to cope with errors
Specification of Simple Type Checker – The type checker for the a simple language in which the type of each identifier must be declared before the identifier is used. – The type checker is the translation scheme that synthesis the form of each expression for the type of its sub expression. – The translation scheme that save the type of the identifier.
• A Simple Language: P → D; E D → D; D|id: T T → char |int|real| ↑T 1|array[num] of T 1 E → id|literal| E 1 + E 2|E 1 [E 2]|E 1 ↑ A Grammar for Source Language
Translation Scheme for that saves the type of an identifier. Production Semantic Actions P → D; E D → D; D D → id: T { addtype(id. entry, T. type) } T → char { T. type=char } T → int { T. type=int } T → real { T. type=real } T → ↑T 1 { T. type=pointer(T 1. type) } T → array[intnum] of T 1 {T. type=array(1. . intnum. val, T 1. type) }
Type Checking of Expressions Production E → id E → char literal E → int literal E → real literal E → E 1 + E 2 E → E 1 [E 2] E → E 1 ↑ Semantic Actions { E. type=lookup(id. entry) } { E. type=char } { E. type=int } { E. type=real } { if (E 1. type=int and E 2. type=int) then E. type=int else if (E 1. type=int and E 2. type=real) then E. type=real else if (E 1. type=real and E 2. type=int) then E. type=real else if (E 1. type=real and E 2. type=real) then E. type=real else. E. type=type-error } { if (E 2. type=int and E 1. type=array(s, t)) then E. type=t else. E. type=type-error } { if (E 1. type=pointer(t)) then E. type=t else E. type=type-error }
Type Checking of Statements Production Actions S id = E Semantic { if (id. type=E. type then S. type=void else S. type=type-error } S if E then S 1 { if (E. type=boolean then S. type=S 1. type else S. type=type-error } S while E do S 1 { if (E. type=boolean then S. type=S 1. type else. S. type=type-error }
Type Checking of Functions Production E E 1 ( E 2 ) Semantic Actions { if (E 2. type=s and E 1. type=s t) then E. type=t else E. type=type-error } Ex: int add (double x, char y) {. . . } add: double x char int argument types return type
Type Conversion • Explicit type Conversion: – The programmer is responsible for conversion, they have to write code for the conversion – Like function application • Implicit Type Conversion: – it can be done automatically by compiler. – The role of type checker is to detect that the two types are different and to insert the appropirate cost.