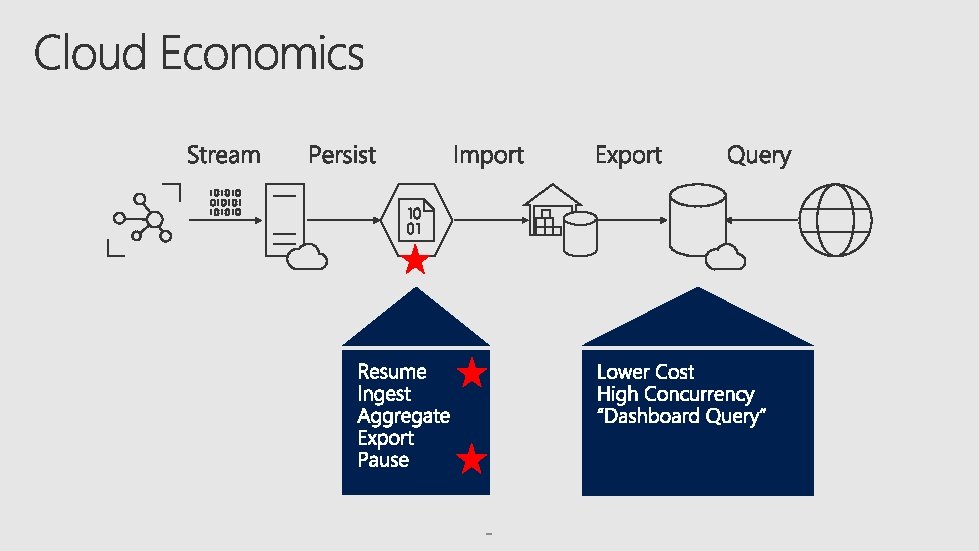
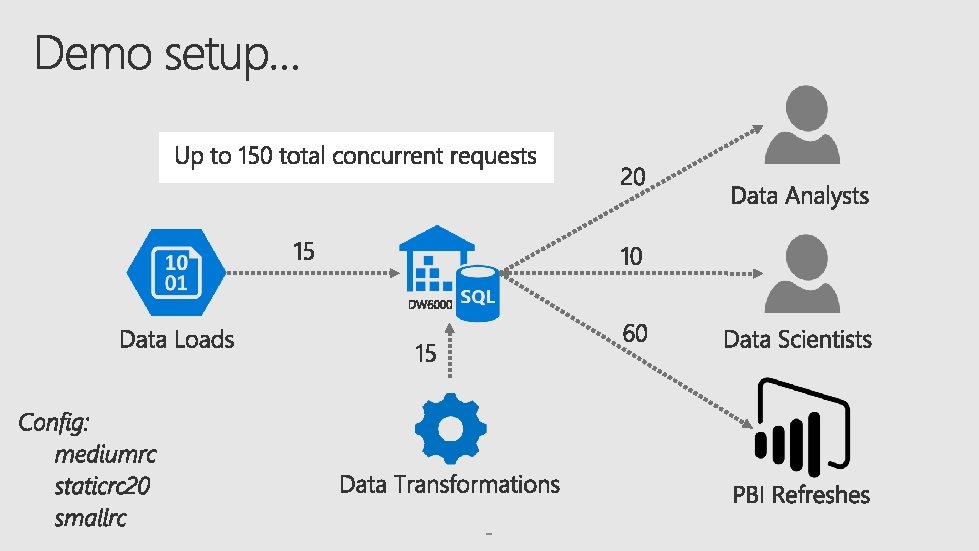
Understanding the Azure portfolio for Big Data Advanced


Understanding the Azure portfolio for Big Data & Advanced Analytics

AZURE DATA FACTORY AZURE IMPORT EXPORT SERVICE AZURE CLI AZURE SDK AZURE SQL DB AZURE STORAGE AZURE DATA LAKE STORE BLOBS AZURE IOT HUB AZURE ANALYSIS SERVICES AZURE SQL DATA WAREHOUSE AZURE COSMOS DB AZURE HDINSIGHT AZURE DATA LAKE AZURE (HADOOP / SPARK) HDINSIGHT ANALYTICS DATABRICKS POWER BI AZURE ML SERVER AZURE ML DATABRICKS AZURE EVENT HUBS AZURE SEARCH KAFKA ON AZURE HDINSIGHT AZURE EXPRESSROUTE AZURE ACTIVE DIRECTORY AZURE DATA CATALOG AZURE NETWORK SECURITY GROUPS AZURE STORM AND SPARK STREAMING DATABRICKS HDINSIGHT STREAM ANALYTICS ON AZURE HDINSIGHT AZURE KEY MANAGEMENT SERVICE OPERATIONS MANAGEMENT SUITE BOT SERVICE COGNITIVE SERVICES AZURE FUNCTIONS VISUAL STUDIO

BIG AZURE DATA FACTORY AZURE IMPORT EXPORT SERVICE AZURE CLI AZURE SDK AZURE SQL DB AZURE STORAGE AZURE DATA LAKE STORE BLOBS AZURE IOT HUB AZURE ANALYSIS SERVICES AZURE SQL DATA WAREHOUSE AZURE COSMOS DB AZURE DATA LAKE ANALYTICS AZURE HDINSIGHT AZURE STREAM ANALYTICS AZURE HDINSIGHT AZURE DATABRICKS AZURE ML ML SERVER POWER BI AZURE DATABRICKS AZURE EVENT HUBS AZURE SEARCH KAFKA ON AZURE HDINSIGHT AZURE EXPRESSROUTE AZURE ACTIVE DIRECTORY AZURE DATA CATALOG AZURE NETWORK SECURITY GROUPS AZURE KEY MANAGEMENT SERVICE AZURE DATABRICKS OPERATIONS MANAGEMENT SUITE BOT SERVICE COGNITIVE SERVICES AZURE FUNCTIONS VISUAL STUDIO

Unrivaled power Unlimited scale Fast time to value Up to 10 x more query performance than traditional storage Independent and limitless scaling of storage and compute Seamless integration with Microsoft and 3 rd party services Trusted & reliable Enhanced security with encryption, audit, VNET and leading compliance

BUSINESS APPS DATA MIGRATION SERVICE CUSTOM APPS DATA MIGRATION SERVICE AZURE SQL DATABASE CUSTOM APPS AZURE SQL DATA WAREHOUSE AZURE ANALYSIS SERVICES ANALYTICAL DASHBOARDS

BUSINESS APPS AZURE CLI, AZURE DATA FACTORY ANALYTICAL DASHBOARDS CUSTOM APPS DATA MIGRATION SERVICE AZURE SQL DATA WAREHOUSE AZURE ANALYSIS SERVICES ANALYTICAL DASHBOARDS

DATA FACTORY BUSINESS APPS AZURE STORAGE ANALYTICAL DASHBOARDS Polybase CUSTOM APPS ANALYTICAL DASHBOARDS DATA FACTORY AZURE SQL DATA WAREHOUSE

AZURE ML & ML SERVER BUSINESS APPS AZURE DATABRICKS (Spark Mllib, Spark. R, Sparkly. R) DATA FACTORY AZURE COSMOS DB WEB & MOBILE APPS AZURE DATABRICKS (Spark) AZURE STORAGE ANALYTICAL DASHBOARDS Polybase CUSTOM APPS DATA FACTORY AZURE SQL DATA WAREHOUSE ANALYTICAL DASHBOARDS

HYBRID DATA INTEGRATION AT SCALE, MADE EASY Visual drag-&-drop UI SSIS in cloud Code-free Data movement Hybrid Data Integration Get pipelines up & running quickly without requiring to write a single line of code Gain scale and cost savings by executing your SSIS packages in cloud Improve your TCO with 60+ natively supported connectors across Azure, AWS, GCP and many more Orchestrate your data pipeline wherever your data lives


Compute $$$ Storage

Control Compute Remote Storage

Control Compute Remote Storage


Control Compute Remote Storage


Remote Storage Compute Control Cores Memory SSD Temp. DB Cores Memory Cores SSD Temp. DB Memory SSD Temp. DB Snapshot backups Data Log


Control Compute Remote Storage Intelligent Cache

Control Cores SSD Temp. DB Compute Cores Remote storage Memory Cores NVMe SSD Cache Memory Cores NVMe SSD Temp. DB Cache Snapshot backups Memory NVMe SSD Temp. DB Cache Data Log Temp. DB

Memory Cache ∞ Remote Storage

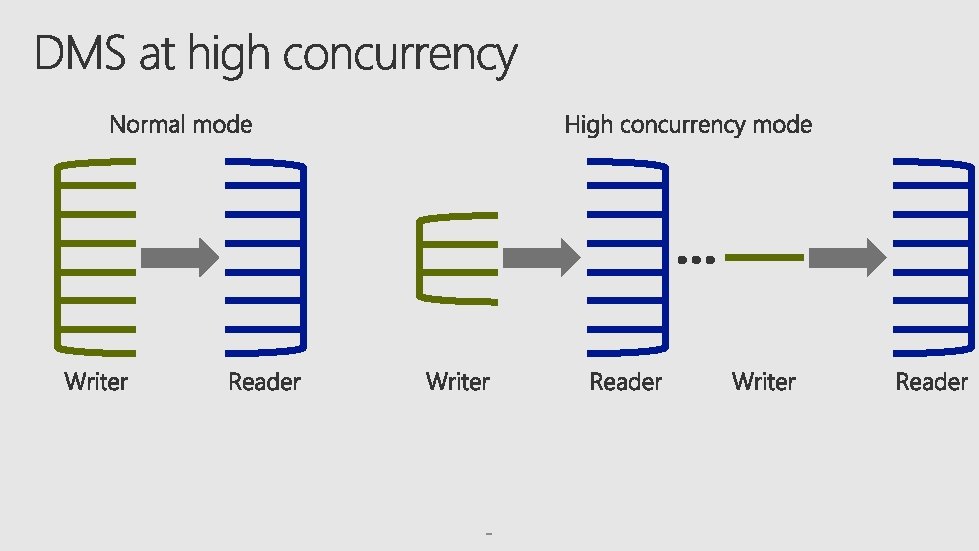
32 KB Receive Workers Send 32 KB Hash_Reader 32 KB Data Query Buffers Q Q Direct_Reader Parallel_Copy_Reader 32 KB Step 1. Execute query & receive buffers 32 KB Step 2. DMS Reader pulls buffer & processes Writer Step 3. Sender ships new buffer to target node Receive Workers 32 KB Hash_Reader Data Query Buffers Q Direct_Reader Parallel_Copy_Reader 32 KB Writer Step 4. Writer bulk loads data into target table Send Q 32 KB

Distributed. Exchange. Operation<Shuffle. Move. Operation> sys. dm_pdw_nodes_distributed_exchange_stats

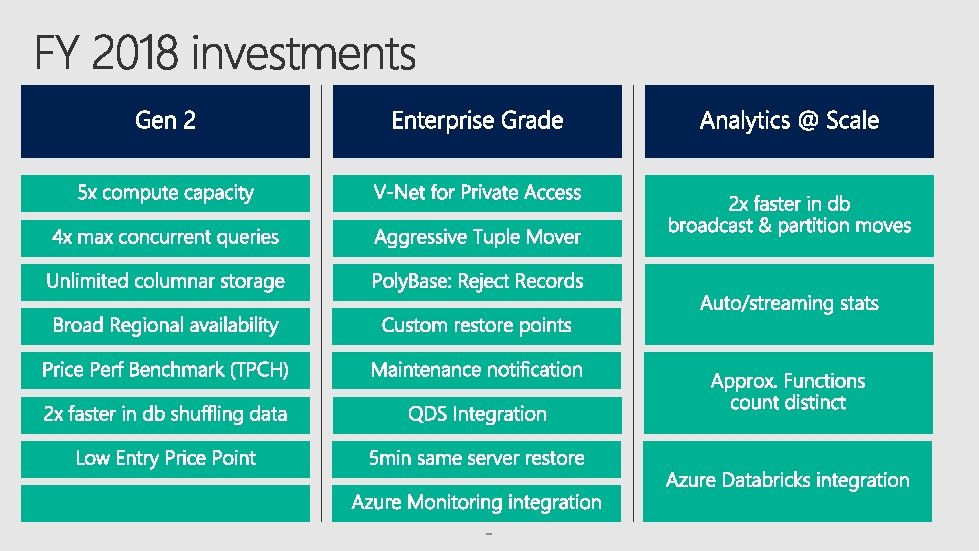
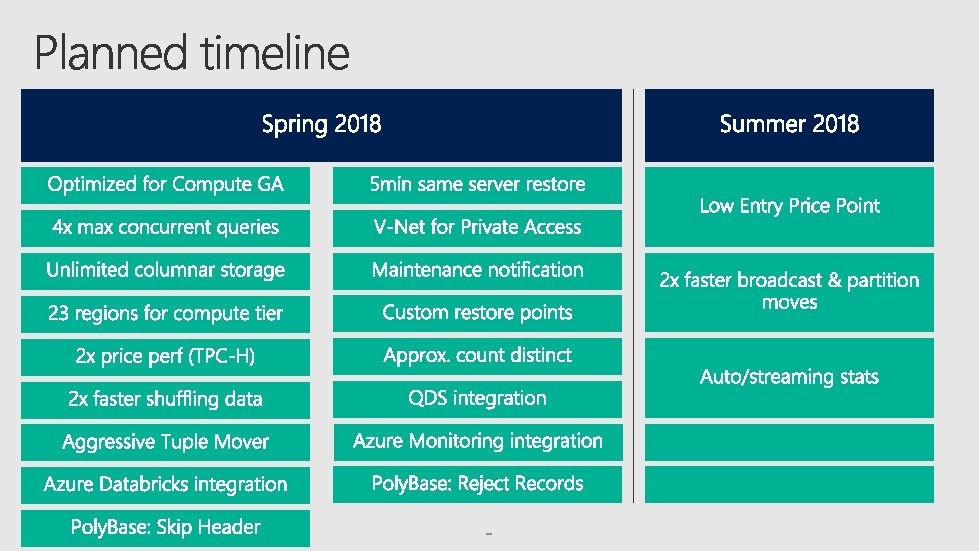
Latest hardware Hashed data maintained on the compute nodes

Generation 2 100 x improvement in performance Up to 100 x improvement for individual queries observed in customer workloads 2 x price performance across workloads 5 x scalability More flexibility provided with additional resources Retains all elastic functionality Scale measured in Compute Data Warehouse Units (DWU)




1024 open sessions QID QID 128* QID active queries *Spring 2018 QID QID


Concurrency Slots Queries Future Query Limit 60 00 c 50 00 c c 30 00 0 c DW c 00 0 15 DW 00 0 10 DW 75 00 c DW DW DW 30 00 DW 25 00 c 20 00 c 15 00 c 64 DW DW DW 00 12 10 00 c DW DW 60 0 DW 50 0 DW 40 0 DW 30 0 DW 20 0 DW 1024 1200 256 128 48 64 16 4 1




Medium. Rc Total Qs Slots/Q DW 100 4 4 1 DW 3000 7 120 16 DW 6000 7 240 32 20 16 12 8 4 0 mediumrc largerc xlargerc DW 100 DW 200 DW 300 DW 400 DW 500 DW 600 DW 1000 c DW 1200 DW 1500 DW 2000 c DW 2500 c DW 3000 DW 5000 c DW 6000 c DW 7500 c DW 10000 c DW 15000 c DW 30000 c

Static. Rc 20 Total Qs Slots/Q DW 100 2 4 2 DW 3000 64 120 2 DW 6000 120 240 2 140 120 100 80 60 40 20 0 staticrc 10 staticrc 20 staticrc 30 staticrc 40 staticrc 50 staticrc 60 staticrc 70 staticrc 80 DW 100 DW 200 DW 300 DW 400 DW 500 DW 600 DW 1000 c DW 1200 DW 1500 DW 2000 c DW 2500 c DW 3000 DW 5000 c DW 6000 c DW 7500 c DW 10000 c DW 15000 c DW 30000 c

-- Pre-req CREATE USER elt_loader FOR LOGIN elt_loader ; -- Add user to static rc EXEC sp_addrolemember 'staticrc 20’, ’elt_loader' ; -- Remove user from static rc EXEC sp_droprolemember 'staticrc 20’, ’elt_loader' ;

Msg 35386, Level 16, State 1, Line 2 Could not get the memory grant of ###### KB for columnstore compression because it exceeds the maximum configuration limit of ##### KB in the current workload group and resource pool. Please rerun query at a higher resource class, and also consider increasing DWU size. See 'https: //aka. ms/sqldw_columnstore_memory' for assistance. “It’s a POC, run with xlargerc…” . . . Scale from DW 3000 to DW 6000 to run more mediumrc queries in parallel. . .
![-- Queued on concurrency select * , [queued_sec] = datediff(ms, request_time, getdate())/1000. 0 from](http://slidetodoc.com/presentation_image_h/d46733af7f0ea47105cf986a74a7d3fc/image-45.jpg "-- Queued on concurrency select * , [queued_sec] = datediff(ms, request_time, getdate())/1000. 0 from")
-- Queued on concurrency select * , [queued_sec] = datediff(ms, request_time, getdate())/1000. 0 from [sys]. [dm_pdw_resource_waits] where [state] ='Queued' order by [queued_sec] desc -- Total running queries and slots consumed select Running. Queries = sum(case when r. [status]='Running' then 1 else 0 end) , Slots. Granted = sum(case when r. [status]='Running' then rw. concurrency_slots_used else 0 end) , Queued. Queries = sum(case when r. [status]='Suspended' then 1 else 0 end) , Slots. Queued = sum(case when rw. [state] ='Queued' then rw. concurrency_slots_used else 0 end) from sys. dm_pdw_exec_requests r join sys. dm_pdw_resource_waits rw on rw. request_id = r. request_id where ((r. [status] = 'Running' and r. resource_class is not null ) or r. [status] ='Suspended') and rw. [type] ='User. Concurrency. Resource. Type'

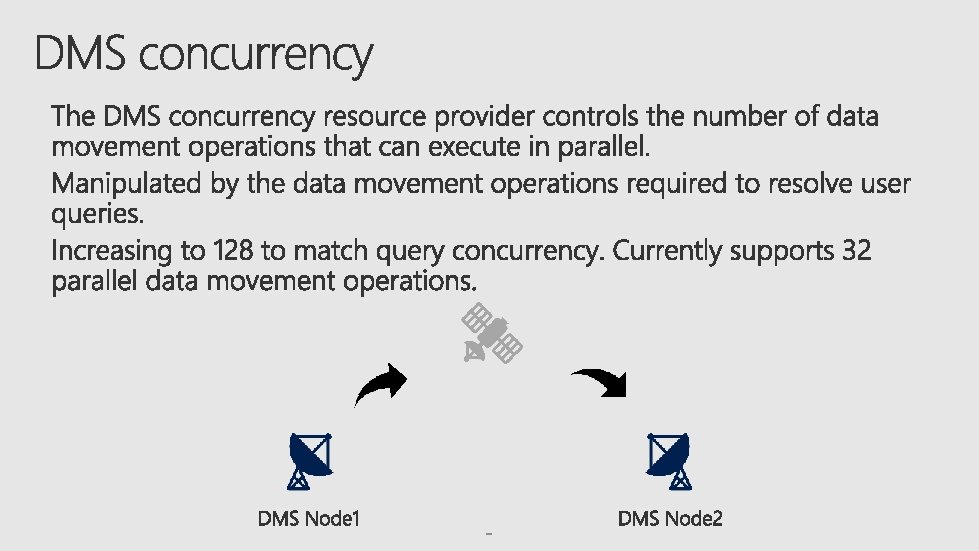
 SQL DW governs concurrency in two ways: User")
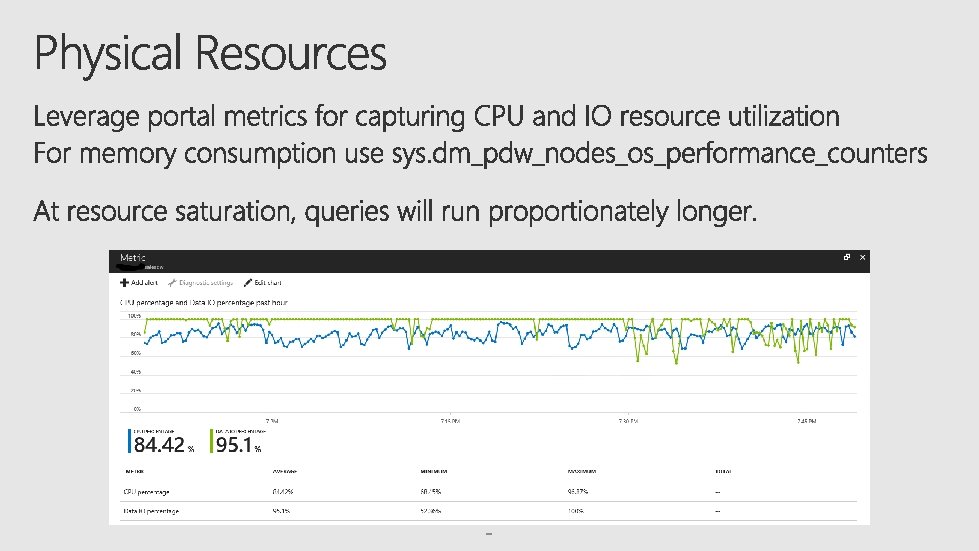
Physical Resources (CPU, Memory, Disk, Network) SQL DW governs concurrency in two ways: User query thresholds Concurrent query caps and concurrency slots limits Resource Classes (Dynamic, Static)

Control Engine DMS SQL DB Compute Compute DMS DMS DMS SQL DB SQL DB Dist_DB_1 Dist_DB_2 Dist_DB_13 Dist_DB_14 Dist_DB_25 Dist_DB_26 Dist_DB_37 Dist_DB_38 Dist_DB_49 Dist_DB_50 … … … Dist_DB_12 Dist_DB_24 Dist_DB_36 Dist_DB_48 Dist_DB_60

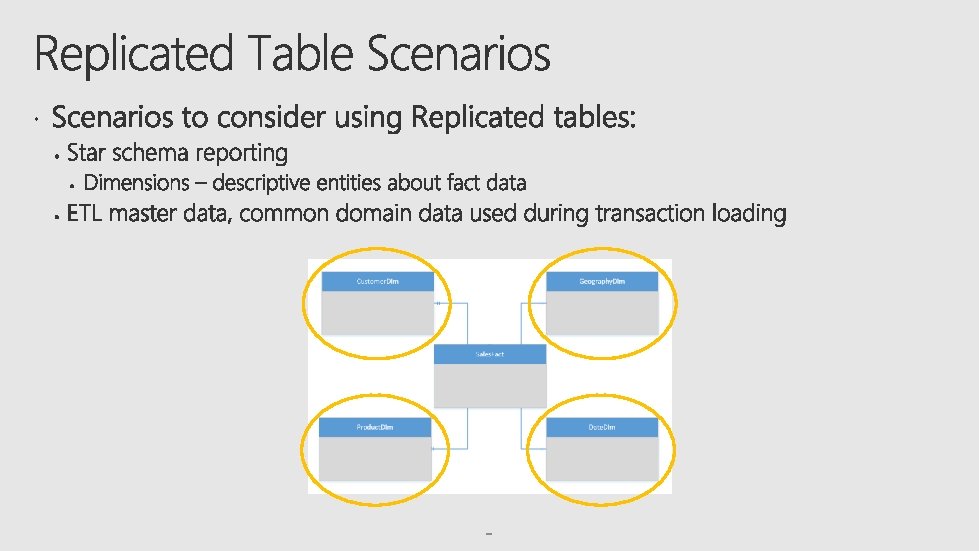
Data divided across nodes based on hashing algorithm Data distributed evenly across nodes Data repeated on every compute node Same value will always hash to same distribution Option for large tables without a good hash column Simplifies many query plans and reduces data movement Optimal for large fact tables Good starting option Best for small lookup tables Data skew can be an issue when distributing on high frequency values which represent a large percentage of rows (e. g. NULL) Will incur more data movement at query time. Consumes more space Not suitable for frequently modified data


DMS Operation Description Shuffle. Move. Operation Distribution Hash algorithm New distribution Changing the distribution column in preparation for join. Broadcast. Move. Operation Distribution Copy to all distributions Changes distributed table to replicated table for join. Partition. Move. Operation Distribution Control Node Aggregations - count(*) is count on nodes, sum of count Trim. Move. Operation Replicated table Hash algorithm Distribution When a replicated table needs to become distributed. Needed for outer joins. Move. Operation Control Node Copy to all distributions Data moved from Control Node back to Compute Nodes resulting in a replicated table for further processing. Round. Robin. Move. Operation Source Round robin algorithm Distribution Redistributes data to Round Robin Table.

Hash Repl RR Broadcast Table



Load everything ROUND_ROBIN. . . for now 12 -way joins, self joins. . . all distribution incompatible or ROUND_ROBIN Different data types on HASH distributed columns


CREATE TABLE dbo. Dim. Customer ( Customer. Key int , Geography. Key int , Customer. Alternate. Key nvarchar(15) , Title nvarchar(8) , First. Name nvarchar(50) , Last. Name nvarchar(50) , Birth. Date date , Gender nvarchar(1) , Email. Address nvarchar(50) , Yearly. Income money , Date. First. Purchase date ) WITH ( CLUSTERED COLUMNSTORE INDEX , DISTRIBUTION = REPLICATED ) NOT NULL NULL NULL

Compute Node 1 RR Table Cache Build Request RR Table Distribution_2 Distribution_3 Distribution_4 Repl Table Distribution_1 Compute Node 2 UPDATE CREATE SELECT RR Table Distribution_6 Distribution_7 Distribution_8 Repl Table Distribution_5 Replication Cache Manager
- Slides: 61